编程系列的总结和学习会更新到另外一个仓库 编程
- FE-interview
- HTML, HTTP,web综合问题
- $CSS部分
- CSS选择器有哪些
- css sprite是什么,有什么优缺点
display: none;与visibility: hidden;的区别- css hack原理及常用hack
- specified value,computed value,used value计算方法
link与@import的区别display: block;和display: inline;的区别- PNG,GIF,JPG的区别及如何选
- CSS有哪些继承属性
- IE6浏览器有哪些常见的bug,缺陷或者与标准不一致的地方,如何解决
- 容器包含若干浮动元素时如何清理(包含)浮动
- 什么是FOUC?如何避免
- 如何创建块级格式化上下文(block formatting context),BFC有什么用
- display,float,position的关系
- 外边距折叠(collapsing margins)
- 如何确定一个元素的包含块(containing block)
- stacking context,布局规则
- 如何水平居中一个元素
- 如何竖直居中一个元素
- $javascript概念部分
- DOM元素e的e.getAttribute(propName)和e.propName有什么区别和联系
- offsetWidth/offsetHeight,clientWidth/clientHeight与scrollWidth/scrollHeight的区别
- XMLHttpRequest通用属性和方法
- focus/blur与focusin/focusout的区别与联系
- mouseover/mouseout与mouseenter/mouseleave的区别与联系
- sessionStorage,localStorage,cookie区别
- javascript跨域通信
- javascript有哪几种数据类型
- 什么闭包,闭包有什么用
- javascript有哪几种方法定义函数
- 应用程序存储和离线web应用
- 客户端存储localStorage和sessionStorage
- cookie及其操作
- javascript有哪些方法定义对象
- ===运算符判断相等的流程是怎样的
- ==运算符判断相等的流程是怎样的
- 对象到字符串的转换步骤
- 对象到数字的转换步骤
- <,>,<=,>=的比较规则
- +运算符工作流程
- 函数内部arguments变量有哪些特性,有哪些属性,如何将它转换为数组
- DOM事件模型是如何的,编写一个EventUtil工具类实现事件管理兼容
- 评价一下三种方法实现继承的优缺点,并改进
- $Vue概念部分
- $前端自动化
个人收集的前端知识点、面试题和答案,参考答案仅代表个人观点,方便复习,目录如下:

- 无状态协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,也就是说:当客户端一次HTTP请求完成以后, 客户端再发送一次HTTP请求, HTTP并不知道当前客户端是一个"老用户"。
- 可以使用Cookie来解决无状态的问题,Cookie就相当于一个通行证,第一次访问的时候给客户端发送一个Cookie,当客户端再次来的时候,拿着Cookie通行证),那么服务器就知道这个是"老用户"
- 合理的title、description、keywords:搜索对着三项的权重逐个减小,title值强调重点即可,重要关键词出现不要超过2次,而且要靠前,不同页面title要有所不同;description把页面内容高度概括,长度合适,不可过分堆砌关键词,不同页面description有所不同;keywords列举出重要关键词即可
- 语义化的HTML代码,符合W3C规范:语义化代码让搜索引擎容易理解网页
- 重要内容HTML代码放在最前:搜索引擎抓取HTML顺序是从上到下,有的搜索引擎对抓取长度有限制,保证重要内容一定会被抓取
- 重要内容不要用js输出:爬虫不会执行js获取内容
- 少用iframe:搜索引擎不会抓取iframe中的内容
- 非装饰性图片必须加alt
- 提高网站速度:网站速度是搜索引擎排序的一个重要指标
- cookie
- session
- url重写
- 隐藏input
- ip地址
<!doctype>声明必须处于HTML文档的头部,在<html>标签之前,HTML5中不区分大小写<!doctype>声明不是一个HTML标签,是一个用于告诉浏览器当前HTMl版本的指令- 现代浏览器的html布局引擎通过检查doctype决定使用兼容模式还是标准模式对文档进行渲染,一些浏览器有一个接近标准模型。
- 在HTML4.01中
<!doctype>声明指向一个DTD,由于HTML4.01基于SGML,所以DTD指定了标记规则以保证浏览器正确渲染内容 - HTML5不基于SGML,所以不用指定DTD
常见dotype:
- HTML4.01 strict:不允许使用表现性、废弃元素(如font)以及frameset。声明:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> - HTML4.01 Transitional:允许使用表现性、废弃元素(如font),不允许使用frameset。声明:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> - HTML4.01 Frameset:允许表现性元素,废气元素以及frameset。声明:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Frameset//EN" "http://www.w3.org/TR/html4/frameset.dtd"> - XHTML1.0 Strict:不使用允许表现性、废弃元素以及frameset。文档必须是结构良好的XML文档。声明:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> - XHTML1.0 Transitional:允许使用表现性、废弃元素,不允许frameset,文档必须是结构良好的XMl文档。声明:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> - XHTML 1.0 Frameset:允许使用表现性、废弃元素以及frameset,文档必须是结构良好的XML文档。声明:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd"> - HTML 5:
<!doctype html>
参考资料:MDN: html global attribute或者W3C HTML global-attributes
accesskey:设置快捷键,提供快速访问元素如aaa在windows下的firefox中按alt + shift + a可激活元素class:为元素设置类标识,多个类名用空格分开,CSS和javascript可通过class属性获取元素contenteditable: 指定元素内容是否可编辑contextmenu: 自定义鼠标右键弹出菜单内容data-*: 为元素增加自定义属性dir: 设置元素文本方向draggable: 设置元素是否可拖拽dropzone: 设置元素拖放类型: copy, move, linkhidden: 表示一个元素是否与文档。样式上会导致元素不显示,但是不能用这个属性实现样式效果id: 元素id,文档内唯一lang: 元素内容的的语言spellcheck: 是否启动拼写和语法检查style: 行内css样式tabindex: 设置元素可以获得焦点,通过tab可以导航title: 元素相关的建议信息translate: 元素和子孙节点内容是否需要本地化
web语义化是指通过HTML标记表示页面包含的信息,包含了HTML标签的语义化和css命名的语义化。 HTML标签的语义化是指:通过使用包含语义的标签(如h1-h6)恰当地表示文档结构 css命名的语义化是指:为html标签添加有意义的class,id补充未表达的语义,如Microformat通过添加符合规则的class描述信息 为什么需要语义化:
- 去掉样式后页面呈现清晰的结构
- 盲人使用读屏器更好地阅读
- 搜索引擎更好地理解页面,有利于收录
- 便团队项目的可持续运作及维护
- 一台服务器要与HTTP1.1兼容,只要为资源实现GET和HEAD方法即可
- GET是最常用的方法,通常用于请求服务器发送某个资源。
- HEAD与GET类似,但服务器在响应中值返回首部,不返回实体的主体部分
- PUT让服务器用请求的主体部分来创建一个由所请求的URL命名的新文档,或者,如果那个URL已经存在的话,就用干这个主体替代它
- POST起初是用来向服务器输入数据的。实际上,通常会用它来支持HTML的表单。表单中填好的数据通常会被送给服务器,然后由服务器将其发送到要去的地方。
- TRACE会在目的服务器端发起一个环回诊断,最后一站的服务器会弹回一个TRACE响应并在响应主体中携带它收到的原始请求报文。TRACE方法主要用于诊断,用于验证请求是否如愿穿过了请求/响应链。
- OPTIONS方法请求web服务器告知其支持的各种功能。可以查询服务器支持哪些方法或者对某些特殊资源支持哪些方法。
- DELETE请求服务器删除请求URL指定的资源
- 在浏览器地址栏输入URL
- 浏览器查看缓存,如果请求资源在缓存中并且新鲜,跳转到转码步骤
- 如果资源未缓存,发起新请求
- 如果已缓存,检验是否足够新鲜,足够新鲜直接提供给客户端,否则与服务器进行验证。
- 检验新鲜通常有两个HTTP头进行控制
Expires和Cache-Control:- HTTP1.0提供Expires,值为一个绝对时间表示缓存新鲜日期
- HTTP1.1增加了Cache-Control: max-age=,值为以秒为单位的最大新鲜时间
- 浏览器解析URL获取协议,主机,端口,path
- 浏览器组装一个HTTP(GET)请求报文
- 浏览器获取主机ip地址,过程如下:
- 浏览器缓存
- 本机缓存
- hosts文件
- 路由器缓存
- ISP DNS缓存
- DNS递归查询(可能存在负载均衡导致每次IP不一样)
- 打开一个socket与目标IP地址,端口建立TCP链接,三次握手如下:
- 客户端发送一个TCP的SYN=1,Seq=X的包到服务器端口
- 服务器发回SYN=1, ACK=X+1, Seq=Y的响应包
- 客户端发送ACK=Y+1, Seq=Z
- TCP链接建立后发送HTTP请求
- 服务器接受请求并解析,将请求转发到服务程序,如虚拟主机使用HTTP Host头部判断请求的服务程序
- 服务器检查HTTP请求头是否包含缓存验证信息如果验证缓存新鲜,返回304等对应状态码
- 处理程序读取完整请求并准备HTTP响应,可能需要查询数据库等操作
- 服务器将响应报文通过TCP连接发送回浏览器
- 浏览器接收HTTP响应,然后根据情况选择关闭TCP连接或者保留重用,关闭TCP连接的四次握手如下:
- 主动方发送Fin=1, Ack=Z, Seq= X报文
- 被动方发送ACK=X+1, Seq=Z报文
- 被动方发送Fin=1, ACK=X, Seq=Y报文
- 主动方发送ACK=Y, Seq=X报文
- 浏览器检查响应状态吗:是否为1XX,3XX, 4XX, 5XX,这些情况处理与2XX不同
- 如果资源可缓存,进行缓存
- 对响应进行解码(例如gzip压缩)
- 根据资源类型决定如何处理(假设资源为HTML文档)
- 解析HTML文档,构件DOM树,下载资源,构造CSSOM树,执行js脚本,这些操作没有严格的先后顺序,以下分别解释
- 构建DOM树:
- Tokenizing:根据HTML规范将字符流解析为标记
- Lexing:词法分析将标记转换为对象并定义属性和规则
- DOM construction:根据HTML标记关系将对象组成DOM树
- 解析过程中遇到图片、样式表、js文件,启动下载
- 构建CSSOM树:
- Tokenizing:字符流转换为标记流
- Node:根据标记创建节点
- CSSOM:节点创建CSSOM树
- 根据DOM树和CSSOM树构建渲染树:
- 从DOM树的根节点遍历所有可见节点,不可见节点包括:1)
script,meta这样本身不可见的标签。2)被css隐藏的节点,如display: none - 对每一个可见节点,找到恰当的CSSOM规则并应用
- 发布可视节点的内容和计算样式
- 从DOM树的根节点遍历所有可见节点,不可见节点包括:1)
- js解析如下:
- 浏览器创建Document对象并解析HTML,将解析到的元素和文本节点添加到文档中,此时document.readystate为loading
- HTML解析器遇到没有async和defer的script时,将他们添加到文档中,然后执行行内或外部脚本。这些脚本会同步执行,并且在脚本下载和执行时解析器会暂停。这样就可以用document.write()把文本插入到输入流中。同步脚本经常简单定义函数和注册事件处理程序,他们可以遍历和操作script和他们之前的文档内容
- 当解析器遇到设置了async属性的script时,开始下载脚本并继续解析文档。脚本会在它下载完成后尽快执行,但是解析器不会停下来等它下载。异步脚本禁止使用document.write(),它们可以访问自己script和之前的文档元素
- 当文档完成解析,document.readState变成interactive
- 所有defer脚本会按照在文档出现的顺序执行,延迟脚本能访问完整文档树,禁止使用document.write()
- 浏览器在Document对象上触发DOMContentLoaded事件
- 此时文档完全解析完成,浏览器可能还在等待如图片等内容加载,等这些内容完成载入并且所有异步脚本完成载入和执行,document.readState变为complete,window触发load事件
- 显示页面(HTML解析过程中会逐步显示页面)
rfc2616中进行了定义:
- 首行是Request-Line包括:请求方法,请求URI,协议版本,CRLF
- 首行之后是若干行请求头,包括general-header,request-header或者entity-header,每个一行以CRLF结束
- 请求头和消息实体之间有一个CRLF分隔
- 根据实际请求需要可能包含一个消息实体 一个请求报文例子如下:
GET /Protocols/rfc2616/rfc2616-sec5.html HTTP/1.1
Host: www.w3.org
Connection: keep-alive
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36
Referer: https://www.google.com.hk/
Accept-Encoding: gzip,deflate,sdch
Accept-Language: zh-CN,zh;q=0.8,en;q=0.6
Cookie: authorstyle=yes
If-None-Match: "2cc8-3e3073913b100"
If-Modified-Since: Wed, 01 Sep 2004 13:24:52 GMT
name=qiu&age=25
rfc2616中进行了定义:
- 首行是状态行包括:HTTP版本,状态码,状态描述,后面跟一个CRLF
- 首行之后是若干行响应头,包括:通用头部,响应头部,实体头部
- 响应头部和响应实体之间用一个CRLF空行分隔
- 最后是一个可能的消息实体 响应报文例子如下:
HTTP/1.1 200 OK
Date: Tue, 08 Jul 2014 05:28:43 GMT
Server: Apache/2
Last-Modified: Wed, 01 Sep 2004 13:24:52 GMT
ETag: "40d7-3e3073913b100"
Accept-Ranges: bytes
Content-Length: 16599
Cache-Control: max-age=21600
Expires: Tue, 08 Jul 2014 11:28:43 GMT
P3P: policyref="http://www.w3.org/2001/05/P3P/p3p.xml"
Content-Type: text/html; charset=iso-8859-1
{"name": "qiu", "age": 25}
雅虎Best Practices for Speeding Up Your Web Site:
-
content方面
- 减少HTTP请求:合并文件、CSS精灵、inline Image
- 减少DNS查询:DNS查询完成之前浏览器不能从这个主机下载任何任何文件。方法:DNS缓存、将资源分布到恰当数量的主机名,平衡并行下载和DNS查询
- 避免重定向:多余的中间访问
- 使Ajax可缓存
- 非必须组件延迟加载
- 未来所需组件预加载
- 减少DOM元素数量
- 将资源放到不同的域下:浏览器同时从一个域下载资源的数目有限,增加域可以提高并行下载量
- 减少iframe数量
- 不要404
-
Server方面
- 使用CDN
- 添加Expires或者Cache-Control响应头
- 对组件使用Gzip压缩
- 配置ETag
- Flush Buffer Early
- Ajax使用GET进行请求
- 避免空src的img标签
-
Cookie方面
- 减小cookie大小
- 引入资源的域名不要包含cookie
-
css方面
- 将样式表放到页面顶部
- 不使用CSS表达式
- 使用不使用@import
- 不使用IE的Filter
-
Javascript方面
- 将脚本放到页面底部
- 将javascript和css从外部引入
- 压缩javascript和css
- 删除不需要的脚本
- 减少DOM访问
- 合理设计事件监听器
-
图片方面
- 优化图片:根据实际颜色需要选择色深、压缩
- 优化css精灵
- 不要在HTML中拉伸图片
- 保证favicon.ico小并且可缓存
-
移动方面
- 保证组件小于25k
- Pack Components into a Multipart Document
渐进增强是指在web设计时强调可访问性、语义化HTML标签、外部样式表和脚本。保证所有人都能访问页面的基本内容和功能同时为高级浏览器和高带宽用户提供更好的用户体验。核心原则如下:
- 所有浏览器都必须能访问基本内容
- 所有浏览器都必须能使用基本功能
- 所有内容都包含在语义化标签中
- 通过外部CSS提供增强的布局
- 通过非侵入式、外部javascript提供增强功能
- end-user web browser preferences are respected
参考RFC 2616
- 1XX:信息状态码
- 100 Continue:客户端应当继续发送请求。这个临时相应是用来通知客户端它的部分请求已经被服务器接收,且仍未被拒绝。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。服务器必须在请求万仇向客户端发送一个最终响应
- 101 Switching Protocols:服务器已经理解力客户端的请求,并将通过Upgrade消息头通知客户端采用不同的协议来完成这个请求。在发送完这个响应最后的空行后,服务器将会切换到Upgrade消息头中定义的那些协议。
- 2XX:成功状态码
- 200 OK:请求成功,请求所希望的响应头或数据体将随此响应返回
- 201 Created:已创建
- 202 Accepted:已接受
- 203 Non-Authoritative Information:非授权信息
- 204 No Content: 无内容
- 205 Reset Content:重置内容
- 206 Partial Content:部分内容
- 3XX:重定向
- 300 Multiple Choices:
- 301 Moved Permanently:已被永远移走
- 302 Found:对象已移动
- 303 See Other:
- 304 Not Modified:未发现修改
- 305 Use Proxy:
- 306 (unused):
- 307 Temporary Redirect:临时重定向
- 4XX:客户端错误
- 400 Bad Request: 错误的请求。由于语法格式不正确,服务器无法理解该请求.
- 401 Unauthorized: 访问被拒绝
- 402 Payment Required:
- 403 Forbidden: 禁止访问
- 404 Not Found: 未找到路径
- 405 Method Not Allowed: 不允许的方法
- 406 Not Acceptable: 客户端浏览器不接受所请求页面的 MIME 类型
- 407 Proxy Authentication Required:
- 408 Request Timeout: 请求超时
- 409 Conflict:
- 410 Gone:
- 411 Length Required:
- 412 Precondition Failed: 前提条件失败
- 413 Request Entity Too Large:
- 414 Request-URI Too Long:
- 415 Unsupported Media Type:
- 416 Requested Range Not Satisfiable:
- 417 Expectation Failed:
- 5XX: 服务器错误
- 500 Internal Server Error: 服务器内部错误(服务端代码出现错误)
- 501 Not Implemented: 数据值指定了未实现的配置
- 502 Bad Gateway: Web 服务器用作网关或代理服务器时收到了无效响应
- 503 Service Unavailable: 服务不可用
- 504 Gateway Timeout: web 服务器网关超时
- 505 HTTP Version Not Supported: HTTP版本不支持
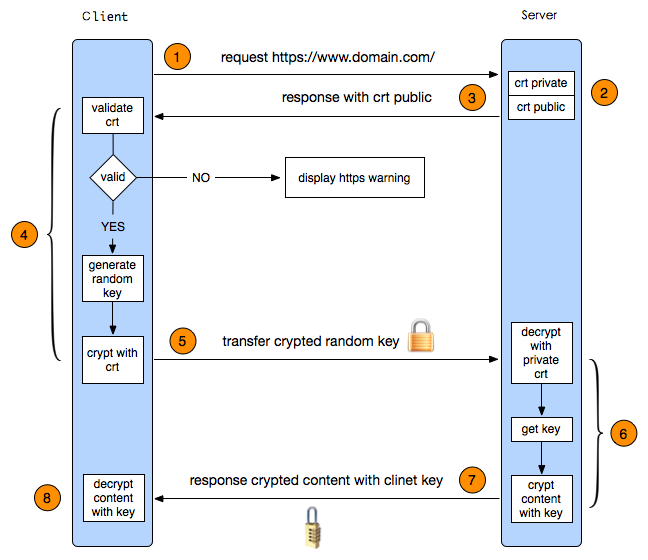
- 首先HTTP请求服务端生成证书,客户端对证书的有效期、合法性、域名是否与请求的域名一致、证书的公钥(RSA加密)等进行校验;
- 客户端如果校验通过后,就根据证书的公钥的有效, 生成随机数,随机数使用公钥进行加密(RSA加密;
- 消息体产生的后,对它的摘要进行MD5(或者SHA1)算法加密,此时就得到了RSA签名;
- 发送给服务端,此时只有服务端(RSA私钥)能解密;
- 解密得到的随机数,再用AES加密,作为密钥(此时的密钥只有客户端和服务端知道)。

- *通用选择器:选择所有元素,不参与计算优先级,兼容性IE6+
- #X id选择器:选择id值为X的元素,兼容性:IE6+
- .X 类选择器: 选择class包含X的元素,兼容性:IE6+
- X Y后代选择器: 选择满足X选择器的后代节点中满足Y选择器的元素,兼容性:IE6+
- X 元素选择器: 选择标所有签为X的元素,兼容性:IE6+
- :link,:visited,:focus,:hover,:active链接状态: 选择特定状态的链接元素,顺序LoVe HAte,兼容性: IE4+
- X + Y直接兄弟选择器:在X之后第一个兄弟节点中选择满足Y选择器的元素,兼容性: IE7+
- X > Y子选择器: 选择X的子元素中满足Y选择器的元素,兼容性: IE7+
- X ~ Y兄弟: 选择X之后所有兄弟节点中满足Y选择器的元素,兼容性: IE7+
- [attr]:选择所有设置了attr属性的元素,兼容性IE7+
- [attr=value]:选择属性值刚好为value的元素
- [attr~=value]:选择属性值为空白符分隔,其中一个的值刚好是value的元素
- [attr|=value]:选择属性值刚好为value或者value-开头的元素
- [attr^=value]:选择属性值以value开头的元素
- [attr$=value]:选择属性值以value结尾的元素
- [attr=value]*:选择属性值中包含value的元素
- [:checked]:选择单选框,复选框,下拉框中选中状态下的元素,兼容性:IE9+
- X:after, X::after:after伪元素,选择元素虚拟子元素(元素的最后一个子元素),CSS3中::表示伪元素。兼容性:after为IE8+,::after为IE9+
- :hover:鼠标移入状态的元素,兼容性a标签IE4+, 所有元素IE7+
- :not(selector):选择不符合selector的元素。不参与计算优先级,兼容性:IE9+
- ::first-letter:伪元素,选择块元素第一行的第一个字母,兼容性IE5.5+
- ::first-line:伪元素,选择块元素的第一行,兼容性IE5.5+
- :nth-child(an + b):伪类,选择前面有an + b - 1个兄弟节点的元素,其中n >= 0, 兼容性IE9+
- :nth-last-child(an + b):伪类,选择后面有an + b - 1个兄弟节点的元素 其中n >= 0,兼容性IE9+
- X:nth-of-type(an+b):伪类,X为选择器,解析得到元素标签,选择前面有an + b - 1个相同标签兄弟节点的元素。兼容性IE9+
- X:nth-last-of-type(an+b):伪类,X为选择器,解析得到元素标签,选择后面有an+b-1个相同标签兄弟节点的元素。兼容性IE9+
- X:first-child:伪类,选择满足X选择器的元素,且这个元素是其父节点的第一个子元素。兼容性IE7+
- X:last-child:伪类,选择满足X选择器的元素,且这个元素是其父节点的最后一个子元素。兼容性IE9+
- X:only-child:伪类,选择满足X选择器的元素,且这个元素是其父元素的唯一子元素。兼容性IE9+
- X:only-of-type:伪类,选择X选择的元素,解析得到元素标签,如果该元素没有相同类型的兄弟节点时选中它。兼容性IE9+
- X:first-of-type:伪类,选择X选择的元素,解析得到元素标签,如果该元素 是此此类型元素的第一个兄弟。选中它。兼容性IE9+
概念:将多个小图片拼接到一个图片中。通过background-position和元素尺寸调节需要显示的背景图案。
优点:
- 减少HTTP请求数,极大地提高页面加载速度
- 增加图片信息重复度,提高压缩比,减少图片大小
- 更换风格方便,只需在一张或几张图片上修改颜色或样式即可实现
缺点:
- 图片合并麻烦
- 维护麻烦,修改一个图片可能需要从新布局整个图片,样式
display: none;与visibility: hidden;的区别
联系:它们都能让元素不可见
区别:
- display:none;会让元素完全从渲染树中消失,渲染的时候不占据任何空间;visibility: hidden;不会让元素从渲染树消失,渲染师元素继续占据空间,只是内容不可见
- display: none;是非继承属性,子孙节点消失由于元素从渲染树消失造成,通过修改子孙节点属性无法显示;visibility: hidden;是继承属性,子孙节点消失由于继承了hidden,通过设置visibility: visible;可以让子孙节点显式
- 修改常规流中元素的display通常会造成文档重排。修改visibility属性只会造成本元素的重绘。
- 读屏器不会读取display: none;元素内容;会读取visibility: hidden;元素内容
原理:利用不同浏览器对CSS的支持和解析结果不一样编写针对特定浏览器样式。常见的hack有1)属性hack。2)选择器hack。3)IE条件注释
- IE条件注释:适用于[IE5, IE9]常见格式如下
<!--[if IE 6]>
Special instructions for IE 6 here
<![endif]-->
- 选择器hack:不同浏览器对选择器的支持不一样
/***** Selector Hacks ******/
/* IE6 and below */
* html #uno { color: red }
/* IE7 */
*:first-child+html #dos { color: red }
/* IE7, FF, Saf, Opera */
html>body #tres { color: red }
/* IE8, FF, Saf, Opera (Everything but IE 6,7) */
html>/**/body #cuatro { color: red }
/* Opera 9.27 and below, safari 2 */
html:first-child #cinco { color: red }
/* Safari 2-3 */
html[xmlns*=""] body:last-child #seis { color: red }
/* safari 3+, chrome 1+, opera9+, ff 3.5+ */
body:nth-of-type(1) #siete { color: red }
/* safari 3+, chrome 1+, opera9+, ff 3.5+ */
body:first-of-type #ocho { color: red }
/* saf3+, chrome1+ */
@media screen and (-webkit-min-device-pixel-ratio:0) {
#diez { color: red }
}
/* iPhone / mobile webkit */
@media screen and (max-device-width: 480px) {
#veintiseis { color: red }
}
/* Safari 2 - 3.1 */
html[xmlns*=""]:root #trece { color: red }
/* Safari 2 - 3.1, Opera 9.25 */
*|html[xmlns*=""] #catorce { color: red }
/* Everything but IE6-8 */
:root *> #quince { color: red }
/* IE7 */
*+html #dieciocho { color: red }
/* Firefox only. 1+ */
#veinticuatro, x:-moz-any-link { color: red }
/* Firefox 3.0+ */
#veinticinco, x:-moz-any-link, x:default { color: red }
- 属性hack:不同浏览器解析bug或方法
/* IE6 */
#once { _color: blue }
/* IE6, IE7 */
#doce { *color: blue; /* or #color: blue */ }
/* Everything but IE6 */
#diecisiete { color/**/: blue }
/* IE6, IE7, IE8 */
#diecinueve { color: blue\9; }
/* IE7, IE8 */
#veinte { color/*\**/: blue\9; }
/* IE6, IE7 -- acts as an !important */
#veintesiete { color: blue !ie; } /* string after ! can be anything */
-
specified value: 计算方法如下:
- 如果样式表设置了一个值,使用这个值
- 如果没有设置值,这个属性是继承属性,从父元素继承
- 如果没设置,并且不是继承属性,使用css规范指定的初始值
-
computed value: 以specified value根据规范定义的行为进行计算,通常将相对值计算为绝对值,例如em根据font-size进行计算。一些使用百分数并且需要布局来决定最终值的属性,如width,margin。百分数就直接作为computed value。line-height的无单位值也直接作为computed value。这些值将在计算used value时得到绝对值。computed value的主要作用是用于继承
-
used value:属性计算后的最终值,对于大多数属性可以通过window.getComputedStyle获得,尺寸值单位为像素。以下属性依赖于布局,
- background-position
- bottom, left, right, top
- height, width
- margin-bottom, margin-left, margin-right, margin-top
- min-height, min-width
- padding-bottom, padding-left, padding-right, padding-top
- text-indent
link是HTML方式,@import是CSS方式link最大限度支持并行下载,@import过多嵌套导致串行下载,出现FOUClink可以通过rel="alternate stylesheet"指定候选样式- 浏览器对
link支持早于@import,可以使用@import对老浏览器隐藏样式 @import必须在样式规则之前,可以在css文件中引用其他文件- 总体来说:link优于@import
block元素特点:
1.处于常规流中时,如果width没有设置,会自动填充满父容器
2.可以应用margin/padding
3.在没有设置高度的情况下会扩展高度以包含常规流中的子元素
4.处于常规流中时布局时在前后元素位置之间(独占一个水平空间)
5.忽略vertical-align
inline元素特点
1.水平方向上根据direction依次布局
2.不会在元素前后进行换行
3.受white-space控制
4.margin/padding在竖直方向上无效,水平方向上有效
5.width/height属性对非替换行内元素无效,宽度由元素内容决定
6.非替换行内元素的行框高由line-height确定,替换行内元素的行框高由height,margin,padding,border决定
6.浮动或绝对定位时会转换为block
7.vertical-align属性生效
参考资料: 选择正确的图片格式 GIF:
- 8位像素,256色
- 无损压缩
- 支持简单动画
- 支持boolean透明
- 适合简单动画
JPEG:
- 颜色限于256
- 有损压缩
- 可控制压缩质量
- 不支持透明
- 适合照片
PNG:
- 有PNG8和truecolor PNG
- PNG8类似GIF颜色上限为256,文件小,支持alpha透明度,无动画
- 适合图标、背景、按钮
- 关于文字排版的属性如:
- line-height
- color
- visibility
- cursor
- IE6不支持min-height,解决办法使用css hack:
.target {
min-height: 100px;
height: auto !important;
height: 100px; // IE6下内容高度超过会自动扩展高度
}
-
ol内li的序号全为1,不递增。解决方法:为li设置样式display: list-item; -
未定位父元素
overflow: auto;,包含position: relative;子元素,子元素高于父元素时会溢出。解决办法:1)子元素去掉position: relative;; 2)不能为子元素去掉定位时,父元素position: relative;
<style type="text/css">
.outer {
width: 215px;
height: 100px;
border: 1px solid red;
overflow: auto;
position: relative; /* 修复bug */
}
.inner {
width: 100px;
height: 200px;
background-color: purple;
position: relative;
}
</style>
<div class="outer">
<div class="inner"></div>
</div>
- IE6只支持
a标签的:hover伪类,解决方法:使用js为元素监听mouseenter,mouseleave事件,添加类实现效果:
<style type="text/css">
.p:hover,
.hover {
background: purple;
}
</style>
<p class="p" id="target">aaaa bbbbb<span>DDDDDDDDDDDd</span> aaaa lkjlkjdf j</p>
<script type="text/javascript">
function addClass(elem, cls) {
if (elem.className) {
elem.className += ' ' + cls;
} else {
elem.className = cls;
}
}
function removeClass(elem, cls) {
var className = ' ' + elem.className + ' ';
var reg = new RegExp(' +' + cls + ' +', 'g');
elem.className = className.replace(reg, ' ').replace(/^ +| +$/, '');
}
var target = document.getElementById('target');
if (target.attachEvent) {
target.attachEvent('onmouseenter', function () {
addClass(target, 'hover');
});
target.attachEvent('onmouseleave', function () {
removeClass(target, 'hover');
})
}
</script>
- IE5-8不支持
opacity,解决办法:
.opacity {
opacity: 0.4
filter: alpha(opacity=60); /* for IE5-7 */
-ms-filter: "progid:DXImageTransform.Microsoft.Alpha(Opacity=60)"; /* for IE 8*/
}
- IE6在设置
height小于font-size时高度值为font-size,解决办法:font-size: 0; - IE6不支持PNG透明背景,解决办法: IE6下使用gif图片
- IE6-7不支持
display: inline-block解决办法:设置inline并触发hasLayout
display: inline-block;
*display: inline;
*zoom: 1;
- IE6下浮动元素在浮动方向上与父元素边界接触元素的外边距会加倍。解决办法:
1)使用padding控制间距。
2)浮动元素
display: inline;这样解决问题且无任何副作用:css标准规定浮动元素display:inline会自动调整为block - 通过为块级元素设置宽度和左右margin为auto时,IE6不能实现水平居中,解决方法:为父元素设置
text-align: center;
- 容器元素闭合标签前添加额外元素并设置
clear: both - 父元素触发块级格式化上下文(见块级可视化上下文部分)
- 设置容器元素伪元素进行清理推荐的清理浮动方法
/**
* 在标准浏览器下使用
* 1 content内容为空格用于修复opera下文档中出现
* contenteditable属性时在清理浮动元素上下的空白
* 2 使用display使用table而不是block:可以防止容器和
* 子元素top-margin折叠,这样能使清理效果与BFC,IE6/7
* zoom: 1;一致
**/
.clearfix:before,
.clearfix:after {
content: " "; /* 1 */
display: table; /* 2 */
}
.clearfix:after {
clear: both;
}
/**
* IE 6/7下使用
* 通过触发hasLayout实现包含浮动
**/
.clearfix {
*zoom: 1;
}
Flash Of Unstyled Content:用户定义样式表加载之前浏览器使用默认样式显示文档,用户样式加载渲染之后再从新显示文档,造成页面闪烁。解决方法:把样式表放到文档的head
创建规则:
- 根元素
- 浮动元素(
float不是none) - 绝对定位元素(
position取值为absolute或fixed) display取值为inline-block,table-cell,table-caption,flex,inline-flex之一的元素overflow不是visible的元素
作用:
- 可以包含浮动元素
- 不被浮动元素覆盖
- 阻止父子元素的margin折叠
- 如果
display为none,那么position和float都不起作用,这种情况下元素不产生框 - 否则,如果position值为absolute或者fixed,框就是绝对定位的,float的计算值为none,display根据下面的表格进行调整。
- 否则,如果float不是none,框是浮动的,display根据下表进行调整
- 否则,如果元素是根元素,display根据下表进行调整
- 其他情况下display的值为指定值
总结起来:绝对定位、浮动、根元素都需要调整
display

毗邻的两个或多个margin会合并成一个margin,叫做外边距折叠。规则如下:
- 两个或多个毗邻的普通流中的块元素垂直方向上的margin会折叠
- 浮动元素/inline-block元素/绝对定位元素的margin不会和垂直方向上的其他元素的margin折叠
- 创建了块级格式化上下文的元素,不会和它的子元素发生margin折叠
- 元素自身的margin-bottom和margin-top相邻时也会折叠
-
根元素的包含块叫做初始包含块,在连续媒体中他的尺寸与viewport相同并且anchored at the canvas origin;对于paged media,它的尺寸等于page area。初始包含块的direction属性与根元素相同。
-
position为relative或者static的元素,它的包含块由最近的块级(display为block,list-item,table)祖先元素的内容框组成 -
如果元素
position为fixed。对于连续媒体,它的包含块为viewport;对于paged media,包含块为page area -
如果元素
position为absolute,它的包含块由祖先元素中最近一个position为relative,absolute或者fixed的元素产生,规则如下:- 如果祖先元素为行内元素,the containing block is the bounding box around the padding boxes of the first and the last inline boxes generated for that element.
- 其他情况下包含块由祖先节点的padding edge组成
如果找不到定位的祖先元素,包含块为初始包含块
z轴上的默认层叠顺序如下(从下到上):
- 根元素的边界和背景
- 常规流中的元素按照html中顺序
- 浮动块
- positioned元素按照html中出现顺序
如何创建stacking context:
- 根元素
- z-index不为auto的定位元素
- a flex item with a z-index value other than 'auto'
- opacity小于1的元素
- 在移动端webkit和chrome22+,z-index为auto,position: fixed也将创建新的stacking context
- 如果需要居中的元素为常规流中inline元素,为父元素设置
text-align: center;即可实现 - 如果需要居中的元素为常规流中block元素,1)为元素设置宽度,2)设置左右margin为auto。3)IE6下需在父元素上设置
text-align: center;,再给子元素恢复需要的值
<body>
<div class="content">
aaaaaa aaaaaa a a a a a a a a
</div>
</body>
<style>
body {
background: #DDD;
text-align: center; /* 3 */
}
.content {
width: 500px; /* 1 */
text-align: left; /* 3 */
margin: 0 auto; /* 2 */
background: purple;
}
</style>
- 如果需要居中的元素为浮动元素,1)为元素设置宽度,2)
position: relative;,3)浮动方向偏移量(left或者right)设置为50%,4)浮动方向上的margin设置为元素宽度一半乘以-1
<body>
<div class="content">
aaaaaa aaaaaa a a a a a a a a
</div>
</body>
<style>
body {
background: #DDD;
}
.content {
width: 500px; /* 1 */
float: left;
position: relative; /* 2 */
left: 50%; /* 3 */
margin-left: -250px; /* 4 */
background-color: purple;
}
</style>
- 如果需要居中的元素为绝对定位元素,1)为元素设置宽度,2)偏移量设置为50%,3)偏移方向外边距设置为元素宽度一半乘以-1
<body>
<div class="content">
aaaaaa aaaaaa a a a a a a a a
</div>
</body>
<style>
body {
background: #DDD;
position: relative;
}
.content {
width: 800px;
position: absolute;
left: 50%;
margin-left: -400px;
background-color: purple;
}
</style>
- 如果需要居中的元素为绝对定位元素,1)为元素设置宽度,2)设置左右偏移量都为0,3)设置左右外边距都为auto
<body>
<div class="content">
aaaaaa aaaaaa a a a a a a a a
</div>
</body>
<style>
body {
background: #DDD;
position: relative;
}
.content {
width: 800px;
position: absolute;
margin: 0 auto;
left: 0;
right: 0;
background-color: purple;
}
</style>
参考资料:6 Methods For Vertical Centering With CSS。 盘点8种CSS实现垂直居中
- 需要居中元素为单行文本,为包含文本的元素设置大于
font-size的line-height:
<p class="text">center text</p>
<style>
.text {
line-height: 200px;
}
</style>
- e.getAttribute(),是标准DOM操作文档元素属性的方法,具有通用性可在任意文档上使用,返回元素在源文件中设置的属性
- e.propName通常是在HTML文档中访问特定元素的特性,浏览器解析元素后生成对应对象(如a标签生成HTMLAnchorElement),这些对象的特性会根据特定规则结合属性设置得到,对于没有对应特性的属性,只能使用getAttribute进行访问
- e.getAttribute()返回值是源文件中设置的值,类型是字符串或者null(有的实现返回"")
- e.propName返回值可能是字符串、布尔值、对象、undefined等
- 大部分attribute与property是一一对应关系,修改其中一个会影响另一个,如id,title等属性
- 一些布尔属性
<input hidden/>的检测设置需要hasAttribute和removeAttribute来完成,或者设置对应property - 像
<a href="../index.html">link</a>中href属性,转换成property的时候需要通过转换得到完整URL - 一些attribute和property不是一一对应如:form控件中
<input value="hello"/>对应的是defaultValue,修改或设置value property修改的是控件当前值,setAttribute修改value属性不会改变value property
- offsetWidth/offsetHeight返回值包含content + padding + border,效果与e.getBoundingClientRect()相同
- clientWidth/clientHeight返回值只包含content + padding,如果有滚动条,也不包含滚动条
- scrollWidth/scrollHeight返回值包含content + padding + 溢出内容的尺寸
Measuring Element Dimension and Location with CSSOM in Windows Internet Explorer 9

readyState:表示请求状态的整数,取值:
- UNSENT(0):对象已创建
- OPENED(1):open()成功调用,在这个状态下,可以为xhr设置请求头,或者使用send()发送请求
- HEADERS_RECEIVED(2):所有重定向已经自动完成访问,并且最终响应的HTTP头已经收到
- LOADING(3):响应体正在接收
- DONE(4):数据传输完成或者传输产生错误
onreadystatechange:readyState改变时调用的函数status:服务器返回的HTTP状态码(如,200, 404)statusText:服务器返回的HTTP状态信息(如,OK,No Content)responseText:作为字符串形式的来自服务器的完整响应responseXML: Document对象,表示服务器的响应解析成的XML文档abort():取消异步HTTP请求getAllResponseHeaders(): 返回一个字符串,包含响应中服务器发送的全部HTTP报头。每个报头都是一个用冒号分隔开的名/值对,并且使用一个回车/换行来分隔报头行getResponseHeader(headerName):返回headName对应的报头值open(method, url, asynchronous [, user, password]):初始化准备发送到服务器上的请求。method是HTTP方法,不区分大小写;url是请求发送的相对或绝对URL;asynchronous表示请求是否异步;user和password提供身份验证setRequestHeader(name, value):设置HTTP报头send(body):对服务器请求进行初始化。参数body包含请求的主体部分,对于POST请求为键值对字符串;对于GET请求,为null
- focus/blur不冒泡,focusin/focusout冒泡
- focus/blur兼容性好,focusin/focusout在除FireFox外的浏览器下都保持良好兼容性,如需使用事件托管,可考虑在FireFox下使用事件捕获elem.addEventListener('focus', handler, true)
- 可获得焦点的元素:
- window
- 链接被点击或键盘操作
- 表单空间被点击或键盘操作
- 设置
tabindex属性的元素被点击或键盘操作
- mouseover/mouseout是标准事件,所有浏览器都支持;mouseenter/mouseleave是IE5.5引入的特有事件后来被DOM3标准采纳,现代标准浏览器也支持
- mouseover/mouseout是冒泡事件;mouseenter/mouseleave不冒泡。需要为多个元素监听鼠标移入/出事件时,推荐mouseover/mouseout托管,提高性能
- 标准事件模型中event.target表示发生移入/出的元素,vent.relatedTarget对应移出/如元素;在老IE中event.srcElement表示发生移入/出的元素,event.toElement表示移出的目标元素,event.fromElement表示移入时的来源元素
例子:鼠标从div#target元素移出时进行处理,判断逻辑如下:
<div id="target"><span>test</span></div>
<script type="text/javascript">
var target = document.getElementById('target');
if (target.addEventListener) {
target.addEventListener('mouseout', mouseoutHandler, false);
} else if (target.attachEvent) {
target.attachEvent('onmouseout', mouseoutHandler);
}
function mouseoutHandler(e) {
e = e || window.event;
var target = e.target || e.srcElement;
// 判断移出鼠标的元素是否为目标元素
if (target.id !== 'target') {
return;
}
// 判断鼠标是移出元素还是移到子元素
var relatedTarget = event.relatedTarget || e.toElement;
while (relatedTarget !== target
&& relatedTarget.nodeName.toUpperCase() !== 'BODY') {
relatedTarget = relatedTarget.parentNode;
}
// 如果相等,说明鼠标在元素内部移动
if (relatedTarget === target) {
return;
}
// 执行需要操作
//alert('鼠标移出');
}
</script>
- 都会在浏览器端保存,有大小限制,同源限制
- cookie会在请求时发送到服务器,作为会话标识,服务器可修改cookie;web storage不会发送到服务器
- cookie有path概念,子路径可以访问父路径cookie,父路径不能访问子路径cookie
- 有效期:cookie在设置的有效期内有效,默认为浏览器关闭;sessionStorage在窗口关闭前有效,localStorage长期有效,直到用户删除
- 共享:sessionStorage不能共享,localStorage在同源文档之间共享,cookie在同源且符合path规则的文档之间共享
- localStorage的修改会促发其他文档窗口的update事件
- cookie有secure属性要求HTTPS传输
- 浏览器不能保存超过300个cookie,单个服务器不能超过20个,每个cookie不能超过4k。web storage大小支持能达到5M
同源:两个文档同源需满足
- 协议相同
- 域名相同
- 端口相同
跨域通信:js进行DOM操作、通信时如果目标与当前窗口不满足同源条件,浏览器为了安全会阻止跨域操作。跨域通信通常有以下方法
- 如果是log之类的简单单项通信,新建
<img>,<script>,<link>,<iframe>元素,通过src,href属性设置为目标url。实现跨域请求 - 如果请求json数据,使用
<script>进行jsonp请求 - 现代浏览器中多窗口通信使用HTML5规范的targetWindow.postMessage(data, origin);其中data是需要发送的对象,origin是目标窗口的origin。window.addEventListener('message', handler, false);handler的event.data是postMessage发送来的数据,event.origin是发送窗口的origin,event.source是发送消息的窗口引用
- 内部服务器代理请求跨域url,然后返回数据
- 跨域请求数据,现代浏览器可使用HTML5规范的CORS功能,只要目标服务器返回HTTP头部**
Access-Control-Allow-Origin: ***即可像普通ajax一样访问跨域资源
六种基本数据类型
- undefined
- null
- string
- boolean
- number
- symbol(ES6)
一种引用类型
- Object
闭包是在某个作用域内定义的函数,它可以访问这个作用域内的所有变量。闭包作用域链通常包括三个部分:
- 函数本身作用域。
- 闭包定义时的作用域。
- 全局作用域。
闭包常见用途:
- 创建特权方法用于访问控制
- 事件处理程序及回调
重要参考资料:MDN:Functions_and_function_scope
HTML5新增应用程序缓存,允许web应用将应用程序自身保存到用户浏览器中,用户离线状态也能访问。
1.为html元素设置manifest属性:<html manifest="myapp.appcache">,其中后缀名只是一个约定,真正识别方式是通过text/cache-manifest作为MIME类型。所以需要配置服务器保证设置正确
2.manifest文件首行为CACHE MANIFEST,其余就是要缓存的URL列表,每个一行,相对路径都相对于manifest文件的url。注释以#开头
3.url分为三种类型:CACHE:为默认类型。NETWORK:表示资源从不缓存。 FALLBACK:每行包含两个url,第二个URL是指需要加载和存储在缓存中的资源, 第一个URL是一个前缀。任何匹配该前缀的URL都不会缓存,如果从网络中载入这样的URL失败的话,就会用第二个URL指定的缓存资源来替代。以下是一个文件例子:
CACHE MANIFEST
CACHE:
myapp.html
myapp.css
myapp.js
FALLBACK:
videos/ offline_help.html
NETWORK:
cgi/
- localStorage有效期为永久,sessionStorage有效期为顶层窗口关闭前
- 同源文档可以读取并修改localStorage数据,sessionStorage只允许同一个窗口下的文档访问,如通过iframe引入的同源文档。
- Storage对象通常被当做普通javascript对象使用:通过设置属性来存取字符串值,也可以通过setItem(key, value)设置,getItem(key)读取,removeItem(key)删除,clear()删除所有数据,length表示已存储的数据项数目,key(index)返回对应索引的key
localStorage.setItem('x', 1); // storge x->1
localStorage.getItem('x); // return value of x
// 枚举所有存储的键值对
for (var i = 0, len = localStorage.length; i < len; ++i ) {
var name = localStorage.key(i);
var value = localStorage.getItem(name);
}
localStorage.removeItem('x'); // remove x
localStorage.clear(); // remove all data
- cookie是web浏览器存储的少量数据,最早设计为服务器端使用,作为HTTP协议的扩展实现。cookie数据会自动在浏览器和服务器之间传输。
- 通过读写cookie检测是否支持
- cookie属性有名,值,max-age,path, domain,secure;
- cookie默认有效期为浏览器会话,一旦用户关闭浏览器,数据就丢失,通过设置max-age=seconds属性告诉浏览器cookie有效期
- cookie作用域通过文档源和文档路径来确定,通过path和domain进行配置,web页面同目录或子目录文档都可访问
- 通过cookie保存数据的方法为:为document.cookie设置一个符合目标的字符串如下
- 读取document.cookie获得'; '分隔的字符串,key=value,解析得到结果
document.cookie = 'name=qiu; max-age=9999; path=/; domain=domain; secure';
document.cookie = 'name=aaa; path=/; domain=domain; secure';
// 要改变cookie的值,需要使用相同的名字、路径和域,新的值
// 来设置cookie,同样的方法可以用来改变有效期
// 设置max-age为0可以删除指定cookie
//读取cookie,访问document.cookie返回键值对组成的字符串,
//不同键值对之间用'; '分隔。通过解析获得需要的值
cookieUtil.js:自己写的cookie操作工具
- 对象字面量:
var obj = {}; - 构造函数:
var obj = new Object(); - Object.create():
var obj = Object.create(Object.prototype);
- 如果两个值不是相同类型,它们不相等
- 如果两个值都是null或者都是undefined,它们相等
- 如果两个值都是布尔类型true或者都是false,它们相等
- 如果其中有一个是NaN,它们不相等
- 如果都是数值型并且数值相等,他们相等, -0等于0
- 如果他们都是字符串并且在相同位置包含相同的16位值,他它们相等;如果在长度或者内容上不等,它们不相等;两个字符串显示结果相同但是编码不同==和===都认为他们不相等
- 如果他们指向相同对象、数组、函数,它们相等;如果指向不同对象,他们不相等
- 如果两个值类型相同,按照===比较方法进行比较
- 如果类型不同,使用如下规则进行比较
- 如果其中一个值是null,另一个是undefined,它们相等
- 如果一个值是数字另一个是字符串,将字符串转换为数字进行比较
- 如果有布尔类型,将true转换为1,false转换为0,然后用==规则继续比较
- 如果一个值是对象,另一个是数字或字符串,将对象转换为原始值然后用==规则继续比较
- 其他所有情况都认为不相等
- 如果对象有toString()方法,javascript调用它。如果返回一个原始值(primitive value如:string number boolean),将这个值转换为字符串作为结果
- 如果对象没有toString()方法或者返回值不是原始值,javascript寻找对象的valueOf()方法,如果存在就调用它,返回结果是原始值则转为字符串作为结果
- 否则,javascript不能从toString()或者valueOf()获得一个原始值,此时throws a TypeError
1. 如果对象有valueOf()方法并且返回元素值,javascript将返回值转换为数字作为结果
2. 否则,如果对象有toString()并且返回原始值,javascript将返回结果转换为数字作为结果
3. 否则,throws a TypeError
所有比较运算符都支持任意类型,但是比较只支持数字和字符串,所以需要执行必要的转换然后进行比较,转换规则如下:
- 如果操作数是对象,转换为原始值:如果valueOf方法返回原始值,则使用这个值,否则使用toString方法的结果,如果转换失败则报错
- 经过必要的对象到原始值的转换后,如果两个操作数都是字符串,按照字母顺序进行比较(他们的16位unicode值的大小)
- 否则,如果有一个操作数不是字符串,将两个操作数转换为数字进行比较
- 如果有操作数是对象,转换为原始值
- 此时如果有一个操作数是字符串,其他的操作数都转换为字符串并执行连接
- 否则:所有操作数都转换为数字并执行加法
- arguments所有函数中都包含的一个局部变量,是一个类数组对象,对应函数调用时的实参。如果函数定义同名参数会在调用时覆盖默认对象
- arguments[index]分别对应函数调用时的实参,并且通过arguments修改实参时会同时修改实参
- arguments.length为实参的个数(Function.length表示形参长度)
- arguments.callee为当前正在执行的函数本身,使用这个属性进行递归调用时需注意this的变化
- arguments.caller为调用当前函数的函数(已被遗弃)
- 转换为数组:
var args = Array.prototype.slice.call(arguments, 0);
- DOM事件包含捕获(capture)和冒泡(bubble)两个阶段:捕获阶段事件从window开始触发事件然后通过祖先节点一次传递到触发事件的DOM元素上;冒泡阶段事件从初始元素依次向祖先节点传递直到window
- 标准事件监听elem.addEventListener(type, handler, capture)/elem.removeEventListener(type, handler, capture):handler接收保存事件信息的event对象作为参数,event.target为触发事件的对象,handler调用上下文this为绑定监听器的对象,event.preventDefault()取消事件默认行为,event.stopPropagation()/event.stopImmediatePropagation()取消事件传递
- 老版本IE事件监听elem.attachEvent('on'+type, handler)/elem.detachEvent('on'+type, handler):handler不接收event作为参数,事件信息保存在window.event中,触发事件的对象为event.srcElement,handler执行上下文this为window使用闭包中调用handler.call(elem, event)可模仿标准模型,然后返回闭包,保证了监听器的移除。event.returnValue为false时取消事件默认行为,event.cancleBubble为true时取消时间传播
- 通常利用事件冒泡机制托管事件处理程序提高程序性能。
/**
* 跨浏览器事件处理工具。只支持冒泡。不支持捕获
* @author (qiu_deqing@126.com)
*/
var EventUtil = {
getEvent: function (event) {
return event || window.event;
},
getTarget: function (event) {
return event.target || event.srcElement;
},
// 返回注册成功的监听器,IE中需要使用返回值来移除监听器
on: function (elem, type, handler) {
if (elem.addEventListener) {
elem.addEventListener(type, handler, false);
return handler;
} else if (elem.attachEvent) {
var wrapper = function () {
var event = window.event;
event.target = event.srcElement;
handler.call(elem, event);
};
elem.attachEvent('on' + type, wrapper);
return wrapper;
}
},
off: function (elem, type, handler) {
if (elem.removeEventListener) {
elem.removeEventListener(type, handler, false);
} else if (elem.detachEvent) {
elem.detachEvent('on' + type, handler);
}
},
preventDefault: function (event) {
if (event.preventDefault) {
event.preventDefault();
} else if ('returnValue' in event) {
event.returnValue = false;
}
},
stopPropagation: function (event) {
if (event.stopPropagation) {
event.stopPropagation();
} else if ('cancelBubble' in event) {
event.cancelBubble = true;
}
},
/**
* keypress事件跨浏览器获取输入字符
* 某些浏览器在一些特殊键上也触发keypress,此时返回null
**/
getChar: function (event) {
if (event.which == null) {
return String.fromCharCode(event.keyCode); // IE
}
else if (event.which != 0 && event.charCode != 0) {
return String.fromCharCode(event.which); // the rest
}
else {
return null; // special key
}
}
};
function Shape() {}
function Rect() {}
// 方法1
Rect.prototype = new Shape();
// 方法2
Rect.prototype = Shape.prototype;
// 方法3
Rect.prototype = Object.create(Shape.prototype);
Rect.prototype.area = function () {
// do something
};
方法1:
- 优点:正确设置原型链实现继承
- 优点:父类实例属性得到继承,原型链查找效率提高,也能为一些属性提供合理的默认值
- 缺点:父类实例属性为引用类型时,不恰当地修改会导致所有子类被修改
- 缺点:创建父类实例作为子类原型时,可能无法确定构造函数需要的合理参数,这样提供的参数继承给子类没有实际意义,当子类需要这些参数时应该在构造函数中进行初始化和设置
- 总结:继承应该是继承方法而不是属性,为子类设置父类实例属性应该是通过在子类构造函数中调用父类构造函数进行初始化
方法2:
- 优点:正确设置原型链实现继承
- 缺点:父类构造函数原型与子类相同。修改子类原型添加方法会修改父类
方法3:
- 优点:正确设置原型链且避免方法1.2中的缺点
- 缺点:ES5方法需要注意兼容性
改进:
- 所有三种方法应该在子类构造函数中调用父类构造函数实现实例属性初始化
function Rect() {
Shape.call(this);
}
- 用新创建的对象替代子类默认原型,设置
Rect.prototype.constructor = Rect;保证一致性 - 第三种方法的polyfill:
function create(obj) {
if (Object.create) {
return Object.create(obj);
}
function f() {};
f.prototype = obj;
return new f();
}
-
MVVM是Model-View-ViewModel的缩写。MVVM是一种设计**。Model 层代表数据模型,也可以在Model中定义数据修改和操作的业务逻辑;View 代表UI 组件,它负责将数据模型转化成UI 展现出来,ViewModel 是一个同步View 和 Model的对象。在MVVM架构下,View 和 Model 之间并没有直接的联系,而是通过ViewModel进行交互,Model 和 ViewModel 之间的交互是双向的, 因此View 数据的变化会同步到Model中,而Model 数据的变化也会立即反应到View 上.ViewModel 通过双向数据绑定把 View 层和 Model 层连接了起来,而View 和 Model 之间的同步工作完全是自动的,无需人为干涉,因此开发者只需关注业务逻辑,不需要手动操作DOM, 不需要关注数据状态的同步问题,复杂的数据状态维护完全由 MVVM 来统一管理。
-
区别:原因就是mvc中Controller演变成mvvm中的viewModel mvc是DOM操作,MVVM(vue)演变为了数据驱动!
- 父组件与子组件传值 父组件通过标签上面定义传值 子组件通过props方法接受数据
- 子组件向父组件传递数据 子组件通过$emit方法传递参数
- 同级组件通信
- 把值赋值到一个公用的$vue实例上来访问
- Vuex
- 父子组件联系(举例A组件与B组件有一个公共联系组件C A是C的子组件 B是C的子组件 让C起到桥接的作用)
vue.js 是采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。
具体步骤:
-
需要observe的数据对象进行递归遍历,包括子属性对象的属性,都加上 setter和getter,这样的话,给这个对象的某个值赋值,就会触发setter,那么就能监听到了数据变化
-
compile解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图
-
Watcher订阅者是Observer和Compile之间通信的桥梁,主要做的事情是: 1、在自身实例化时往属性订阅器(dep)里面添加自己 2、自身必须有一个update()方法 3、待属性变动dep.notice()通知时,能调用自身的update()方法,并触发Compile中绑定的回调,则功成身退。
-
MVVM作为数据绑定的入口,整合Observer、Compile和Watcher三者,通过Observer来监听自己的model数据变化,通过Compile来解析编译模板指令,最终利用Watcher搭起Observer和Compile之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据model变更的双向绑定效果。
总共分为8个阶段创建前/后,载入前/后,更新前/后,销毁前/后。
- 创建前/后: 在beforeCreated阶段,vue实例的挂载元素$el和数据对象data都为undefined,还未初始化。在created阶段,vue实例的数据对象data有了,$el还没有。
- 载入前/后:在beforeMount阶段,vue实例的$el和data都初始化了,但还是挂载之前为虚拟的dom节点,data.message还未替换。在mounted阶段,vue实例挂载完成,data.message成功渲染。
- 更新前/后:当data变化时,会触发beforeUpdate和updated方法。
- 销毁前/后:在执行destroy方法后,对data的改变不会再触发周期函数,说明此时vue实例已经解除了事件监听以及和dom的绑定,但是dom结构依然存在
均是css的预编译。(suss为例描述,其他均出入不大) 使用步骤:
- 用npm 下三个loader(sass-loader、css-loader、node-sass)
- 在build目录找到webpack.base.config.js,在那个extends属性中加一个拓展.scss
- 还是在同一个文件,配置一个module属性
- 然后在组件的style标签加上lang属性 ,例如:lang=”scss”
有哪几大特性:
1、可以用变量,例如($变量名称=值); 2、可以用混合器,例如() 3、可以嵌套
- 路由变化页面数据不刷新问题
- setTimeout/setInterval(泛指异步回掉函数的this指向)this指向改变,无法用this访问VUe实例
- setInterval路由跳转继续运行并没有及时进行销毁
- vue 滚动行为用法,进入路由需要滚动到浏览器底部 头部等等
- 实现vue路由拦截浏览器的需求,进行 一系列操作 草稿保存等等
- v-once 只渲染元素和组件一次,优化更新渲染性能
- vue本地代理配置 解决跨域问题,仅限于开发环境
- 本地开发 没有任何问题 部署服务器 就404啊这些问题 具体问题的介绍,答案可以看我这篇文章
- 工作内容:
- Webpack间接可以看作模块打包机,通过分析你的项目结构,找到JavaScript模块以及其它的一些浏览器不能直接运行的拓展语言(Scss,TypeScript,es6/7等),并将其编译或打包为合适的格式供浏览器使用。
- Gulp/Grunt是一种能够优化前端的开发流程的工具,而WebPack是一种模块化的解决方案,不过Webpack的优点使得Webpack在很多场景下可以替代Gulp/Grunt类的工具
- 工作方式(方法):
- Webpack:把你的项目当做一个整体,通过一个给定文件(如:index.js),Webpack将从这个文件开始找到你的项目的所有依赖文件,使用loaders处理它们,最后打包为一个(或多个)浏览器可识别的JavaScript文件。
- Grunt和Gulp:在一个配置文件中,指明对某些文件进行类似编译,组合,压缩等任务的具体步骤,工具之后可以自动替你完成这些任务。
-
- grunt是针对js任务管理工具,构建工具
- 优势:出来早 社区成熟 插件全
- 缺点:配置复杂 效率低 (cpu占用率高)
-
- gulp 基于流的自动化构建工具
- 优点:配置简单 效率高 流式工作(把输入的某些东西,经过某个管道处理后,输出需要的形式。)
- 缺点:出现晚 插件少
-
- webpack 模块打包机
- 优点:模块化
- 缺点:配置复杂 (中文文档不是特别齐全 算不算缺点- -。)
- task() : 执行的任务
- src() : 输入的文件 (源自哪个文件)
- pipe() : 执行的管道方法,接在源后面或者其他管道后面
- dest() : 输出的位置
- 检查(检测)js gulp-jshint
- scss => css gulp-sass
- jsx => js gulp-react
- es6 => es5 gulp-babel
- 文件拷贝 gulp-copy
- 文件合并 gulp-concat
- 压缩js gulp-uglify
- 压缩css gulp-cssmin
- 压缩html gulp-htmlmin
- 压缩img gulp-imagemin
- 入口(entry)==== 入口起点(entry point)指示 webpack 应该使用哪个模块,来作为构建其内部依赖图的开始。进入入口起点后,webpack 会找出有哪些模块和库是入口起点(直接和间接)依赖的。
- 出口(output)===== output 属性告诉 webpack 在哪里输出它所创建的 bundles,以及如何命名这些文件,默认值为 ./dist。基本上,整个应用程序结构,都会被编译到你指定的输出路径的文件夹中。
- loader (可以理解为编译器)====== loader 让 webpack 能够去处理那些非 JavaScript 文件(webpack 自身只理解 JavaScript)。loader 可以将所有类型的文件转换为 webpack 能够处理的有效模块,然后你就可以利用 webpack 的打包能力,对它们进行处理。
- 插件(plugins)===== 插件则可以用于执行范围更广的任务。插件的范围包括,从打包优化和压缩,一直到重新定义环境中的变量。插件接口功能极其强大,可以用来处理各种各样的任务.
- 模式(mode)===== 通过配置mode参数可以启用相应模式下的 webpack 内置的优化,其中有 development (开发)或 production (生产/上线) 俩种模式