With the prevalence of social media, people are more familiar with publicly sharing their opinions these days. Some people even become content creators on major social media platforms, such as Instagram and YouTube. Therefore, these websites are ideal resources for sentiment analysis. By deploying the technique, the efficiency of social monitoring and brand marketing are enhanced. Creators and brands can perceive the viewers' emotion provoked by the content they create, and further decide whether there are adjustments to make.
To analyze the contents, we should also be aware of the "stop words". There are several existing stop word lists, and we select the list provided by *nltk --- Natural Language Toolkit *(Bird et al., 2009) in this stage of the process. The research is about exploring the existing tools and collecting 200 comments from 2 YouTube videos as the corpus to perform lexicon-based sentiment analysis.
The research is done with the following processes:
- Data Collection
- Data Pre-processing
- Analyze the sentiments with and without stop words using VADER.
Data Collection
The data are retrieved from YouTube Data API. 200 comments are retrieved from 2 Youtube trending videos in the United States ---
- Paddington Bear joins the Queen for afternoon tea at Buckingham Palace
- Details emerge about suspected gunman after Texas shooting l GMA.
Data Pre-processing
The unprocessed comments are tangled. Thus, we processed them by removing null values, special characters, stop words and converting them into lower cases. After the preprocessing of data, we begin our analysis.
Scoring with VADER
As previously mentioned, the lexicon list organized by VADER is also validated by humans. According to the developer of VADER, the human raters are all "pre-screened and trained" (Hutto & Gilbert, 2014) They independently rated a word's sentiment on the scale from -4 to +4. In this case, -4 represents "Extremely Negative", +4 means "Extremely Positive", and 0 stands for "Neutral". There is also a compound score in VADER. It is the sum of the scores, and further normalized to between -1 and 1. The polarity is then defined ---
- positive sentiment: compound score >= 0.05
- neutral sentiment: compound score > -0.05 and compound score < 0.05
- negative sentiment: compound score <= -0.05
The same data is going through two processes ---
- Analyze only with VADER
- Analyze with VADER and remove stop words from NLTK
With the polarities of the comments, we can compare the results, and see how well VADER analyzes.
positive 24 positive 24
negative 68 negative 65
neutral 8 neutral 11
Name: Polarity Name: polarity (without stopwords)
Fig. 1 Polarity Frequencies of Comments with and without stop words.
From Fig. 1, we conclude that 68% and 65% are negative comments, depending on the existence of the stop words. The data also indicates that the mismatches are possibly caused by them.
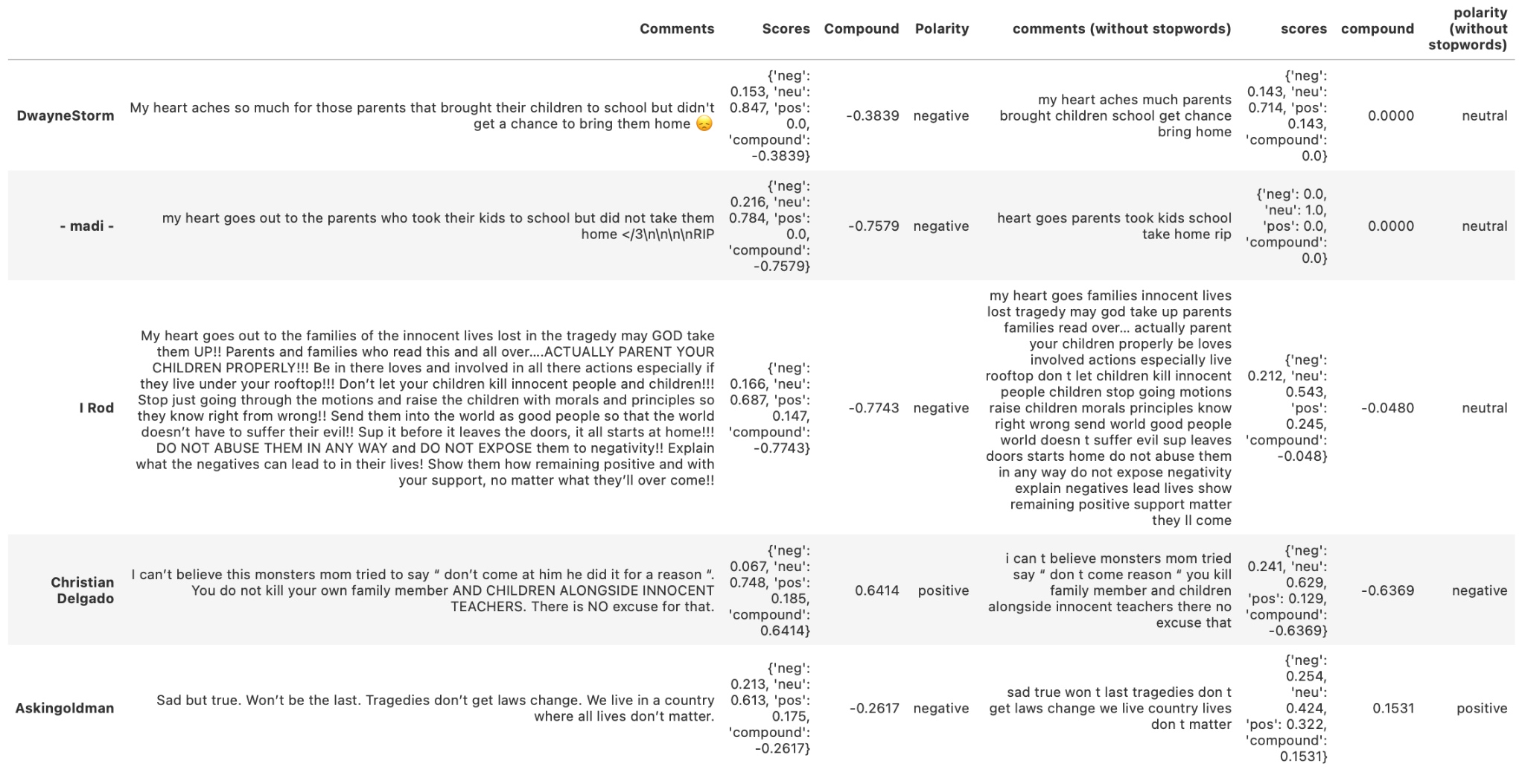 Fig. 1-1 Mismatched Polarity of the Texas Shooting Video
Fig. 1-1 Mismatched Polarity of the Texas Shooting Video
positive 94 positive 95
negative 3 negative 2
neutral 3 neutral 3
Name: Polarity Name: polarity (without stopwords)
Fig. 2 Polarity Frequencies of Comments with and without stop words.
 Fig. 2-1 Mismatched Polarity of the Paddington Bear Joins the Queen Video.
Fig. 2-1 Mismatched Polarity of the Paddington Bear Joins the Queen Video.
 Fig. 2-2 Negative Comments of the Paddington Bear Joins the Queen Video.
Fig. 2-2 Negative Comments of the Paddington Bear Joins the Queen Video.
From Fig. 2, we conclude that the Paddington Bear joins the Queen video receives mostly positive feedback, with 94% and 95% positive comments. The significant difference in polarity made the negative comments completely distinct. Fig. 2-2 shows the comments that are labeled as negative.
-
Removing Stop Words might result in different polarities. From the above results, we discovered that taking away stop words can also be confusing for the machine. Although it removes the meaningless words, it might also eradicate the exact emotions creators and readers wanted to express. Fig. 2-2 also shows that some comments without stop words can no longer form a sentence. isnt adorable she sport was labeled positive only because of the word adorable and the happy emoticon. Strictly speaking, the machine might not realize it's a joyful comment.
-
Stop words with symbolic meanings Since the Paddington Bear joins the Queen receives such celebrated feedback,we are curious about what the negative comments are about. The comment I got tears in my eyes when i watched this. is supposed to express the viewer's touched feelings. However, the word tear creates a symbolic meaning of sadness and crying, which results in a totally different evaluation. The evaluation does not show consistency with the comment, This made me tear up a little. I love the Queen and I'm not even British. Tear appear in both comments, but they categorize differently. It is likely that in the latter comment, other words strengthen the positive emotion, such as love.
-
VADER versus VADER + remove stop words Among the comments that mismatched (Fig. 1-1, Fig. 2-1) , I consider myself a human rater. To judge the comments that are inconsistent in polarity, I would say VADER is undeniably a powerful tool. Before discovering VADER, I tried to preprocess the data with TextBlob. Without the classification of the emoticons, it is timely for users to filter the emojis. As for the stop words, it is undoubtedly that we contemplate whether removing them is a good idea.
The discussion demonstrates that lexicon-based sentiment analysis is still subject to the context. Without the context, emotions cannot be precisely expressed. Stop word is proven by the study that it is one of the aspects that we can still work on. To correctly extract the essential words depends on human intelligence. What we could do is to draw up guidelines and principles for the machines to apply.
From this study, we learn lots of sentiment analysis tools that are handy to use. Although it did not provide 100% accuracy when interpreting the emotions, it saved our time, and showed its potential in the combination of natural language processing and linguistics. We hope one day, the digital assistant can understand our feelings even without asking.
Bonta, V., Kumaresh, N., & Janardhan, N. (2019). A Comprehensive Study on Lexicon Based Approaches for Sentiment Analysis. Asian Journal of Computer Science and Technology, 8(S2), 1--6. https://doi.org/10.51983/ajcst-2019.8.s2.2037
Bird, S., Klein, E., & Loper, E. (2009). Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit (1st ed.). O'Reilly Media.
Tausczik, Y. R., & Pennebaker, J. W. (2009). The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods. Journal of Language and Social Psychology, 29(1), 24--54. https://doi.org/10.1177/0261927x09351676
TextBlob: Simplified Text Processing --- TextBlob 0.16.0 documentation. (2018). Steven Loria. https://textblob.readthedocs.io/en/dev/
Hutto, C., & Gilbert, E. (2014). VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. *Proceedings of the International AAAI Conference on *Web and Social Media, 8(1), 216-225. Retrieved from https://ojs.aaai.org/index.php/ICWSM/article/view/14550
Beri, A. (2021, December 14). SENTIMENTAL ANALYSIS USING VADER - Towards Data Science. Medium. https://towardsdatascience.com/sentimental-analysis-using-vader-a3415fef7664
Ranjan, A. (2021, December 23). Sentiment Analysis of a Youtube Video - Analytics Vidhya. Medium. https://medium.com/analytics-vidhya/sentiment-analysis-of-a-youtube-video-63ced6b7b1c4