SyncDreamer
SyncDreamer: Generating Multiview-consistent Images from a Single-view Image

Project page | Paper
- Inference codes and pretrained models.
- Training codes.
Preparation for inference
- Install packages in
requirements.txt. We test our model on a 40G A100 GPU with 11.1 CUDA and 1.10.2 pytorch. - Download checkpoints at here.
Inference
- Make sure you have the following models.
SyncDreamer
|-- ckpt
|-- ViT-L-14.ckpt
|-- syncdreamer-pretrain.ckpt- (Optional) Predict foreground mask as the alpha channel. I use Paint3D to segment the foreground object interactively.
We also provide a script
foreground_segment.pyusingcarvekitto predict foreground masks and you need to first crop the object region before feeding it toforeground_segment.py. We may double check the predicted masks are correct or not.
python foreground_segment.py --input <image-file-to-input> --output <image-file-in-png-format-to-output>- Run SyncDreamer to produce multiview-consistent images.
python generate.py --ckpt ckpt/syncdreamer-pretrain.ckpt \
--input testset/aircraft.png \
--output output/aircraft \
--sample_num 4 \
--cfg_scale 2.0 \
--elevation 30 \
--crop_size 200Explanation:
--ckptis the checkpoint we want to load--inputis the input image in the RGBA form. The alpha value means the foreground object mask.--outputis the output directory. Results would be saved tooutput/aircraft/0.pngwhich contains 16 images of predefined viewpoints perpngfile.--sample_numis the number of instances we will generate.--sample_num 4means we sample 4 instances fromoutput/aircraft/0.pngtooutput/aircraft/3.png.--cfg_scaleis the classifier-free-guidance.2.0is OK for most cases. We may also try1.5.--elevationis the elevation angle of the input image in degree. As shown in the following figure,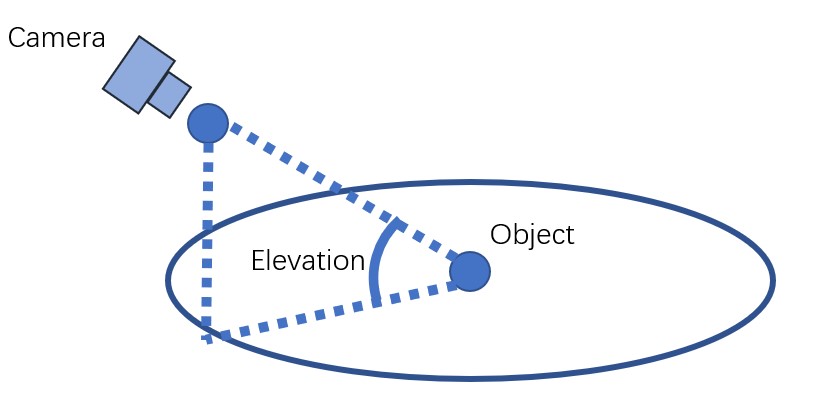
- We assume the object is locating at the origin and the input image is captured by a camera of the elevation. Note we don't need a very accurate elevation angle but a rough value in [-10,40] degree is OK, e.g. {0,10,20,30}.
--crop_sizeaffects how we resize the object on the input image. The input image will be resize to 256*256 and the object region is resized tocrop_sizeas follows.crop_size=-1means we do not resize the object but only directly resize the input image to 256*256.crop_size=200works in most cases. We may also try180or150.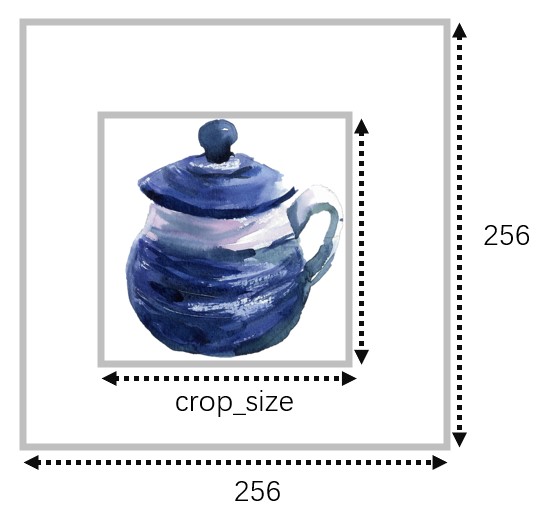
- Suggestion: We may try different
crop_sizeandelevationto get a best result. SyncDreamer does not always produce good results but we may generate multiple times with different--seedand select the most reasonable one. - testset_parameters.sh contains the command I used to generate results.


- Run a NeuS or a NeRF for 3D reconstruction.
# train a neus
python train_renderer.py -i output/aircraft/0.png \
-n aircraft-neus \
-b configs/neus.yaml \
-l output/renderer
# train a nerf
python train_renderer.py -i output/aircraft/0.png \
-n aircraft-nerf \
-b configs/nerf.yaml \
-l output/rendererExplanation:
-icontains the multiview images generated by SyncDreamer. Since SyncDreamer does not always produce good results, we may need to select a good generated image set (from0.pngto3.png) for reconstruction.-nmeans the name.-lmeans the log dir. Results will be saved to<log_dir>/<name>i.e.output/renderer/aircraft-neusandoutput/renderer/aircraft-nerf.- Before training, we will run
carvekitto find the foreground mask in_init_dataset()inrenderer/renderer.py. The resulted masked images locate atoutput/renderer/aircraft-nerf/masked-*.png. Sometimes,carvekitmay produce incorrect masks. - A rendering video will be saved at
output/renderer/aircraft-neus/rendering.mp4oroutput/renderer/aircraft-nerf/rendering.mp4. - We will only save a mesh for NeuS but not for NeRF, which is
output/renderer/aircraft-neus/mesh.ply.
Acknowledgement
We have intensively borrow codes from the following repositories. Many thanks to the authors for sharing their codes.
Citation
If you find this repository useful in your project, please cite the following work. :)
@article{liu2022gen6d,
title={SyncDreamer: Learning to Generate Multiview-consistent Images from a Single-view Image},
author={Liu, Yuan and Lin, Cheng and Zeng, Zijiao and Long, Xiaoxiao and Liu, Lingjie and Komura, Taku and Wang, Wenping},
journal={arXiv preprint arXiv:2309.03453},
year={2023}
}