This a Rocket-Chip processor (based on Chipyard) with its shared L2 cache dynamically randomized to thwart conflict-based cache side-channel attacks. The original proposal for dynamically randomizing classic (non-skewed) set-associative caches was published in our S&P'21 paper, while its implementation on the Rocket-Chip's LLC would soon appear on IEEE Transactions on Computers. The implementation is open-sourced by this repo under the same BSD 3-Clause License adopted by Chipyard.
- Wei Song, Zihan Xue, Jinchi Han, Zhenzhen Li, and Peng Liu. Randomizing set-associative caches against conflict-based cache side-channel attacks. IEEE Transactions on Computers, accepted, 2024. [PDF]
- Wei Song, Boya Li, Zihan Xue, Zhenzhen Li, Wenhao Wang, and Peng Liu. Randomized last level caches are still vulnerable to cache side channel attacks! But we can fix it. In Proceedings of the IEEE Symposium on Security and Privacy (S&P), Online, pp. 955–969, May 2021. [DOI, PDF]
- 薛子涵, 解达, 宋威. 基于RISC-V的新型硬件性能计数器. 计算机系统应用, 2021, 30(11): 3–10.
(Zihan Xue, Da Xie, and Wei Song. Hardware performance counter based on RISC-V. Computer Systems & Applications, vol. 30, no. 11, pp. 3–10, 2021)[WEB]
If used for research, please cite the following publication:
@article{Song2024,
author = {Wei Song and Zihan Xue and Jinchi Han and Zhenzhen Li and Peng Liu},
journal = {IEEE Transactions on Computers},
title = {Randomizing set-associative caches against conflict-based cache side-channel attacks},
year = {2024},
pages = {14},
note = {accepted}
}
Conflict-based cache side-channel attacks against the last-level cache (LLC) is a widely exploited method for information leaking. Since the LLC is shared between all processing cores, it allows a malicious software to trigger controlled conflicts, such as evicting a specific cache set with attackers' data, to infer security-critical information of a victim program. They have been utilized to recover cryptographic keys, break the sandbox defense, inject faults directly into the DRAM, and extract information from the supposedly secure SGX enclaves.
Cache partitioning and randomization are two of the main defense methodologies.
Cache partitioning used to be the only effective defense against conflict-based cache side-channel attacks abusing the LLC. It separates security-critical data from normal data in the LLC; therefore, attackers cannot evict security-critical data by triggering conflicts using normal data. However, cache partitioning is ineffective when security-critical data cannot be easily separated from normal data or normal data become the target. It also reduces the autonomy of the LLC which might in turn hurt performance for some applications. Finally, cache partitioning relies on specific operating system (OS) code to identify security-critical data, which means the OS must be trusted.
Cache randomization has recently been accepted as a promising defense. In a randomized cache, the mapping from memory addresses to cache set indices is randomized, forcing attackers to slowly find eviction sets at runtime rather than directly calculating cache set indices. Even when eviction sets are found, attackers cannot easily tell which cache sets are evicted by them. However, cache randomization alone does not defeat conflict-based cache side-channel attacks but only increases difficulty and latency. For this reason, dynamic remapping is used to limit the time window available to attackers, and cache skews have been introduced to further increase the difficulty in finding eviction sets.
- [Wang2007] proposed the first cache randomization scheme which could be used to protect L1 caches.
- [Song2018] proposed a static cache randomization scheme to protect all cache levels, although this work was not peer-reviewed (a poster published in the 8th RISC-V Workshop).
- [Qureshi2018] firmly revived the concept of cache randomization and applied it to LLCs with dynamic remapping (named CEASER).
- [Bodduna2020] successfully pointed out that the linear block cipher utilized by CEASER was flawed, forcing almost all following randomization schemes to use cryptographic ciphers instead.
- Around the same time, [Werner2019] and [Qureshi2019] proposed to randomize skewed caches rather than classic set-associative caches for better protection.
- [Bourgest2020] successfully pointed out that attackers could still leak information through prolonged attacks on randomized skewed caches.
- [Song2021] successfully pointed out that the filter effect of inner cache levels is overlooked and the security claims of randomized skewed caches were over-optimistic.
- [Saileshwar2021] proposed MIRAGE, which claimed to fully eliminate attacker-controlled associativity evictions by over-providing metadata space and introducing multi-stepped Cuckoo relocation into randomized skewed caches.
- [Unterluggauer2022] proposed Chameleon cache, which introduced a victim cache in a skewed cache to provide an approximation to a fully associative cache (similar to MIRAGE).
- This work provides the first hardware implementation of a dynamically randomized set-associative LLC capable of thwarting all existing eviction set searching algorithms.
This implementation is significantly different with the seemly most advanced randomization schemes (MIRAGE and Chameleon) in several aspects:
Instead of advocating the use of randomized skewed caches, we cautiously argue that randomized non-skewed (classic set-associative) caches can be sufficiently strengthened and possess a better chance to be adopted in the near future than their skewed counterparts:
- The performance benefit of using skewed caches is not proven by commercial processors and introducing it purely for security purpose might be ill-fated.
- The area and runtime performance overhead of MIRAGE is heavy.
- The non-skewed set-associative caches can be made sufficiently safe against existing conflict-based cache side-channel attacks.
Existing cache randomization schemes trigger remaps after a certain amount of LLC accesses. During attacks, most memory accesses hit in inner caches and become invisible to the LLC. This unfortunately distorts the observation of the LLC. Compared with cache accesses, cache evictions are both unavoidable and visible to the LLC. Triggering remaps by counting LLC evictions is at least as effective as counting LLC accesses. Even better, since the LLC miss rate of normal applications is much lower than attacks, less remaps would be triggered during normal operations.
The largest performance overhead of dynamic cache randomization comes form the data loss during a remap. Our experiment estimates that 40~50% cache blocks in an LLC are evicted during the remap process, which is why frequent remaps can hurt performance significantly. We use a multi-step relocation scheme to reduce this cost. When a cache block is remapped to a fully occupied cache set, instead of evicting a cache block, this block is further remapped. The data loss drops to just 10% as a result.
We find that both PPP and GE algorithms can be reliably detected, because they need to prune a large set of random addresses into a minimal eviction set and exceptional number of evictions are incurred on the targeted cache set during the prune process. An active attack can be detected accordingly by constantly monitoring the distribution of evictions among cache sets. As an example, the following figure shows two attacks utilizing the GE algorithm to search eviction sets. After applying a Z-standardization, the unbalanced distribution of cache evictions among cache set is easily noticeable.
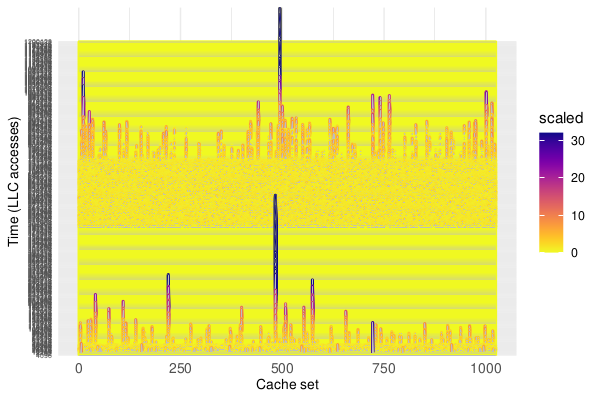
By triggering extra remaps when an attack is detected in action, all existing attacks (searching eviction sets at runtime) are defeated.
Is it really necessary to use a multi-cycle cryptographic cipher for randomizing cache indices? No, we think, even though everyone else is doing so. According to our estimation, every extra cycle consumed by the cryptographic cipher prolongs CPI by 0.4%, and the fastest cryptographic cipher requires 4 to 6 cycles. We propose a single-cycle hasher which should be secured enough for the purpose of randomizing the cache indices.
The concept of randomizing a set-associated LLC cache is depicted as follows:
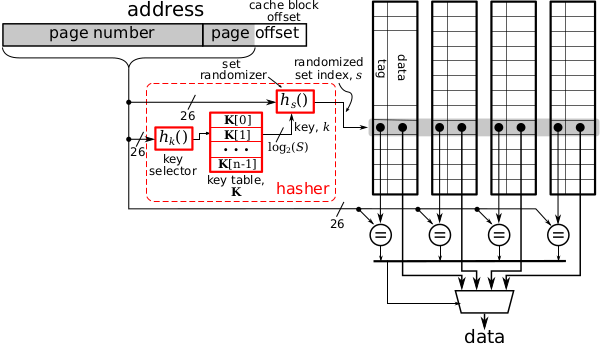
For each cache block, the cache set index is decided by the hasher using the physical address as the input. Since the keys utilized by the hasher are both generated and managed by hardware, attackers have no easy way to decipher the hasher or guess keys. During a remap, both the key table and the key selector are regenerated by hardware. All cache blocks are relocated to their new cache sets by a multi-step relocation procedure. As a result, the mapping between cache blocks and cache sets are totally reshuffled and any mapping already deciphered by an attacker is nullified.
Our implementation in the Rocket-Chip is shown below as all added modules colored in red. As you can see, the implementation is straight-forward. The hasher is added to pre-calculate the randomized cache set index before a cache request (from inner caches) is accepted by the request queue. A remapper controller triggers a remap either an attack is detected or a preset number of evictions occur.
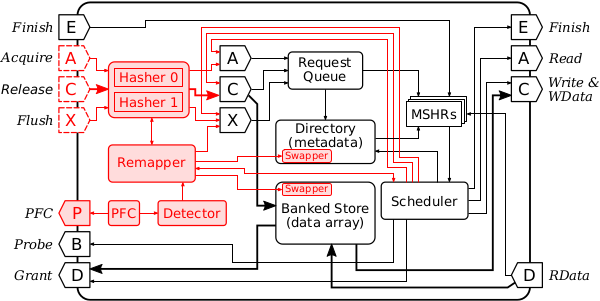
A dualcore Rocket-Chip (32KB PLRU L1-I and L1-D, 1MB 1024-set 16-way PLRU L2) has been ported to a Digilent Genesys-2 FPGA board. The processing cores run at 75MHz while the off-chip memory (1GB) runs at 900MHz.
We have reproduced all existing eviction set searching algorithms on FPGA, including GE, PPP, CT, CT-fast and W+W. Our experiment shows that all these algorithms fail to work (success rate < 0.01%).
We have done both FPGA and ASIC evaluation. For the FPGA implementation, the logic overhead is 15.8% while the BRAM overhead is only 1.9%. On ASIC, the overall overhead is only 2.84%.
We have run the SPEC CPU 2006 benchmark on FPGA. The LLC miss rate rises by 1.11%, while CPI overhead is around 0.9%.
By measuring the FPGA power, the power overhead introduced by LLC randomization is around 2.5%.