主要利用python中的requests,BeautifulSoup库从人人都是产品经理网站爬取36000篇文章并存入MongoDB数据库。整个爬虫用到的库还有json——用于解析从网页获取的json格式字串,re——借助re库实现正则表达式功能,对于爬取的字串进行预处理,pymongo——与数据库建立连接,把爬取的数据存入MongoDB数据库,numpy、urllib和multiprocessing。
主体部分定义了若干爬取函数,主要有:
- 获取初始页HTML和解析初始页的函数,用于获取详情页的url列表
- 获取详情页HTML和解析详情页的函数,用于获取文章的信息,并返回一个文章信息的字典
- main函数,首先,调用获取详情的URL列表的函数,取得详情页url,然后,利用for循环对每个详情页url调用获取文章信息的函数,取得文章内容,最后把文章内容存入MongoDB数据库
- 开启多线程,提高爬虫效率,整个爬虫总共获取了36000条记录,耗时2小时30分钟,如果没有开启多线程,估计要爬一天
整个爬虫应用的库和定义的函数详情如下表所示:
| 主要用到的Python库或爬虫定义的函数 | 作用或实现的功能 |
|---|---|
| requests | 模拟网页发出get请求取得页面HTML |
| numpy | 从请求头中随机获取一个头部信息 |
| urllib | 解析字符串,构造请求头部信息 |
| BeautifulSoup | 解析网页HTML代码,获取需要的信息,如URL、文章信息 |
| json | 解析json格式的页面,当获取到的页面代码是json字串时,就需要用json库对其反序列化 |
| re | 进行字符串的操作,对一些爬取下来的信息进行预处理 |
| pymongo | 与MongoDB数据库建立连接,把请求下来的信息存入数据库 |
| multiprocessing | 开启多线程,提高爬虫效率 |
| 函数:get_index_page() | 获取初始页HTML |
| 函数:parse_index_page() | 解析初始页HTML,取得详情页URL |
| 函数:get_detail_page() | 获取详情页HTML |
| 函数:parse_detail_page() | 解析详情页HTML,获得文章内容,返回文章字典 |
| 函数:main() | 调用get_index_page()和parse_index_page()取得详情页URL列表,遍历URL列表调用get_detail_page()和parse_detail_page()取得文章内容字典,最后存入MongoDB数据库 |
爬虫的源代码在product.py文件中
# 引入pymongo和pandas
from pymongo import MongoClient
import pandas as pd与MongoDB建立连接,取得数据并转化成DataFrame格式
client = MongoClient()
db = client.product
cursor = db.everyone_product_more.find()
df = pd.DataFrame(list(cursor))大致看下数据的情况,总共有12个指标:'_id', 'article', 'author', 'comment', 'good', 'star', 'tag', 'time','title', 'total_article', 'total_watch', 'watch',其中第一列_id是MongoDB生成的每条记录的唯一标识,可以删除,其余的分别是:文章内容,文章作者,文章评论量,文章点赞量,文章收藏量,文章标签,文章发表时间,文章的标题,文章作者总共发表的文章数量,文章作者所有文章的浏览量,文章的浏览量,共11个关于文章信息的指标。目前,所有指标的数据类型均为object,后续需要转换。
df.head()| _id | article | author | comment | good | star | tag | time | title | total_article | total_watch | watch | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5ad8a175bb7e360c709ff511 | 如果说运营是辆急速飞驰的跑车,那么数据就是驱动它前行的齿轮。随着互联网人口红利逐步消失,砸钱... | [] | 11 | [] | [] | [] | 2017-08-20 14:00-17:00 | [] | None | None | [] |
| 1 | 5ad8a175bb7e36203c5d5775 | \n双11真的是一年之中最便宜的吗?\n双11又要到了,无数人开始在购物车里屯货,大晚上抱着... | 周得狗 | 12 | 30 | 74 | [双十一, 案例分析, 用户心理] | 2017-10-24 | 为什么“双11”的产品会让你感觉很便宜? | 6篇 | 4.5万 | 1.1万 |
| 2 | 5ad8a175bb7e3628ec305e9b | 人人都是产品经理的网站里有大量的面经,说的都很好。在这个躁动的月份,我也想分享一些关于产品经... | 辰哥不瞎说 | 1 | 8 | 6 | [2年, 产品工作, 产品求职, 初级] | 2018-04-19 | 产品经理面试中的“潜规则” | 2篇 | 1.1万 | 739 |
| 3 | 5ad8a175bb7e36223812a826 | AR或许成为IP转化的新动力,各大IP都会有AR虚拟形象的需求。近两年,短视频十分火热。短视... | 雷锋网\n | [] | 2 | 24 | [3年, AR, 中级, 短视频应用] | 2018-01-18 | AR是短视频的下一个风口吗?我们体验了数十个AR短视频应用 | 94篇 | 66.4万 | 3374 |
| 4 | 5ad8a175bb7e3628ec305e9c | 在玩抖音的时候,有没有辛苦拍出来的视频却不受欢迎?那一起来学学这七种方法~最近朋友圈常见到这... | 纸盒小卡车\n | [] | 0 | 0 | [3年, 中级, 抖音, 营销] | 2018-04-19 | 七种“写作手法”教你称霸抖音营销 | 185篇 | 2.3m | 317 |
# 查看数据信息
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 36000 entries, 0 to 35999
Data columns (total 12 columns):
_id 36000 non-null object
article 36000 non-null object
author 36000 non-null object
comment 36000 non-null object
good 36000 non-null object
star 36000 non-null object
tag 36000 non-null object
time 36000 non-null object
title 36000 non-null object
total_article 35600 non-null object
total_watch 35600 non-null object
watch 36000 non-null object
dtypes: object(12)
memory usage: 3.3+ MB
# 删除_id
df = df.drop('_id', axis=1)df.isnull().sum()article 0
author 0
comment 0
good 0
star 0
tag 0
time 0
title 0
total_article 400
total_watch 400
watch 0
dtype: int64
文章作者总共发表的文章数量和文章作者所有文章的浏览量分别有400条记录缺失,再查看一下缺失行的详细信息,缺失都比较严重,因此考虑把缺失行全部删除,而相对36000条数据量,删除400条缺失信息是可以接受的
删除缺失值。再查看下数据信息,总共还有35600条记录。
df = df.dropna()df.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 35600 entries, 1 to 35999
Data columns (total 11 columns):
article 35600 non-null object
author 35600 non-null object
comment 35600 non-null object
good 35600 non-null object
star 35600 non-null object
tag 35600 non-null object
time 35600 non-null object
title 35600 non-null object
total_article 35600 non-null object
total_watch 35600 non-null object
watch 35600 non-null object
dtypes: object(11)
memory usage: 3.3+ MB
- 文章作者字段在结尾处存在换行符,清理掉
df['author'] = df['author'].str.strip()- 评论量字段存在[],表示列表的字符,应该是评论量为0,并且这个字段需要转化成数字类型。
df['comment'].valuesarray([12, 1, list([]), ..., list([]), list([]), list([])], dtype=object)
利用map结合匿名函数清理comment字段
df['comment'] = df['comment'].map(lambda e: 0 if type(e)==list else int(e))- good和star字段转化成数字类型即可
df[['good', 'star']] = df[['good', 'star']].astype('int')用DataFrame的describe先看下三个数值型字段的统计描述,发现收藏量star的值有存在小于0的情况,不合理。
df.describe()| comment | good | star | |
|---|---|---|---|
| count | 35600.000000 | 35600.000000 | 35600.000000 |
| mean | 3.092809 | 15.604803 | 61.381067 |
| std | 5.793591 | 37.438179 | 124.130612 |
| min | 0.000000 | 0.000000 | -2.000000 |
| 25% | 0.000000 | 3.000000 | 2.000000 |
| 50% | 1.000000 | 7.000000 | 20.000000 |
| 75% | 4.000000 | 16.000000 | 66.000000 |
| max | 99.000000 | 2160.000000 | 4213.000000 |
- 定位到star小于0的值,并改成0
df.loc[df['star'] < 0, 'star'] = 0- time字段是时间格式,将其转换成datetime格式
df['time'] = pd.to_datetime(df['time'], format = '%Y-%m-%d')df.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 35600 entries, 1 to 35999
Data columns (total 11 columns):
article 35600 non-null object
author 35600 non-null object
comment 35600 non-null int64
good 35600 non-null int32
star 35600 non-null int32
tag 35600 non-null object
time 35600 non-null datetime64[ns]
title 35600 non-null object
total_article 35600 non-null object
total_watch 35600 non-null object
watch 35600 non-null object
dtypes: datetime64[ns](1), int32(2), int64(1), object(7)
memory usage: 3.0+ MB
用正则表达式查看total_article字段带有字符串‘篇’的条数,发现每条记录都含有‘篇’字,需要去掉并转化成数字类型。
df['total_article'].str.contains('篇').sum()35600
- 利用map结合匿名函数去除total_article字段中‘篇’并转化成数字类型
df['total_article'] = df['total_article'].map(lambda e: int(e.strip('篇')))对于total_watch的处理就麻烦些,因为它带有中文单位‘万’和m(百万),因此我们需要去除‘万’并乘以10000,去除m并乘以1000000
带'万'字符和'm'字符的记录数分别有16516和17887条,总共34403条
df['total_watch'].str.contains('万').sum()16516
df['total_watch'].str.contains('m').sum()17887
df['total_watch'].str.contains('[万m]').sum()34403
- 当然,清理这个字段的方法不止一种,我觉得最简单的一种是定义一个清理函数,然后结合map方法进行清理,如下:
但是这个方法有个问题,可能会超出notebook默认的数据处理能力,而无法进行,解决办法是需要到notebook配置文件重新设置这个值。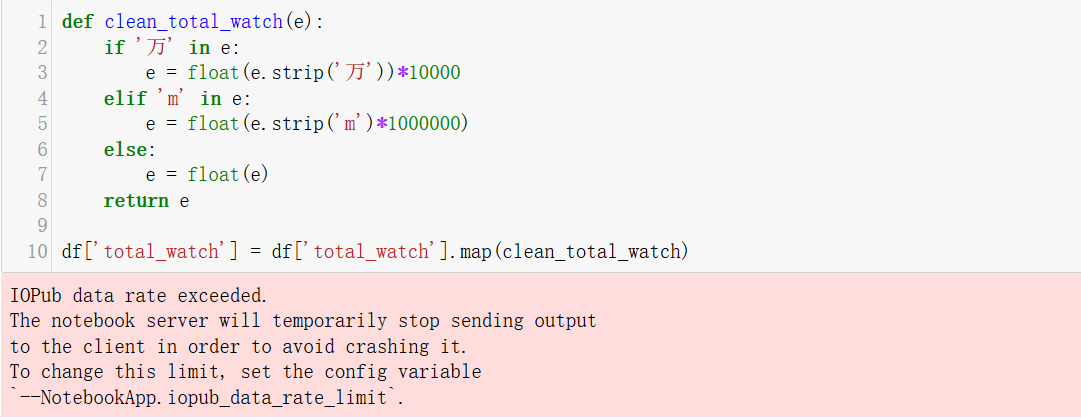

def clean_total_watch(e):
if '万' in e:
e = float(e.strip('万'))*10000
elif 'm' in e:
e = float(e.strip('m'))*1000000
else:
e = float(e)
return e
df['total_watch'] = df['total_watch'].map(clean_total_watch)- 还有一种办法稍微复杂些,但是不会有数据处理能力的限制。利用正则表达式把数字和单位分开成两列,然后把数字和单位相乘。
df[['author_watch', 'unit']] = df['total_watch'].str.extract('([\d.]+)(\D+)?', expand=False)
df['author_watch'] = df['author_watch'].astype('float')
df.loc[df['unit'] == '万', 'unit'] = 10000
df.loc[df['unit'] == 'm', 'unit'] = 1000000
df.loc[df['unit'].isnull(), 'unit'] = 1
df['unit'] = df['unit'].astype('int')
df['author_watch'] = df['author_watch'] * df['unit']- 清理浏览量watch字段,刚刚定义的清理函数就能派上用途了,因为watch字段和total_watc字段情况一样,能够应用上这个函数。
df['watch'] = df['watch'].map(clean_total_watch)至此,整个数据的清理工作就基本完成了。再看看数据的基本情况,总共11个字段,其中6个是数值类型的数据,1个时间格式数据,还有4个字符串格式数据。
df.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 35600 entries, 1 to 35999
Data columns (total 11 columns):
article 35600 non-null object
author 35600 non-null object
comment 35600 non-null int64
good 35600 non-null int32
star 35600 non-null int32
tag 35600 non-null object
time 35600 non-null datetime64[ns]
title 35600 non-null object
total_article 35600 non-null int64
total_watch 35600 non-null float64
watch 35600 non-null float64
dtypes: datetime64[ns](1), float64(2), int32(2), int64(2), object(4)
memory usage: 3.0+ MB
df.describe()| comment | good | star | total_article | total_watch | watch | |
|---|---|---|---|---|---|---|
| count | 35600.000000 | 35600.000000 | 35600.000000 | 35600.000000 | 3.560000e+04 | 3.560000e+04 |
| mean | 3.092809 | 15.604803 | 61.381208 | 319.420225 | 3.631434e+06 | 1.152331e+04 |
| std | 5.793591 | 37.438179 | 124.130542 | 578.784405 | 6.542330e+06 | 2.395408e+04 |
| min | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 3.410000e+02 | 2.040000e+02 |
| 25% | 0.000000 | 3.000000 | 2.000000 | 14.000000 | 1.620000e+05 | 4.794000e+03 |
| 50% | 1.000000 | 7.000000 | 20.000000 | 114.000000 | 1.000000e+06 | 8.082000e+03 |
| 75% | 4.000000 | 16.000000 | 66.000000 | 375.000000 | 3.900000e+06 | 1.200000e+04 |
| max | 99.000000 | 2160.000000 | 4213.000000 | 4907.000000 | 2.950000e+07 | 2.500000e+06 |
- 最后,为了便于识别,'total_article'和'total_watch'字段命名为'author_total_article'和'author_total_watch',再排序字段,把清理后的干净数据导出到EXCEL和MongoDB数据库
df[['author_total_article', 'author_total_watch']] = df[['total_article', 'total_watch']]df = df[['title', 'author', 'time', 'tag', 'watch', 'star', 'good', 'comment', 'author_total_article', 'author_total_watch', 'article']]df.to_excel('product.xlsx')for index,row in df.iterrows():
db.everyone_product_clean.insert(row.to_dict())from pymongo import MongoClient
import pandas as pd
client = MongoClient()
db = client.product
cursor = db.everyone_product_clean.find()
df = pd.DataFrame(list(cursor))
df.drop('_id', inplace=True, axis=1)
df = df[['title', 'author', 'time', 'tag', 'watch', 'star', 'good', 'comment', 'author_total_article', 'author_total_watch', 'article']]为了便于研究新增2个文章标题长度和文章长度的字段
df['len_title'] = df['title'].str.len()
df['len_article'] = df['article'].str.len()文章浏览量、收藏量、点赞量和评论量是从用户角度客观反映文章质量的指标
df.describe()| watch | star | good | comment | author_total_article | author_total_watch | len_title | len_article | |
|---|---|---|---|---|---|---|---|---|
| count | 3.560000e+04 | 35600.000000 | 35600.000000 | 35600.000000 | 35600.000000 | 3.560000e+04 | 35600.000000 | 35600.00000 |
| mean | 1.152331e+04 | 61.381208 | 15.604803 | 3.092809 | 319.420225 | 3.631434e+06 | 19.532079 | 2542.33764 |
| std | 2.395408e+04 | 124.130542 | 37.438179 | 5.793591 | 578.784405 | 6.542330e+06 | 6.341600 | 1828.61820 |
| min | 2.040000e+02 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 3.410000e+02 | 4.000000 | 0.00000 |
| 25% | 4.794000e+03 | 2.000000 | 3.000000 | 0.000000 | 14.000000 | 1.620000e+05 | 15.000000 | 1417.00000 |
| 50% | 8.082000e+03 | 20.000000 | 7.000000 | 1.000000 | 114.000000 | 1.000000e+06 | 19.000000 | 2126.00000 |
| 75% | 1.200000e+04 | 66.000000 | 16.000000 | 4.000000 | 375.000000 | 3.900000e+06 | 23.000000 | 3141.00000 |
| max | 2.500000e+06 | 4213.000000 | 2160.000000 | 99.000000 | 4907.000000 | 2.950000e+07 | 67.000000 | 36565.00000 |
- 文章总体浏览量
文章的浏览量的平均值达到了1.15万,还是相当高的。
浏览量最高的一篇到达了二百五十万,是在2015年4月发表的一篇关于产品原型的文章,文章的标题为22个字,文章文字部分内容只有252个字,大部分内容是原型设计的图片,看来直观的图片的力量要大于文字的说服力。该文章的收藏量为2089,点赞量为1878,评论量为31。该文章的作者GaraC总共发表了16篇文章,所有文章的浏览量为3700000。
df.loc[df['watch'] == 2500000]| title | author | time | tag | watch | star | good | comment | author_total_article | author_total_watch | article | len_title | len_article | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 24890 | 绝密原型档案:看看专业产品经理的原型是什麽样 | GaraC | 2015-04-20 | [Gara, 专栏作家, 原型] | 2500000.0 | 2089 | 1878 | 31 | 16 | 3700000.0 | 一直想找机会写写关于原型的事情,由于原型作为关键的需求文档,非常需要进行保密,所以未成文。最... | 22 | 252 |
# 浏览量最高的文章
df.loc[df['watch'] == 2500000]['article'].valuesarray([ '一直想找机会写写关于原型的事情,由于原型作为关键的需求文档,非常需要进行保密,所以未成文。最近刚好有一个项目被撤了,之前做的原型藏着也浪费,或许可以偷偷拿出来分享下。这是某项目1.06版原型,因此针对上一个版本原型修改了哪些内容,我在第一页做了说明我用来说明产品页面结构和主要功能流程首先是结构:然后是流程关于全局设计、交互的统一说明这是界面这是模块功能的流程这是内容与操作说明在导航部分我用字母、数字分别说明了所在模块、页面编号、页面层级等信息。只是一种便于我自己寻找以及内部沟通的形式,看个意思就好。'], dtype=object)
# 作者GaraC的文章总量
(df['author'] == 'GaraC').sum()16
# 作者GaraC所有文章的总浏览量
df['author_total_watch'].groupby(df['author']).sum()['GaraC']59200000.0
- 文章收藏量
文章收藏量的平均值为61,标准差较大达到了124,75分位大小为66,证明不同文章间收藏量差距很大,属于长尾分布。
最大的收藏量达到了4213,是发表于2015年9月的一篇关于产品文档的文章,文章标题长16字,文章长度为1722,同样该文章也用了大量的图片说明。该文章的总浏览量458000,收藏量4213,点赞量2160,评论量30。该文章的作者臻龙总共发表了5篇文章,作者所有文章的浏览量为691000。
df.loc[df['star'] == df['star'].max()]| title | author | time | tag | watch | star | good | comment | author_total_article | author_total_watch | article | len_title | len_article | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 21562 | Word产品需求文档,已经过时了 | 臻龙 | 2015-09-29 | [PRD, 产品需求文档] | 458000.0 | 4213 | 2160 | 30 | 5 | 691000.0 | 说来有些惭愧,写这篇文章是用来教大家写需求文档的。但其实,我很少会写传统意义上的产品需求文档... | 16 | 1722 |
(df['author'] == '臻龙').sum()5
df['author_total_watch'].groupby(df['author']).sum()['臻龙']3455000.0
- 文章点赞量
文章点赞量的平均值为15.6,标准差为37,75分位值为16接近平均值,差距也比较大,也属于长尾型分布。
点赞量最多的一篇文章达到了2160,和收藏量最多的文章是同一个作者的同一篇文章。
df.loc[df['good'] == df['good'].max()]| title | author | time | tag | watch | star | good | comment | author_total_article | author_total_watch | article | len_title | len_article | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 21562 | Word产品需求文档,已经过时了 | 臻龙 | 2015-09-29 | [PRD, 产品需求文档] | 458000.0 | 4213 | 2160 | 30 | 5 | 691000.0 | 说来有些惭愧,写这篇文章是用来教大家写需求文档的。但其实,我很少会写传统意义上的产品需求文档... | 16 | 1722 |
- 文章评论量
文章评论量的平均值为3,还是相当小的,50分位数评论量为1,也就是说有一半以上的文章都没有评论。说明可能存在的两个问题:(1)该网站的注册用户表较少。(2)互联网文章很难获得评论。
评论量最高的一篇文章达到99,是2015年10月份发表的一篇关于产品经理求职的文章,文章标题长度12字,文章内容1576字,文章浏览量为27000,作者只发表了一篇文章。
df.loc[df['comment'] == df['comment'].max()]| title | author | time | tag | watch | star | good | comment | author_total_article | author_total_watch | article | len_title | len_article | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 20835 | 求职产品助理的一个月感想 | 兔子爱榴莲 | 2015-10-12 | [产品经理求职, 求职经验] | 27000.0 | 179 | 52 | 99 | 1 | 27000.0 | 本人普通本科毕业,学校算不上有名,在**的大学排名中,排在150左右,学的是材料化学,被调剂... | 12 | 1576 |
(df['author'] == '兔子爱榴莲').sum()1
从4个指标的箱线图来看,尾巴都拉的很长,把“箱子”拉的很平几乎成了一条线,说明数据分布很不均匀
# 引入作图函数
%matplotlib inline
from matplotlib import pyplot as plt
from matplotlib.ticker import MultipleLocator, FormatStrFormatter
plt.style.use('ggplot')
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = 'SimHei'fig, axes = plt.subplots(2, 2, figsize=(9,7), dpi=350)
df.boxplot(ax=axes[0,0], column='watch')
df.boxplot(ax=axes[0,1], column='star')
df.boxplot(ax=axes[1,0], column='good')
df.boxplot(ax=axes[1,1], column='comment')<matplotlib.axes._subplots.AxesSubplot at 0x23971a9d9b0>

再来看看文章浏览量、收藏量、点赞量和评论量分别排前10的文章都在讲什么?
从各个前10的文章中发现,比较多是关于Axure,求职,面试,干货教程分享的文章。
而这些文章中,前10浏览量的标题平均字数为21.9,文章平均字数为1650.3,前10收藏量的标题平均字数为18.4,文章平均字数为2028.4,前10点赞量的标题平均字数为20.2,文章平均字数为1646.5,前10评论量的标题平均字数为20.4,文章平均字数为4048.6,各个前10文章标题字数平均值为20.225,文章平均字数为2343.45。看来一篇文章要想获得网友的认可,一个好的标题很重要,毕竟对互联网来说标题党还是有很大优势的,其次,文章的字数不一定要太多,但是需要配以合适的图表说明才能更加吸引网友。
- 浏览量前10文章
df.sort_values(by='watch',ascending=False)[['title', 'watch', 'star', 'good', 'comment', 'len_title', 'len_article', 'author_total_article', 'author_total_watch']].iloc[:10]| title | watch | star | good | comment | len_title | len_article | author_total_article | author_total_watch | |
|---|---|---|---|---|---|---|---|---|---|
| 24544 | 绝密原型档案:看看专业产品经理的原型是什麽样 | 2500000.0 | 2089 | 1878 | 31 | 22 | 252 | 16 | 3700000.0 |
| 32991 | Axure教程 axure新手入门基础(1) | 1400000.0 | 1396 | 825 | 35 | 22 | 1426 | 1549 | 29500000.0 |
| 24417 | Axure 8.0中文版下载(支持windows和Mac) | 1200000.0 | 484 | 1103 | 29 | 29 | 1424 | 466 | 6300000.0 |
| 14889 | 小白产品经理看产品:什么是互联网产品 | 988000.0 | 943 | 22 | 1 | 18 | 4578 | 22 | 1400000.0 |
| 18861 | 推荐几个H5页面制作工具,自己选一下吧 | 652000.0 | 1478 | 209 | 12 | 19 | 1082 | 7 | 863000.0 |
| 22084 | 【干货】H5页面制作免费工具大集合 | 485000.0 | 850 | 907 | 13 | 17 | 2471 | 34 | 1000000.0 |
| 34227 | 产品需求文档的写作(四) – 撰写文档(PRD文档) | 461000.0 | 749 | 201 | 6 | 26 | 1755 | 373 | 6700000.0 |
| 32990 | Axure教程 axure新手入门基础(2) | 459000.0 | 347 | 299 | 19 | 22 | 1585 | 1549 | 29500000.0 |
| 21252 | Word产品需求文档,已经过时了 | 458000.0 | 4213 | 2160 | 30 | 16 | 1722 | 5 | 691000.0 |
| 25951 | 【干货下载】Axure 元件库- 常用元素1056枚下载 | 426000.0 | 133 | 457 | 33 | 28 | 208 | 1011 | 12200000.0 |
- 收藏量前10文章
df.sort_values(by='star',ascending=False)[['title', 'watch', 'star', 'good', 'comment', 'len_title', 'len_article', 'author_total_article', 'author_total_watch']].iloc[:10]| title | watch | star | good | comment | len_title | len_article | author_total_article | author_total_watch | |
|---|---|---|---|---|---|---|---|---|---|
| 21252 | Word产品需求文档,已经过时了 | 458000.0 | 4213 | 2160 | 30 | 16 | 1722 | 5 | 691000.0 |
| 13830 | 如何去做一份竞品分析报告 | 79000.0 | 2360 | 233 | 30 | 12 | 2000 | 10 | 181000.0 |
| 16306 | 在面试时候,如何简明扼要简述产品流程(附思维导图下载) | 38000.0 | 2338 | 286 | 10 | 27 | 1080 | 358 | 3000000.0 |
| 16566 | 你会写报告?产品体验报告的思路应该是这样的! | 93000.0 | 2181 | 194 | 20 | 22 | 3682 | 14 | 394000.0 |
| 24544 | 绝密原型档案:看看专业产品经理的原型是什麽样 | 2500000.0 | 2089 | 1878 | 31 | 22 | 252 | 16 | 3700000.0 |
| 16656 | 产品经理面试习题大汇总 | 139000.0 | 2049 | 494 | 12 | 11 | 4332 | 5 | 311000.0 |
| 21507 | 三个步骤教你如何做好后台产品设计 | 157000.0 | 1874 | 333 | 32 | 16 | 2210 | 64 | 1000000.0 |
| 14191 | 如何优雅的用Axure装逼?高保真原型心得分享 | 86000.0 | 1816 | 285 | 27 | 23 | 2173 | 1 | 86000.0 |
| 18490 | 干货流出|腾讯内部几近满分的项目管理课程PPT | 49000.0 | 1742 | 105 | 6 | 23 | 986 | 821 | 7000000.0 |
| 19992 | 提升运营效率的10款工具 | 13000.0 | 1701 | 56 | 3 | 12 | 1847 | 185 | 2300000.0 |
- 点赞量前10文章
df.sort_values(by='good',ascending=False)[['title', 'watch', 'star', 'good', 'comment', 'len_title', 'len_article', 'author_total_article', 'author_total_watch']].iloc[:10]| title | watch | star | good | comment | len_title | len_article | author_total_article | author_total_watch | |
|---|---|---|---|---|---|---|---|---|---|
| 21252 | Word产品需求文档,已经过时了 | 458000.0 | 4213 | 2160 | 30 | 16 | 1722 | 5 | 691000.0 |
| 24544 | 绝密原型档案:看看专业产品经理的原型是什麽样 | 2500000.0 | 2089 | 1878 | 31 | 22 | 252 | 16 | 3700000.0 |
| 34633 | Axure 7.0 汉化版下载 | 36000.0 | 13 | 1556 | 11 | 15 | 714 | 1549 | 29500000.0 |
| 28736 | 交互设计初体验(iUED) | 9549.0 | 7 | 1406 | 2 | 13 | 2128 | 556 | 6500000.0 |
| 33605 | axure 7.0正式版发布(附下载地址和汉化包) | 333000.0 | 143 | 1329 | 6 | 25 | 1150 | 466 | 6300000.0 |
| 22717 | 放大你的格局,你的人生将不可思议 | 243000.0 | 42 | 1233 | 4 | 16 | 1811 | 472 | 4900000.0 |
| 24417 | Axure 8.0中文版下载(支持windows和Mac) | 1200000.0 | 484 | 1103 | 29 | 29 | 1424 | 466 | 6300000.0 |
| 30349 | #woshiPM训练营#深圳站总结入口页:对怀孕妈妈的关怀 | 4911.0 | 0 | 1026 | 26 | 29 | 603 | 364 | 3600000.0 |
| 14873 | 支付风控系统设计:支付风控场景分析(一) | 37000.0 | 172 | 999 | 3 | 20 | 4190 | 14 | 495000.0 |
| 22084 | 【干货】H5页面制作免费工具大集合 | 485000.0 | 850 | 907 | 13 | 17 | 2471 | 34 | 1000000.0 |
- 评论量前10文章
df.sort_values(by='comment',ascending=False)[['title', 'watch', 'star', 'good', 'comment', 'len_title', 'len_article', 'author_total_article', 'author_total_watch']].iloc[:10]| title | watch | star | good | comment | len_title | len_article | author_total_article | author_total_watch | |
|---|---|---|---|---|---|---|---|---|---|
| 20532 | 求职产品助理的一个月感想 | 27000.0 | 179 | 52 | 99 | 12 | 1576 | 1 | 27000.0 |
| 4555 | 一个交友App将死,作为创始人的他说: 手机应用市场更像一个应用坟场 | 8814.0 | 23 | 14 | 95 | 35 | 2775 | 1 | 8814.0 |
| 16221 | 产品设计 | 58同城与赶集网APP改版建议 | 8448.0 | 67 | 28 | 87 | 22 | 963 | 1 | 8448.0 |
| 7376 | 倒推“饿了么”App产品需求文档(PRD) | 127000.0 | 975 | 214 | 85 | 21 | 6603 | 1 | 127000.0 |
| 10212 | 作为产品经理,我是如何带团队的 | 25000.0 | 253 | 74 | 77 | 15 | 2352 | 24 | 298000.0 |
| 8322 | 什么样的人更适合做产品经理? | 28000.0 | 505 | 148 | 75 | 14 | 2670 | 40 | 465000.0 |
| 4640 | 可能是最走心的“菜谱类”应用竞品分析 | 42000.0 | 357 | 125 | 75 | 18 | 9961 | 3 | 71000.0 |
| 1696 | 吐槽QQ音乐:看不惯这5个槽点,我自己改造了一下 | 8140.0 | 26 | 18 | 74 | 24 | 2165 | 1 | 8142.0 |
| 2233 | 写给迷茫的产品新人:产品经理工作体系 | 34000.0 | 531 | 117 | 72 | 18 | 9459 | 1 | 34000.0 |
| 4512 | 我和人人都是产品经理CEO老曹的约定(文末有福利) | 12000.0 | 18 | 18 | 70 | 25 | 1962 | 2 | 30000.0 |
- 建立一个以作者为索引的数据透视表
可以看到全部35600篇文章是3460个作者写的,平均每个作者将近写12篇文章,75分位数为5,而且有1478位作者只发表了1篇文章,说明大部分文章都是少数几个作者写的。文章写作数量前10的作者,发表文章数量都是500篇以上,最多的作者老曹居然发表了4907篇文章,绝对是职业写手啊。
df.pivot_table(index='author').sort_values(by='author_total_article', ascending=False).head(10)| author_total_article | author_total_watch | comment | good | star | watch | |
|---|---|---|---|---|---|---|
| author | ||||||
| 老曹 | 4907.0 | 23500000.0 | 1.408360 | 10.093248 | 11.877814 | 8580.183280 |
| Nairo | 1549.0 | 29500000.0 | 1.910761 | 21.287402 | 36.963911 | 19146.955381 |
| yoyo | 1094.0 | 11700000.0 | 1.037511 | 9.695334 | 34.818847 | 10654.217749 |
| 人人都是产品经理 | 1011.0 | 12200000.0 | 2.536398 | 14.628352 | 27.538953 | 11516.680715 |
| 米可 | 821.0 | 7000000.0 | 2.266748 | 14.300853 | 61.092570 | 8553.405603 |
| 漓江 | 579.0 | 5300000.0 | 1.604610 | 6.998227 | 9.125887 | 8989.570922 |
| 绝迹 | 577.0 | 6300000.0 | 0.833622 | 2.587522 | 3.480069 | 10933.038128 |
| 朱帝 | 556.0 | 6500000.0 | 1.591418 | 16.580224 | 25.285448 | 11744.244403 |
| 七月 | 536.0 | 4300000.0 | 2.456238 | 11.893855 | 60.063315 | 8010.765363 |
| Ella | 517.0 | 5300000.0 | 2.724272 | 17.299029 | 74.324272 | 10111.151456 |
df.pivot_table(index='author').describe()| author_total_article | author_total_watch | comment | good | len_article | len_title | star | watch | |
|---|---|---|---|---|---|---|---|---|
| count | 3460.000000 | 3.460000e+03 | 3460.000000 | 3460.000000 | 3460.000000 | 3460.000000 | 3460.000000 | 3460.000000 |
| mean | 11.956916 | 1.281128e+05 | 6.044453 | 23.558131 | 2697.984678 | 19.751216 | 105.564567 | 12688.477031 |
| std | 99.146344 | 8.126697e+05 | 7.684594 | 32.354668 | 1799.616701 | 4.893373 | 133.115580 | 13988.736884 |
| min | 1.000000 | 3.410000e+02 | 0.000000 | 0.000000 | 2.000000 | 8.000000 | 0.000000 | 442.000000 |
| 25% | 1.000000 | 8.486750e+03 | 1.666667 | 8.677656 | 1651.500000 | 16.750000 | 33.000000 | 5800.916667 |
| 50% | 2.000000 | 2.100000e+04 | 4.000000 | 15.125000 | 2276.000000 | 19.250000 | 65.888889 | 9189.185714 |
| 75% | 5.000000 | 6.000000e+04 | 7.788462 | 27.183239 | 3204.790323 | 22.218407 | 128.750000 | 15000.000000 |
| max | 4907.000000 | 2.950000e+07 | 99.000000 | 732.000000 | 25898.000000 | 55.000000 | 1816.000000 | 233535.750000 |
(df.pivot_table(index='author')['author_total_article'] == 1).sum()1478
fig, axes = plt.subplots(1, 2, figsize=(7,3),dpi=350)
axes[0].set_title('文章长度')
axes[0].hist(df['len_article'], normed=True)(array([ 2.26347723e-04, 4.03698508e-05, 5.17778867e-06,
1.15232686e-06, 2.76558445e-07, 1.07550506e-07,
2.30465371e-08, 1.53643581e-08, 7.68217903e-09,
7.68217903e-09]),
array([ 0. , 3656.5, 7313. , 10969.5, 14626. , 18282.5,
21939. , 25595.5, 29252. , 32908.5, 36565. ]),
<a list of 10 Patch objects>)

axes[1].set_title('标题长度',color='black')
axes[1].hist(df['len_title'],color='green')(array([ 1.78700000e+03, 1.02290000e+04, 1.36330000e+04,
7.55800000e+03, 1.75300000e+03, 4.70000000e+02,
1.25000000e+02, 3.00000000e+01, 9.00000000e+00,
6.00000000e+00]),
array([ 4. , 10.3, 16.6, 22.9, 29.2, 35.5, 41.8, 48.1, 54.4,
60.7, 67. ]),
<a list of 10 Patch objects>)
fig
大部分文章长度在3600字以下,标题在17字以下
fig, axes = plt.subplots(2, 2, figsize=(13,9), dpi=200, sharex=True, sharey=True)
axes[0,0].scatter(df['len_title'], df['len_article']/1000, df['comment'])
axes[0,1].scatter(df['len_title'], df['len_article']/1000, df['good'])
axes[1,0].scatter(df['len_title'], df['len_article']/1000, df['watch']/1000)
axes[1,1].scatter(df['len_title'], df['len_article']/1000, df['star'])
plt.subplots_adjust(wspace=0,hspace=0)
- 各指标按年和季度划分的平均值
df.pivot_table(index=[df['time'].dt.year, df['time'].dt.quarter])| author_total_article | author_total_watch | comment | good | len_article | len_title | star | watch | ||
|---|---|---|---|---|---|---|---|---|---|
| time | time | ||||||||
| 2013 | 2 | 1256.888889 | 8.237734e+06 | 0.457364 | 2.281654 | 1967.521964 | 17.728682 | 3.612403 | 7203.891473 |
| 3 | 662.153586 | 6.492783e+06 | 1.303797 | 6.560338 | 1949.615190 | 17.004219 | 7.810970 | 10819.998312 | |
| 4 | 462.131436 | 4.874812e+06 | 1.157182 | 8.160569 | 2126.259485 | 17.777778 | 4.071816 | 7943.343496 | |
| 2014 | 1 | 632.915782 | 5.714669e+06 | 1.123850 | 7.345364 | 2101.597311 | 17.356688 | 4.776362 | 8709.420382 |
| 2 | 550.956696 | 5.522752e+06 | 1.485676 | 9.001999 | 2156.725516 | 17.908061 | 10.069287 | 10791.447035 | |
| 3 | 498.489611 | 4.860608e+06 | 1.709110 | 9.397443 | 2098.685669 | 17.845498 | 8.232286 | 11029.824188 | |
| 4 | 449.025858 | 5.521193e+06 | 1.726649 | 11.569921 | 2161.366227 | 18.008971 | 12.096042 | 12398.943536 | |
| 2015 | 1 | 598.126663 | 8.887772e+06 | 1.090474 | 11.746142 | 2216.189995 | 18.432145 | 12.987227 | 12342.824907 |
| 2 | 747.885017 | 1.246620e+07 | 1.708479 | 20.375726 | 2280.474448 | 18.714866 | 29.636469 | 18976.247387 | |
| 3 | 332.796498 | 4.411992e+06 | 4.282609 | 33.486715 | 2221.472826 | 19.297705 | 61.888285 | 13529.681763 | |
| 4 | 244.212508 | 2.897503e+06 | 2.733455 | 26.418944 | 2473.933819 | 20.211900 | 203.788100 | 14688.696418 | |
| 2016 | 1 | 164.090727 | 1.757044e+06 | 2.450627 | 14.278195 | 2617.868672 | 19.931328 | 203.445113 | 12264.974937 |
| 2 | 120.457565 | 1.325791e+06 | 3.937884 | 15.939114 | 2488.156212 | 20.393604 | 90.551661 | 13546.567651 | |
| 3 | 152.274336 | 1.617612e+06 | 4.394437 | 17.304678 | 2832.668774 | 20.236410 | 88.647282 | 15032.510114 | |
| 4 | 182.840475 | 1.816903e+06 | 4.124935 | 20.482189 | 2936.026846 | 21.269489 | 74.468766 | 14686.799690 | |
| 2017 | 1 | 150.163034 | 1.455641e+06 | 4.414623 | 19.529519 | 2761.760218 | 21.594914 | 76.010899 | 12608.478202 |
| 2 | 88.972317 | 8.792070e+05 | 6.247207 | 21.069451 | 2827.047596 | 20.806217 | 78.818844 | 11976.775134 | |
| 3 | 128.811796 | 1.159495e+06 | 4.390308 | 15.581518 | 2862.755823 | 20.656649 | 65.212622 | 8875.675808 | |
| 4 | 108.002234 | 9.799726e+05 | 4.182306 | 13.593387 | 3053.505809 | 20.492404 | 60.059428 | 7398.951296 | |
| 2018 | 1 | 128.183418 | 1.156542e+06 | 3.833256 | 13.842983 | 3135.006484 | 20.036591 | 50.403428 | 6608.858731 |
| 2 | 103.111554 | 9.446475e+05 | 3.286853 | 11.205179 | 3284.585657 | 20.555777 | 21.149402 | 4227.697211 |
- 发文数量按年和季度划分的平均值
df.pivot_table(index=[df['time'].dt.year, df['time'].dt.quarter], values='title', aggfunc='count').unstack()| title | ||||
|---|---|---|---|---|
| time | 1 | 2 | 3 | 4 |
| time | ||||
| 2013 | NaN | 387.0 | 1185.0 | 1476.0 |
| 2014 | 1413.0 | 1501.0 | 1877.0 | 1895.0 |
| 2015 | 1879.0 | 1722.0 | 1656.0 | 1647.0 |
| 2016 | 1995.0 | 1626.0 | 1582.0 | 1937.0 |
| 2017 | 2202.0 | 2059.0 | 2662.0 | 2238.0 |
| 2018 | 2159.0 | 502.0 | NaN | NaN |
- 发文量按年和月份划分的平均值
df.pivot_table(index=[df['time'].dt.year, df['time'].dt.month], values='title', aggfunc='count').unstack()| title | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| time | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| time | ||||||||||||
| 2013 | NaN | NaN | NaN | NaN | NaN | 387.0 | 370.0 | 419.0 | 396.0 | 470.0 | 421.0 | 585.0 |
| 2014 | 423.0 | 427.0 | 563.0 | 530.0 | 518.0 | 453.0 | 588.0 | 663.0 | 626.0 | 564.0 | 762.0 | 569.0 |
| 2015 | 761.0 | 478.0 | 640.0 | 570.0 | 567.0 | 585.0 | 622.0 | 542.0 | 492.0 | 542.0 | 554.0 | 551.0 |
| 2016 | 831.0 | 489.0 | 675.0 | 547.0 | 551.0 | 528.0 | 531.0 | 565.0 | 486.0 | 395.0 | 677.0 | 865.0 |
| 2017 | 678.0 | 731.0 | 793.0 | 689.0 | 730.0 | 640.0 | 815.0 | 1022.0 | 825.0 | 715.0 | 879.0 | 644.0 |
| 2018 | 834.0 | 481.0 | 844.0 | 502.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
- 发文量按季度的增长趋势
f,a = plt.subplots(figsize=(7,5), dpi=400)
df.pivot_table(index=[df['time'].dt.year, df['time'].dt.quarter], values='title', aggfunc='count').iloc[1:-1,].plot(ax=a)<matplotlib.axes._subplots.AxesSubplot at 0x23970c17da0>

from collections import Countertag_list = []
for tag in df['tag']:
tag_list.extend(tag)tag_dic = Counter(tag_list)35600篇文章总共有17185个标签
len(tag_dic)17185
- 排名前10的标签
tag_dic[:10][('初级', 1902),
('产品经理', 1867),
('3年', 1535),
('案例分析', 1410),
('2年', 1340),
('中级', 1240),
('产品设计', 1023),
('用户体验', 976),
('创业', 938),
('微信', 858)]
from wordcloud import WordCloudwordcloud = WordCloud(font_path='images/NotoSansHans-Regular.otf', width=700, height=500, background_color='white')
wordcloud.generate_from_frequencies(tag_dic)
plt.imshow(wordcloud)
plt.axis('off')
plt.show()