Scatter gather with AWS lambda
The challenge
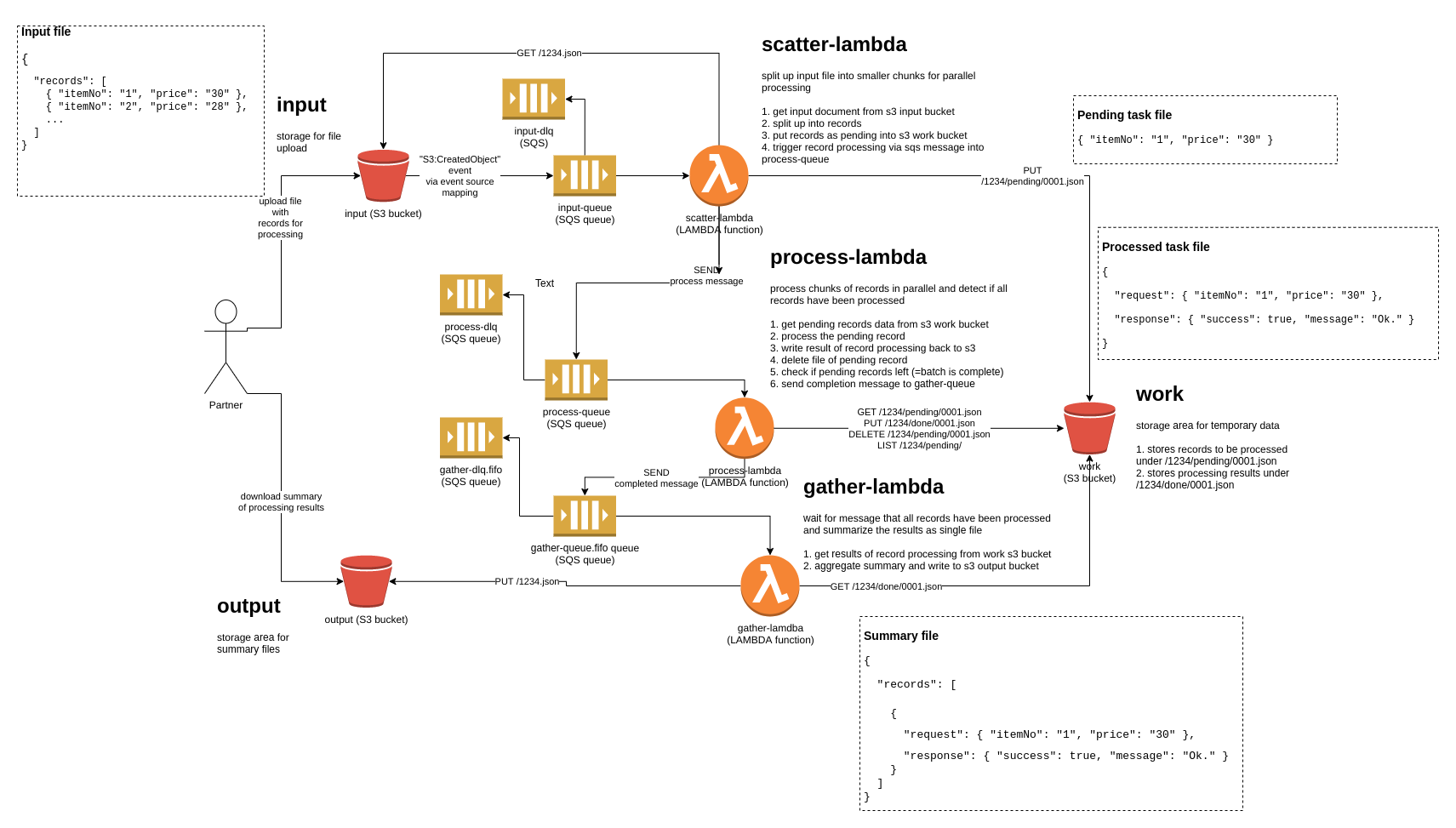
Implement batch processing on AWS:

- scatter: Split up a single file of records to be processed (the file has been uploaded via s3)
- process: Process records as parallel as possible
- gather: Detect completion of processing and aggregate a result summary report in s3
Prerequisites
- python 3.8
- GNU make
- docker
- awscli
- tfvm or terraform
- cw >= v3.3.0
Usage locally
Start localstack, deploy and run benchmark
make clean start_localstack deploy benchmark report
Stop and cleanup
make stop_localstack clean
Usage on aws
All resources will be prefixed with your current ${USER}-. Pass SCOPE=mycustomprefix- to make to override this default.
Build, package, deploy run benchmark, report on measurements
make ENV=aws clean deploy_resources deploy_service benchmark report
Undeploy
make ENV=aws destroy
Variants
The task has been implemented in various variants:
- s3-sqs-lambda-sync (with boto3 blocking io)
- s3-sqs-lambda-async (with aioboto3 async io)
- s3-sqs-lambda-async-chunked (with aioboto3 async io, records packed into chunks)
- s3-sqs-lambda-dynamodb (with aioboto3 async io, records stored in dynamodb)

- s3-notification-sqs-lambda (with aioboto3 async io, records stored in s3 in chunks, functions invoked by s3 notifications through sqs queues)


More/ alternative variants
- sfn?
- glue?
- emr (spark)?
- s3 athena?
- s3 batch
- single fat vm
Results

Repository structure
- infra - Resources and service infrastructure
- src - Service sources
- tests - Service tests
- benchmark - Benchmark sources
Documentation
License
Copyright 2020 by Cornelius Buschka. All rights reserved.