L4dy-1.0
Speech-enabled goal-oriented dialogue system with rule-based context determination and very limited features (for now).
[Phase-1]:STT conversion [Phase-2]:Context extraction [Phase-3]:TTS conversion [chain]:All the phases chained
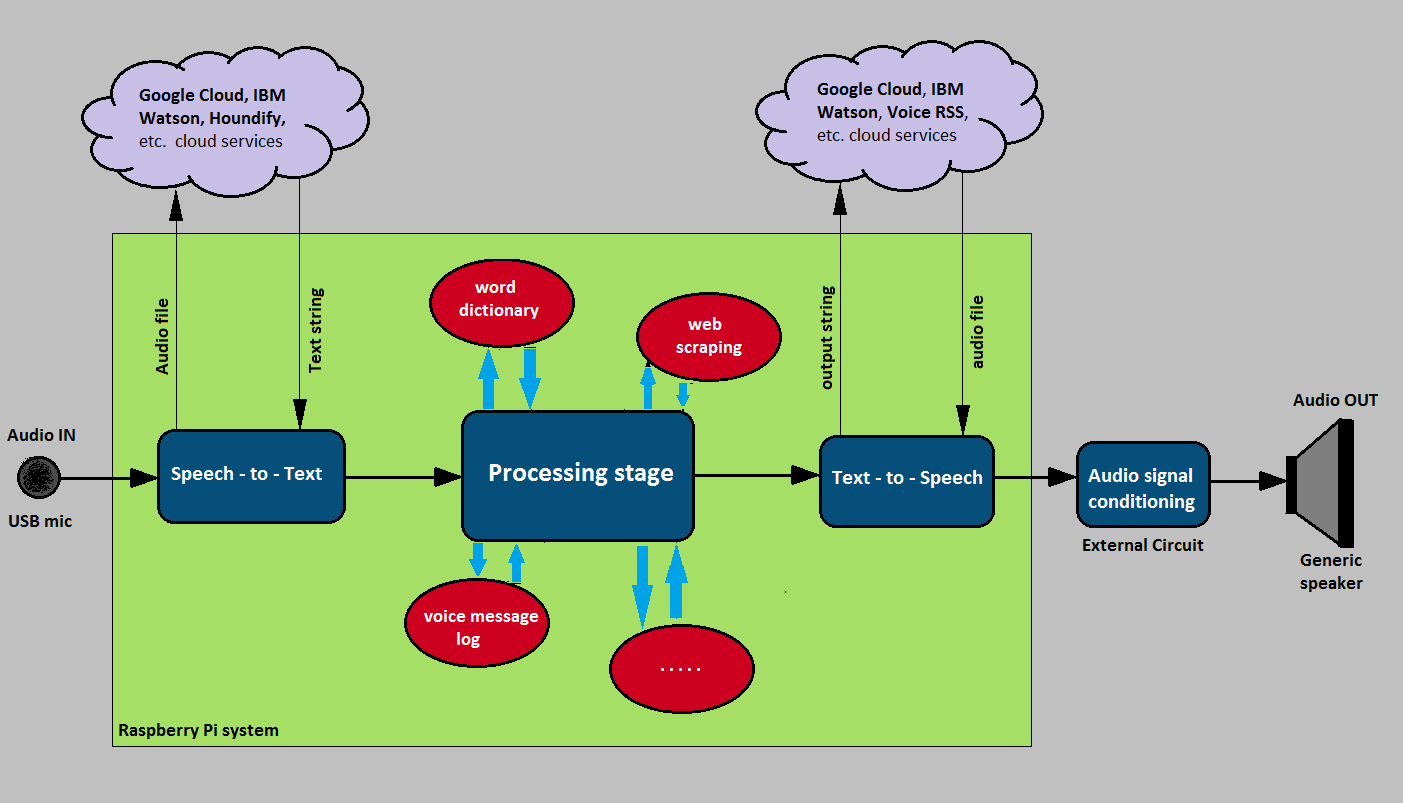
Breakdown of system operation:
-
Speech-to-text conversion of the user’s query: The audio data captured from the microphone has to be converted to a character string before doing any further processing. Speech to text conversion tasks can be done in a number of different ways – using a conversion engine (such as PocketSphinx), deploying trained neural models (such as RNNs and LSTMs) locally, or using cloud services. Here, the STT conversion is carried out using the Houndify cloud API.The recorded audio is obtained and is transfered to the Houndify cloud API. After the conversion, the cloud API returns a string which is the transcript of the user’s speech query. This string is now ready for further processing.
-
Processing stage: In order to determine the nature of the user’s query, a set of rules and words are written using which the transcript string is parsed and broken down into its essence. During parsing, the system decides which predefined task or “app” should be called, and the extracted essence of the string is passed to the particular app. Predefined tasks / Apps - The aforementioned predefined tasks or “apps” are, basically, Python scripts each having a unique function. Initially, the system has three apps, meaning the number of diverse tasks it can perform is just three.
-
Text-to-Speech conversion of the reply string: The reply string returned from the previous stage now has to be converted into speech (audio).The Voice-RSS TTS cloud service is used here for the same. The voicerss_tts Python library provides classes to interact with the cloud API. The reply string is passed to the cloud API and an audio file is returned after conversion, which is now ready to be played back to the user.