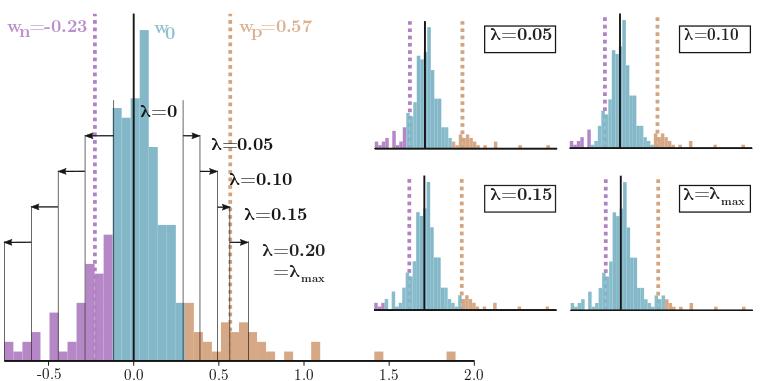
The aim of this project was to design a general framework which generates efficient convolutional neural networks (CNNs) that solve given image classification tasks to a specified quality level. We propose a two-step paradigm: 1) utilizing model compound scaling to extend a baseline model until the specified accuracy is reached; 2) applying Entropy-Constrained Trained Ternarization (EC2T) to compress the upscaled model by simultaneously quantizing the network parameters to 2 bit (ternarization) and introducing a high level of sparsity due to an entropy constraint.
Following this approach, we rendered efficient models that solve the CIFAR-100 and ImageNet classification tasks to
specified classification accuracies of 80% and 75%. We submitted these results to the MicroNet challenge held at
NeurIPS conference in December 2019, and ranked among the top 5 and top 10 entries, respectively. In order to score our
networks for the challenge, we developed an extensive scoring script which calculates the effective number of parameters
and mathematical operations. The script was verified by the challenge's hosts.
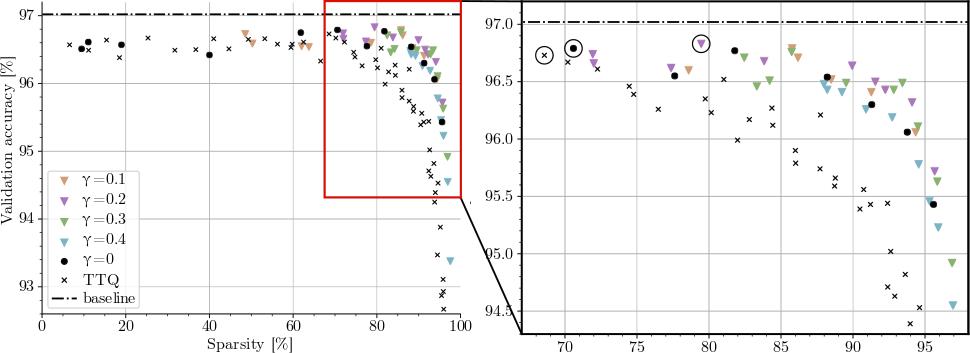
Beyond the MicroNet challenge we further investigated our approach in ablation studies and improved the algorithm itself. We compared our method to the standard in ternary quantization, Trained Ternary Quantization (TTQ), and clearly outlined the benefits of EC2T. Utilizing the improved algorithm, compressed matrix formats and a tree adder for efficient accumulation, we significantly enhanced the previous scores. In another experiment we compressed the well-known ResNet-18 and ResNet-20 networks to compare accuracy degradations due to EC2T with other ternary quantization methods. We concluded that EC2T outperforms related works while producing more efficient networks, as the algorithm explicitly boosts sparsity.
The method is explained in detail in my masterthesis (draft).
You may also want to read the arXiv.org preprint: https://arxiv.org/abs/2004.01077
If you find this code useful in your research, please cite:
@InProceedings{Marban_2020_EC2T,
author = {Marban, Arturo and Becking, Daniel and Wiedemann, Simon and Samek, Wojciech},
title = {Learning Sparse & Ternary Neural Networks With Entropy-Constrained Trained Ternarization (EC2T)},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
month = {June},
year = {2020},
pages={3105-3113},
doi = {10.1109/CVPRW50498.2020.00369}
}
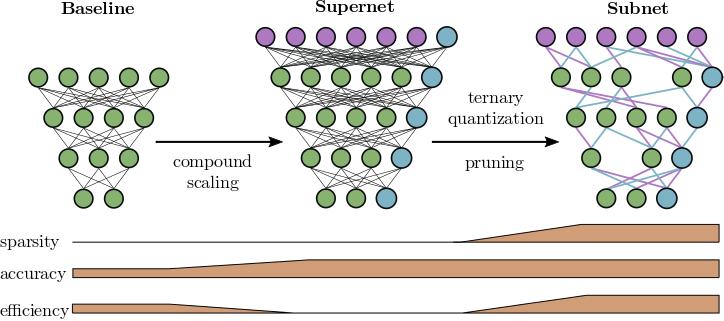
Learning Sparse & Ternary Neural Networks with EC2T:
Our improved scores:
| Task | # Params | Top-1 Acc. | Sparsity | # Scoring params | # Inference FLOPs | Overall Score |
|---|---|---|---|---|---|---|
CIFAR-100 |
8.0M | 80.13% | 90.49% | 0.23M | 71M | 0.0130 |
ImageNet |
7.8M | 75.05% | 60.73% | 0.97M | 256M | 0.3639 |
CIFAR-10 |
8.0M | 96.71% | 89.99% | 0.23M | 80M | - |
The improved models can be found at ./model_scoring/trained_t_models
Original MicroNet scores: Counting additions as FP32 ops and multiplications as FP16 ops:
| Task | # Params | Top-1 Acc. | Sparsity | # Scoring params | # Inference FLOP | Overall Score |
|---|---|---|---|---|---|---|
CIFAR-100 |
8.1M | 80.13% | 90.49% | 0.43M | 129.83M | 0.0242 |
ImageNet |
7.8M | 75.03% | 46.33% | 1.33M | 455.19M | 0.5821 |
| Model | # Params | Top-1 Acc. | Sparsity | # Scoring params | # Inference FLOPs |
|---|---|---|---|---|---|
ResNet-18 |
11.0M | 67.58% | 59.00% | 0.73M | 622M |
ResNet-20 |
269K | 91.01% | 63.90% | 12K | 8M |
To execute compound scaling, quantization or scoring run the according python run files at the top level of this project, e.g. python -u run_compound_scaling.py. Hyperparameters can be altered via the parser. To get all parser arguments execute
python -u run_compound_scaling.py --help
python -u run_quantization.py --help
python -u run_scoring.py --help
The --help flag will list all (optional) arguments for each run file. As an example
python -u run_scoring.py --no-halfprecision --t-model best_ternary_imagenet_micronet.pt --image-size 200
--no-cuda > console.txt
executes the scoring procedure with full precision parameters (32 bit), the quantized network which solved ImageNet best, with an input image size of 200x200 px and a CPU mapping instead of GPU usage. The console output can be saved optionally in a text file by appending > console.txt.
For using multiple GPUs set the CUDA_VISIBLE_DEVICES environment variable before executing the packages
export CUDA_VISIBLE_DEVICES=0,1
python -u run_compound_scaling.py --epochs 250 --batch-size 128 --grid 1.4 1.2 --phi 3.5 --dataset CIFAR100
--image-size 32
Copy the best full-precision model from ./model_compound_scaling/saved_models/best_model.pt to
./model_quantization/trained_fp_models and optionally rename it, e.g. c100_micronet_d14_w12_phi35.pt.
python -u run_quantization.py --model-dict c100_micronet_d14_w12_phi35.pt --batch-size 128 --epochs 20
--retrain-epochs 20 --ini-c-divrs 0.45 --lambda-max-divrs 0.15 --model cifar-micronet --dw-multps 1.4 1.2 --phi 3.5
--dataset CIFAR100
The best quantized model can be found in ./model_quantization/saved_models/Ternary_best_acc.pt.
Copy it to ./model_scoring/trained_t_models and optionally rename it, e.g.
c100_micronet_ec2t_spars90.pt.
Execute:
python -u run_scoring.py --t-model c100_micronet_ec2t_spars90.pt --model cifar_micronet
--dataset CIFAR100 --eval --halfprecision
In our environment EfficientNet-B1, which can be found in
./model_quantization/trained_fp_models, achieves an ImageNet accuracy of 78.4% which is 0.4% less than described
in the paper.
In a first step we quantize the "expand", "projection" and "head" convolutions of EfficientNet-B1 with our entropy controlled ternary approach:
python -u run_quantization.py --batch-size 128 --val-batch-size 256 --ini-c-divrs 0.2 --lambda-max-divrs 0.125
--model efficientnet-b1 --model-dict efficientnet_b1.pt --dataset ImageNet --image-size 224
--data-path [your_path] --epochs 20 --retrain-epochs 15
In a second step the non-ternary Squeeze-and-Excitation layers plus the fully connected layer run through the
same algorithm but only the assignment to the zero cluster is executed (entropy controlled pruning, important: set
--do-prune flag). Copy the best model from ./model_quantization/saved_models/ to
./model_quantization/trained_fp_models and optionally rename it, e.g. B1_ternary_exp_proj_head.pt. As the non-zero
values remain in full precision, hyperparameters ini-c-divrs and lambda-max-divrs can be increased:
python -u run_quantization.py --batch-size 128 --val-batch-size 256 --ini-c-divrs 0.25 --lambda-max-divrs 0.15
--model efficientnet-b1 --model-dict B1_ternary_exp_proj_head.pt --dataset ImageNet --image-size 224
--data-path [your_path] --epochs 10 --retrain-epochs 0 --do-prune --no-resume
Copy the best model from ./model_quantization/saved_models/ to ./model_scoring/trained_t_models and optionally
rename it, e.g. efficientnet_b1_ec2t_ecp_spars61.pt.
Execute:
python -u run_scoring.py --dataset ImageNet --data-path [your_path] --val-batch-size 256
--image-size 256 --model efficientnet-b1 --t-model efficientnet_b1_ec2t_ecp_spars61.pt
--prune-threshold 0.01 --eval --halfprecision
We used the PyTorch framework for our experiments (version 1.4.0) and CUDA version 10.1 plus cuDNN Version 7603.
As training hardware we used NVIDIA Tesla V100-PCIE-32GB GPUs with driver version 440.33.01
and NVIDIA TITAN V GPUs with driver version 430.40.
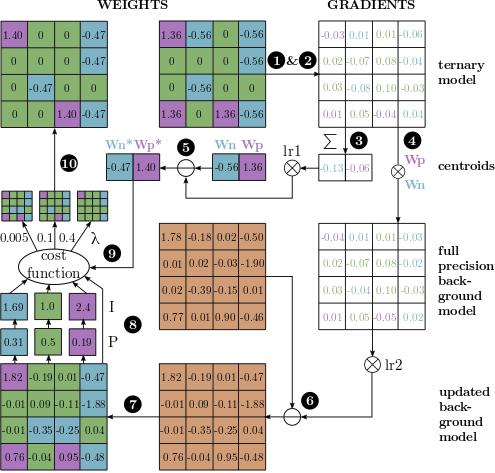
The EC2T Algorithm: