使用SageMaker+XGBoost,将时间序列转换为监督学习,完成预测性维护的实践
关键字:SageMaker;XGBoost;Python;滑窗;滑动窗口方法;时间序列预测转化为监督学习问题;将多元时间序列数据转换为监督学习问题;如何用Python将时间序列问题转化为有监督学习问题;时间序列预测的机器学习模型;
[TOC]
目录
一、前言
二、需求分析与预测结果
三、数据处理与特征工程
四、SageMaker+XGBoost 训练与朝参数调优
五、模型部署与使用
六、结论
七、引用零、前言
《预测性维护》是传统制造业常见AI场景。过去多年,制造业一直在努力提高运营效率,并避免由于组件故障而导致停机。通常使用的方法是:
- 通常采用的方法是使用“物理传感器(标签)”做数据连接,存储和大屏上进行了大量重复投资,以监视设备状况并获得实时警报。
- 主要的数据分析方法是单变量阈值和基于物理的建模方法,尽管这些方法在检测特定故障类型和操作条件方面很有效,但它们通常会错过通过推导每台设备的多元关系而检测到的重要信息。
- 借助机器学习,可以提供从设备的历史数据中学习的数据驱动模型。主要挑战在于,ML的项目投资和工程师培训,实施这样的机器学习解决方案既耗时又昂贵。
AWS Sagemaker提供了一个简单有效的解决方案,就是使用Sagemaker+XGboost完成检测到异常的设备行为,实现《预测性维护》的场景需求。
- 使用了“滑窗”方法进行数据集的重构,并配合XGBoost算法,将多元时间序列数据集转换为监督学习问题(复杂问题转换为简单问题);
- 使用Sagemaker Studio各项功能(自动机器学习Autopilot、自动化的调参 Hyperparameter tuning jobs、多模型终端节点multi-model endpoints等)加速XGBoost超参数优化的速度,有效提高模型准确度;
- 使用Sagemaker Studio 完成数据预处理与特征工程:
- 1)探索相关性;
- 2)缩小特征值范围;
- 3)将海量数据分为几批进行预处理,以避免服务器内存溢出;
- 4)数据清理,滑动窗口清除无效数据;
- 5)过滤数据,解决正负样本不平衡的问题;
- 使用Sagemaker+XGboost训练了6个预测模型,分别覆盖提前5、10、20、30、40、50分钟,演示实验结果。
首先您需要关注的是ML工作流程,是如何使用Amazon SageMaker和XGBoost完成典型ML工作流程中的每个步骤。 在此过程中,您将看到Amazon SageMaker如何使用各种功能来提高ML的效率并同时降低成本。
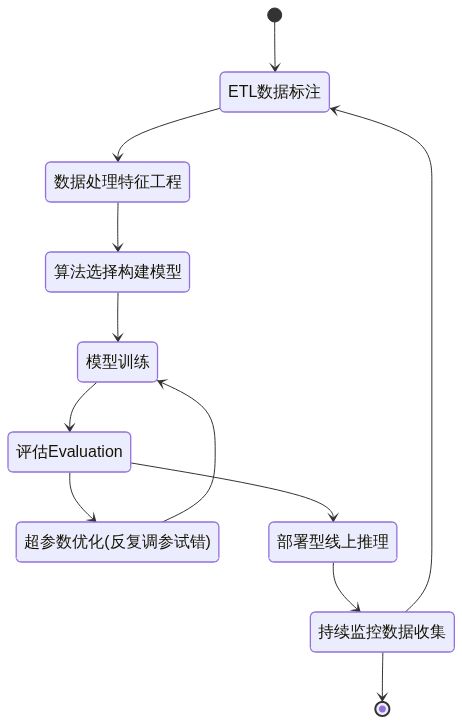
SageMaker + XGBoost的机器学习生命周期
stateDiagram-v2
[*] --> ETL数据标注
ETL数据标注 --> 数据处理特征工程
数据处理特征工程 --> 算法选择构建模型
算法选择构建模型 --> 模型训练
模型训练 --> 评估Evaluation
评估Evaluation -->超参数优化(反复调参试错)
超参数优化(反复调参试错) --> 模型训练
评估Evaluation --> 部署型线上推理
部署型线上推理 --> 持续监控数据收集
持续监控数据收集 --> ETL数据标注
持续监控数据收集 --> [*]
一、需求分析与预测结果
1)预测维护的实验数据集
说明:
- 文件名:121007060_1.csv
- 数据规模:180W行 含故障代的关联性分析与提起周期预测(数据):
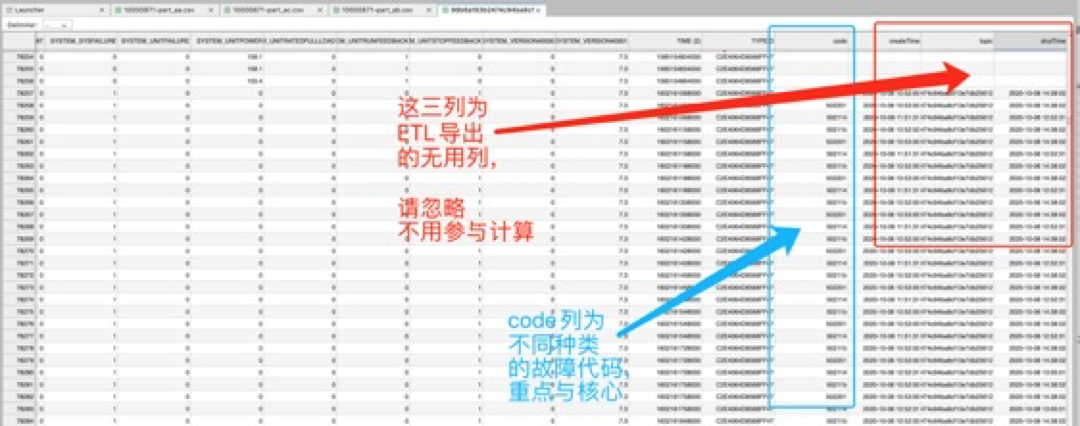
- 数据说明:error code列为故障代码列,已经将设备故障代码(单独为一列)合并到设备状态记录中去,方便训练,请下图说明
- 业务目标:对报错设备(error code字段)的关联性分析与提前故障周期预测;
- 图例(重点):请忽略红色标记的无用字段;
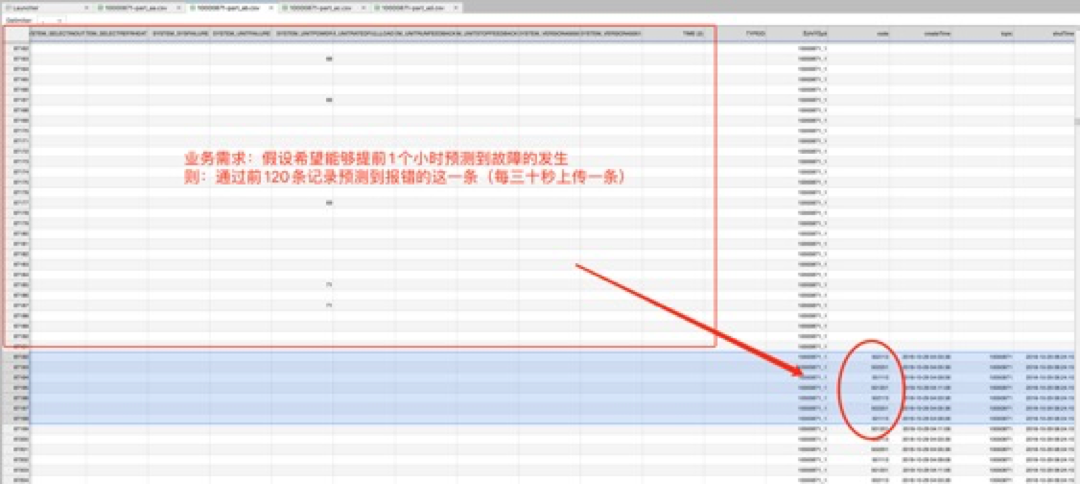
2)预测维护需求说明
(下图)
3)特征工程
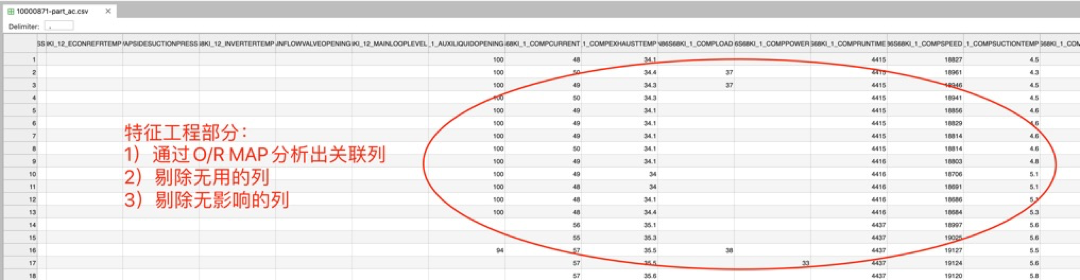
通过图表分析,已经找到的相关性列如下:(请参考源码)
4)使用“滑窗”方法,将特征工程后的时间序列数据集
通过滑动窗口转化为有监督学习数据集(如下),然后使用XGBoost做回归训练;

5)预测结果
- 《预测性维护》需求场景验证成功,用户现有的数据集可以实现故障提前周期的预测;
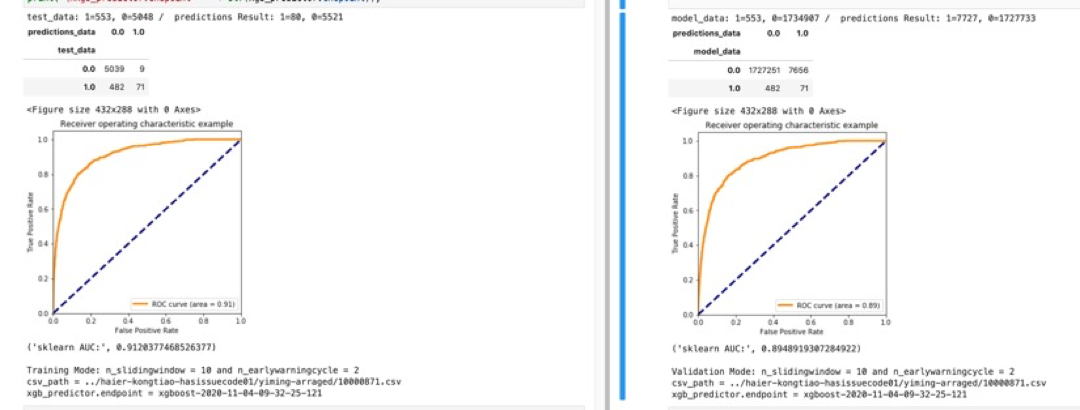
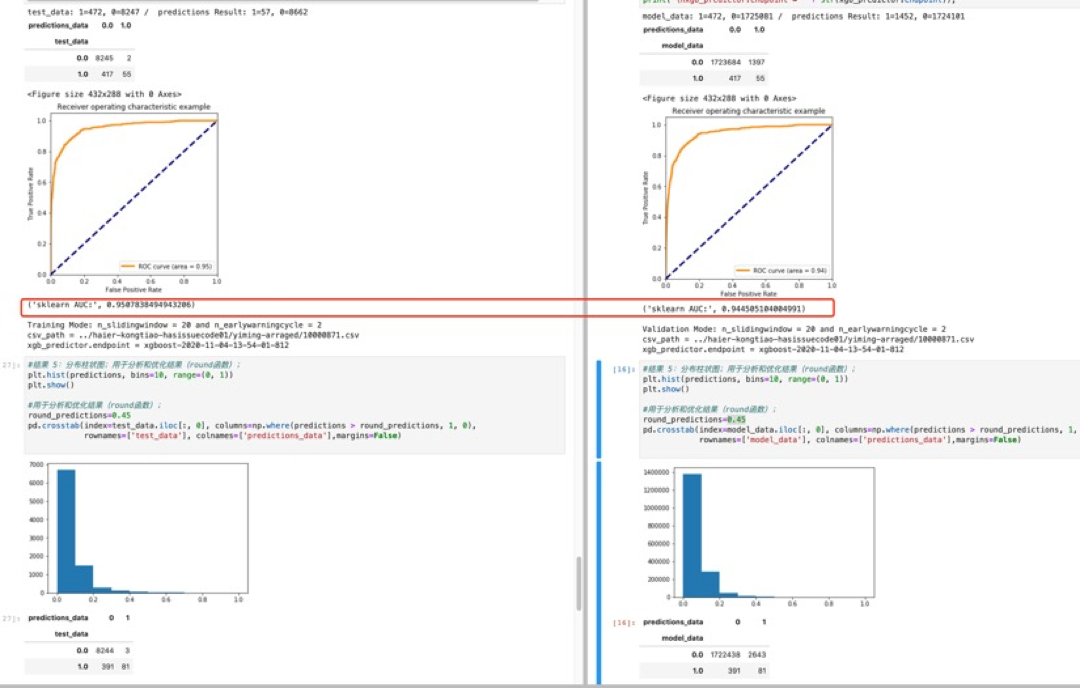
- 数据预处理中《滑窗》次数越多,预测准确度越高。超过100个《滑窗》提高了预测模型的准确性。(100个滑窗的数据集,分别为5、10、20、30、40、50分钟的6个预测模型)
- 提前周期从5分钟到50分钟,预测《有故障》的准确率较高,召回率有待提高。
- 在反复数据预处理和XGBoost调参训练后,使用Sagemaker将预测准确度AUC从0.79提高到0.93;
索取实验数据,请点击这里。me@liangyiming.com
二、滑动窗口原理解析
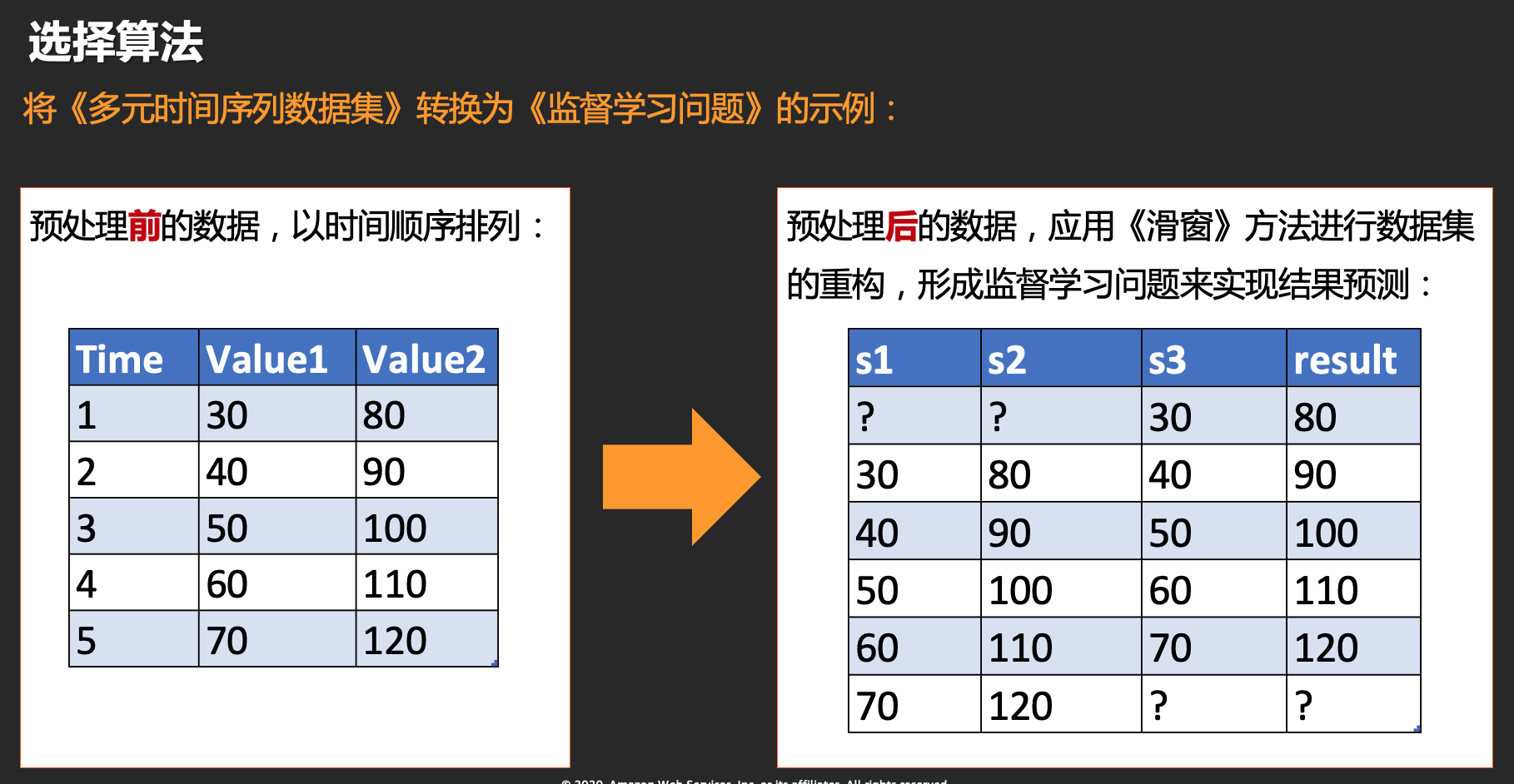
滑动窗口方法,是使用先前的时间步长预测下一个时间步长,在统计资料中它也称为滞后法。使用滑动窗口方法,可以将《多元时间序列数据集》转换为《监督学习问题》,应该怎么实现呢? 定义问题通常是解决任何问题的第一步。我们需要先从问题的定义讲起:
时间序列问题的类型
关于时间序列问题,我们可以将问题分为以下几类:
-
回归或分类:要预测的变量是数字的还是(字母)分类的。
-
非结构化或结构化:数据是否具有实际值?如果它确实具有实际值和结构化的列,我们将其称为“结构化”。否则,其称为非结构化图像。
-
单变量 或多变量。除了日期列外,如果只有一列存储值,我们将其称为单变量 。如果date列之外还有多个列,我们将其称为多变量。
-
单步或者多步。如果我们要预测第二天,我们将其称为单步。如果我们要预测未来两天或更长时间,则将其称为多步骤。
实验数据集的类型:
- 回归
- 结构化
- 多变量
- 多步
| Time | Value1 | Value2 | 时间序列类型 | |
|---|---|---|---|---|
| 1 | 30 | 80 | 回归 | |
| 2 | 40 | 90 | 结构化 | |
| 3 | 50 | 100 | 多变量 | |
| 4 | 60 | 110 | 多步 | |
| 5 | 70 | 120 |
使用滑动窗口方法转换数据
滑动窗口方法是基础,把一个时间序列问题转化为监督学习的问题。滑动窗口方法的定义是使用先前的时间步长预测下一个时间步长。这里举例说明如何将多元数据转换为监督学习问题。
原数据集:
| Time | Value1 | Value2 |
|---|---|---|
| 1 | 30 | 80 |
| 2 | 40 | 90 |
| 3 | 50 | 100 |
| 4 | 60 | 110 |
| 5 | 70 | 120 |
让我们应用滑动窗口方法:
| s1 | s2 | s3 | result |
|---|---|---|---|
| ? | ? | 30 | 80 |
| 30 | 80 | 40 | 90 |
| 40 | 90 | 50 | 100 |
| 50 | 100 | 60 | 110 |
| 60 | 110 | 70 | 120 |
| 70 | 120 | ? | ? |
通过数据集的重构,完成形成监督学习问题,从而实现预测Value2(result字段)。
BTW:这很有趣。据我所知,除了人工神经网络之外,没想到有其他的监督学习算法可以预测两个变量。
让我继续,实现多步预测。
对于预测性维护场景,真实的需要,预测多步比预测单步要价值大得多(提前1小时发现可能出现的故障,价值大雨提前1分钟发现故障)。下面是使用滑动窗口方法转换变量数据进行多步预测的示例:
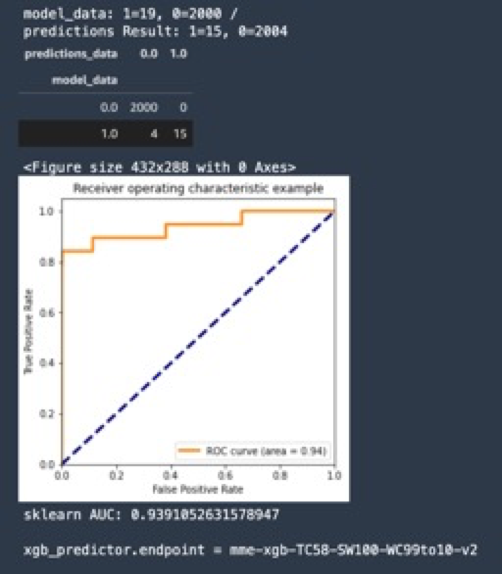
滑动窗口方法在实验数据集的验证结果:
针对实验数据集,将滑窗的数量从10 提升到30,可以显著观察到故障识别准确度发生了提升。
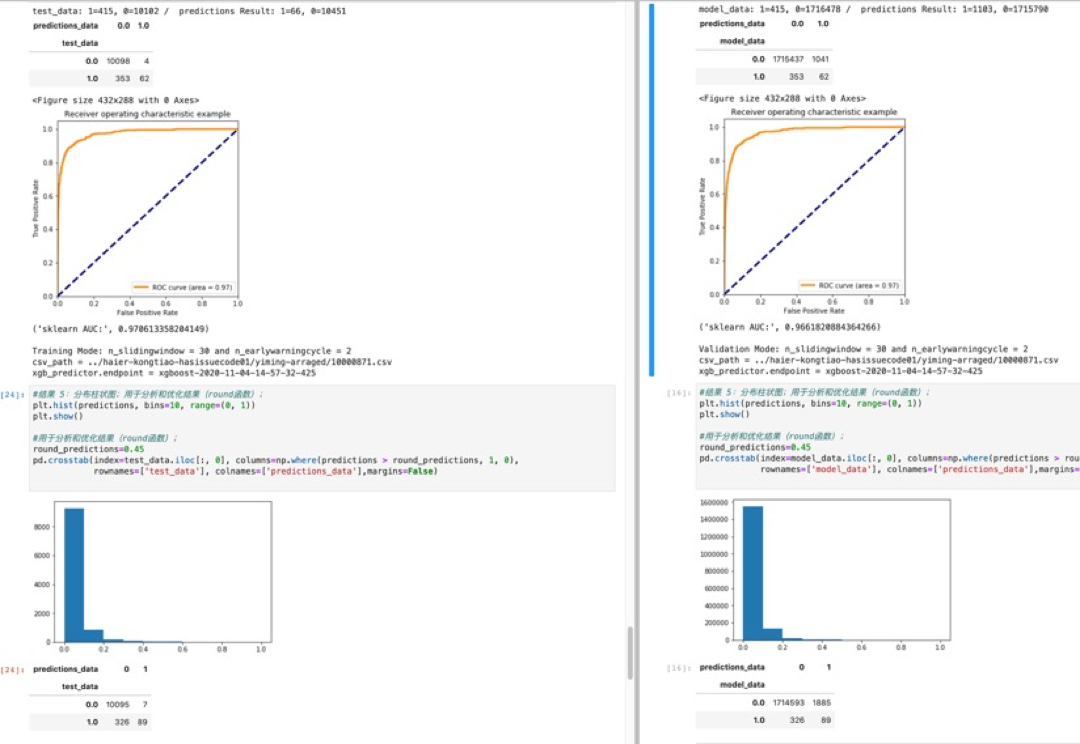
三、数据处理与特征工程
ETL数据标注 数据处理 特征工程
Step01_SageMaker_XGBoost-convert-Time-Series-into-Supervised-Learning.ipynb
四、SageMaker+XGBoost 训练与超参数调优
算法选择构建模型 模型训练 超参数优化(反复调参试错) 评估Evaluation
Step02_SageMaker_XGBoost_Tuningjob.ipynb
五、模型部署与使用
部署模型线上推理 持续监控数据收集
Step03_SageMaker_XGBoost_predict_multimodel.ipynb
六、结论
- 《预测性维护》需求场景验证成功,用户现有的数据集可以实现故障提前周期的预测;
- 数据预处理中《滑窗》次数越多,预测准确度越高。超过100个《滑窗》提高了预测模型的准确性。(100个滑窗的数据集,分别为5、10、20、30、40、50分钟的6个预测模型)
- 提前周期从5分钟到50分钟,预测《有故障》的准确率较高,召回率有待提高。
- 在反复数据预处理和XGBoost调参训练后,使用Sagemaker将预测准确度AUC从0.79提高到0.93;
- AUC指标表现良好,意味着模型质量较高;ROI曲线图也证明了AUC的结果;
七、引用
引用reference:
- 机器学习中梯度提升算法的简要介绍 https://machinelearningmastery.com/gentle-introduction-gradient-boosting-algorithm-machine-learning/
- 时间序列预测转化为监督学习问题 https://machinelearningmastery.com/time-series-forecasting-supervised-learning/
- 如何用Python将时间序列问题转化为有监督学习问题 https://machinelearningmastery.com/convert-time-series-supervised-learning-problem-python/
- How To Backtest Machine Learning Models for Time Series Forecasting如何回测时间序列预测的机器学习模型 https://machinelearningmastery.com/backtest-machine-learning-models-time-series-forecasting/
- How to Use XGBoost for Time Series Forecasting https://machinelearningmastery.com/xgboost-for-time-series-forecasting/