[TOC]
将pdf转换为txt文件,并且检查其分栏排版,以及是否有图像、表格。
见 examples/example.py
import pdf2txt
src_file = '../data/逍遥游.pdf'
dest_file = './逍遥游.txt'
pdf2txt.convert(src_file, dest_file)- pdf文字转成txt
- 检查是否有图像,有则报错
- 检查是否有表格
- 检查排版分栏
- txt中换行符用 LF or CRLF? 目前服务器通常为linux系统,所以格式采用LF(
\n)。 - pdf中排版换行并非文字逻辑换行时是否去除?
- 根据下列规则,满足则去除换行符:换行符前没有标点符号,并且最后一个字符位置接近右侧边缘。
- 问题:标题、子标题等最后也没有标点符号,但是需要换行
- 问题:对于混合双栏(标题单栏、内容双栏),很难定义“右侧边缘”
- 去除header/footer?
- 很难判断是否为页眉页脚,改为接受一个文本框区域,只在该区域提取文本
- 支持simple和layout两种pdf解析模式,关于layout模式见下面“按自然阅读顺序提取文本”一节说明
- 是否能和ocr结合?
- 比较和pdf转word的效果
有多个字符表示类似含义,在不同系统上默认的方式不同,但是现代文本编辑器一般都兼容这些方式。
Unix和OS X使用LF(也称为NL)作为换行符。LF在编程语言里通常表示为转义符\n,他的ASCII值为10或者0xA。
老的Mac上使用CR作为换行符。CR通常表示为转义符\r,他的ASCII值为13或者0xD。
Windows使用CR+LF作为换行符。他是前面两个字符串联使用\r\n。
还要一个特殊字符叫换页符(Form Feed),通常用来表示换到下一页,但是现在用的不多。
https://stackoverflow.com/questions/3091524/what-are-carriage-return-linefeed-and-form-feed
CR: Carriage return means to return to the beginning of the current line without advancing downward. The name comes from a printer's carriage, as monitors were rare when the name was coined. This is commonly escaped as "\r", abbreviated CR, and has ASCII value 13 or 0xD.
LF or NL: Linefeed means to advance downward to the next line; however, it has been repurposed and renamed. Used as "newline", it terminates lines (commonly confused with separating lines). This is commonly escaped as "\n", abbreviated LF or NL, and has ASCII value 10 or 0xA. CRLF (but not CRNL) is used for the pair "\r\n".
FF: Form feed means advance downward to the next "page". It was commonly used as page separators, but now is also used as section separators. Text editors can use this character when you "insert a page break". This is commonly escaped as "\f", abbreviated FF, and has ASCII value 12 or 0xC.
As control characters, they may be interpreted in various ways.
The most important interpretation is how these characters delimit lines. Lines end with NL on Unix (including OS X), CRLF on Windows, and CR on older Macs. Note the shift in meaning from LF to NL, for the exact same character, gives the differences between Windows and Unix, which is also why many Windows programs use CRLF to separate instead of terminate lines. Many text editors can read files in any of these three formats and convert between them, but not all utilities can.
Form feed is much less commonly used. As page separator, it can only come between lines or at the start or end of the file.
https://pymupdf.readthedocs.io/en/latest/the-basics.html#extract-text-from-a-pdf
https://pymupdf.readthedocs.io/en/latest/app1.html
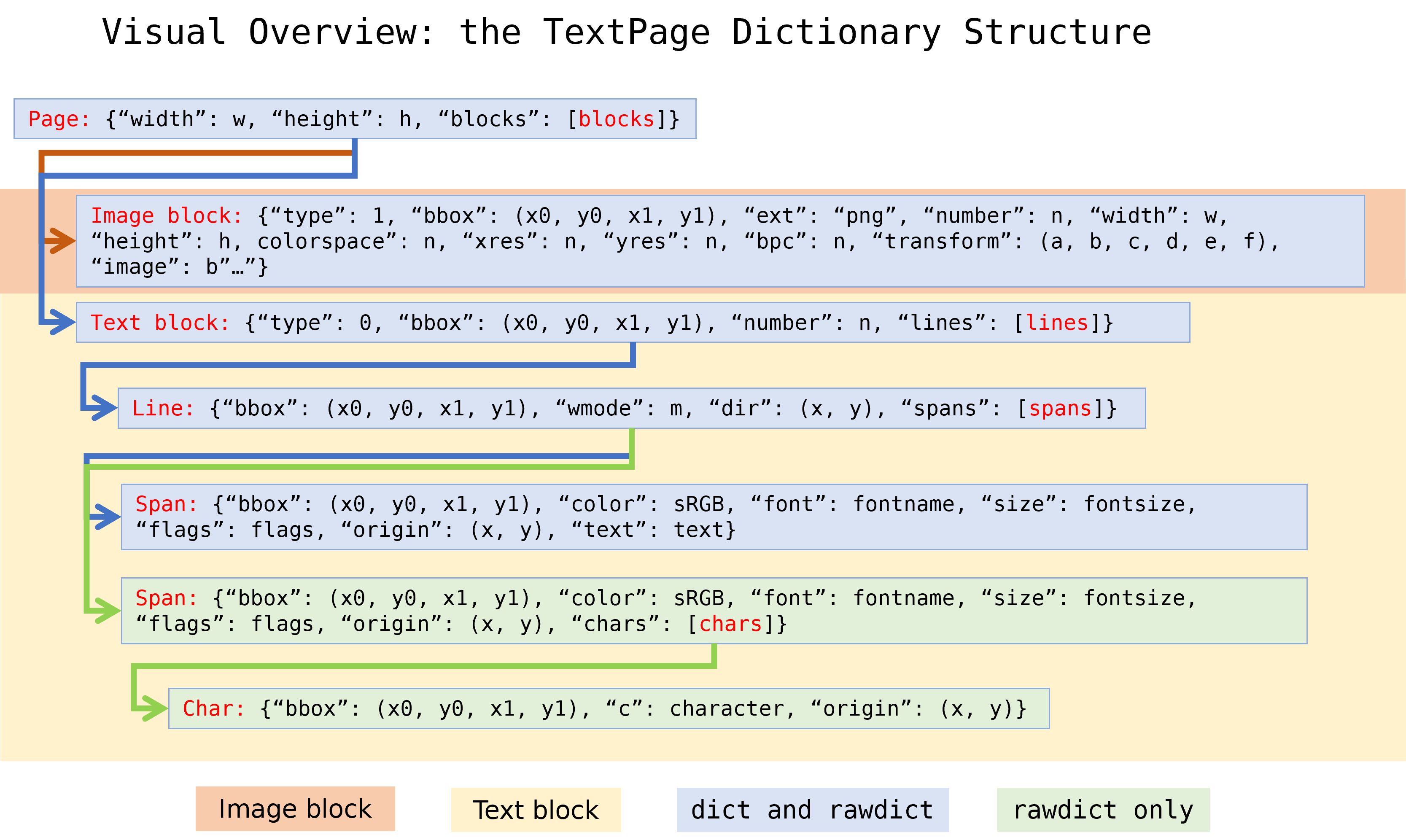
TextPage is one of (Py-) MuPDF’s classes. It is normally created (and destroyed again) behind the curtain, when Page text extraction methods are used, but it is also available directly and can be used as a persistent object. Other than its name suggests, images may optionally also be part of a text page:
<page>
<text block>
<line>
<span>
<char>
<image block>
<img>
A text page consists of blocks (= roughly paragraphs).
A block consists of either lines and their characters, or an image.
A line consists of spans.
A span consists of adjacent characters with identical font properties: name, size, flags and color.
TextPage结构见下图,来自 https://pymupdf.readthedocs.io/en/latest/textpage.html#structure-of-dictionary-outputs
其他材料 https://pymupdf.readthedocs.io/en/latest/tutorial.html#working-with-pages
https://pymupdf.readthedocs.io/en/latest/page.html
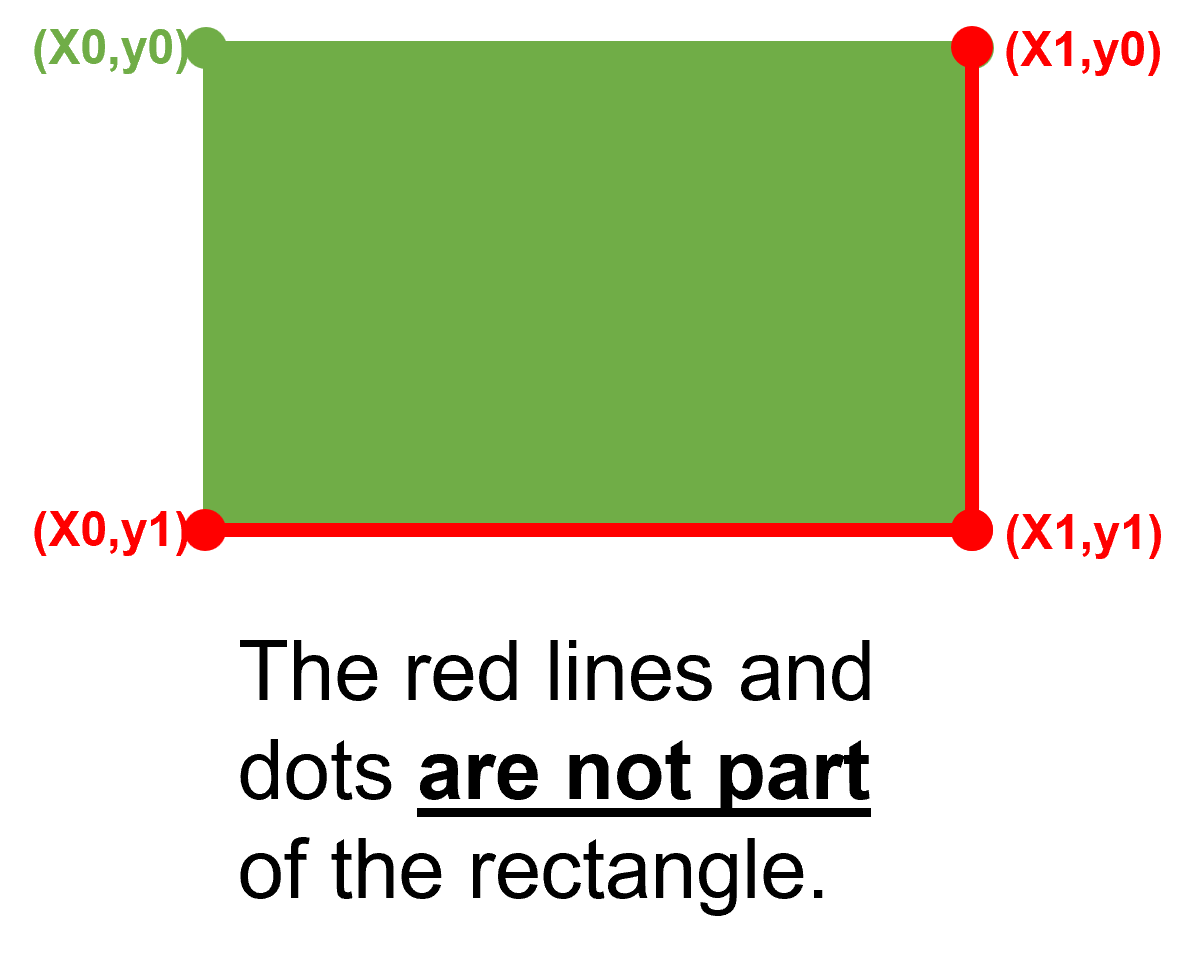
https://pymupdf.readthedocs.io/en/latest/rect.html#Rect.round
https://pymupdf.readthedocs.io/en/latest/recipes-drawing-and-graphics.html
- 最简单的提取方法,会按pdf文件添加元素的顺序进行提取。
- 而有时候为了防止copy,一些pdf会打乱添加元素的顺序,但是排版上不影响阅读。这样简单地抽取文本就无法按照正常的阅读顺序排列,见这个例子。
- 为了解决上面的情况,有一些办法,一个简单的方法是讲文本Block根据坐标位置排序,按从上到下从左到右的顺序,像这个例子
- 另外,有一个复杂一些的方法,这个代码中的
page_layout函数考虑到排版格式,大概流程是
这些信息来源于 https://github.com/pymupdf/PyMuPDF-Utilities/blob/master/text-extraction/README.md.
没有简单的方法能准确地判断表格在页面中的位置,这通常是一个需要AI、ML技术来解决的复杂问题。 但是对于一些简单的情况,可以使用PyMuPDF提供的vector graphics分析工具来判断表格的存在,比如是否有直线、矩形框等。 这些信息来源于 https://github.com/pymupdf/PyMuPDF-Utilities/blob/master/table-analysis/README.md.
更多信息见:
https://pymupdf.readthedocs.io/en/latest/recipes-text.html#how-to-extract-tables-from-documents
https://github.com/pymupdf/PyMuPDF-Utilities/blob/master/examples/extract-table/README.md
https://pymupdf.readthedocs.io/en/latest/page.html#Page.get_textpage_ocr
https://helpx.adobe.com/cn/acrobat/using/create-form.chromeless.html
https://helpx.adobe.com/cn/acrobat/using/create-form.chromeless.html