
-
Buying Degree of purchase of the vehicle.
-
Maint Degree of vehicle maintenance.
-
Doors Number of vehicle doors.
-
Persons Number of people that fit in the car.
-
Lug Boot Car trunk size.
-
Safety Degree of vehicle safety.

Almost all variables are well balanced.
Except for the class tag which is the variable to predict. Therefore, our model can be biased and give the prediction preference to the class that is in greater proportion.
The class variable has a clear imbalance. Therefore we will use the SMOTE transformation. Which consists in creating new data similar values. According to the percentage of class that is in greater proportion.

- max_depth: Maximum depth of the tree.
- random_state: Random tree state
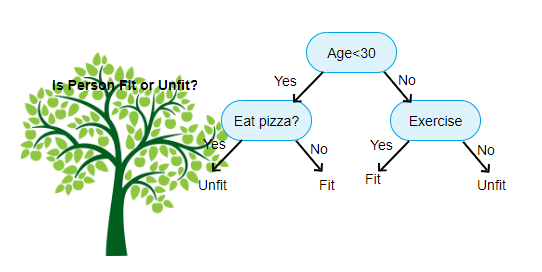
It works very similar to human logic. Use mathematical inequalities instead of questions. Since it is easier for algorithms to handle numbers than words.

Share several in common parameters. Except for a few:
- n_estimators: Number of decision trees.
- n_jobs: Number of working cores of the CPU.

The Random Forest algorithm works in a similar way to the decision tree. While decision tree you can only use one tree. With Random Forest you can use a maximum amount of 1000 estimators.

- kernel: SVC core.
- degree: Degree of the polynomial.

It consists of finding the best hyperplane that fits the data set. According to the kernel provided by the user. It works quite well for relatively small data sets.
It has the disadvantage of requiring a scalar setting for variables. In order to make them comparable to each other. Since these algorithms are very sensitive.
- The model must have balanced accuracy. For each case.
- The model must not only be adapted to the set of training deals.
- The algorithm must have good performance. For data you've never seen.
- Must have a high percentage of generalization.

Although the Random Forest outperforms the other models. The Decesion Tree has a fairly similar performance. Also be less computationally heavy and easier to explain.
Therefore I consider it as the winning model. Which I will use to develop the application.

It is just a short form of the decision tree. Since it has more depth.

Finally we send the application to production. To a free server since the algorithm is not very computationally expensive. Therefore, it can make predictions with speed on a server that uses CPU. We use a free Herouku server, so that other users can access and use the application.