- Base de Données Relationnelle et Transactionnelle (RDBMS)
- Modélisation
- SQL
- Types de données
- Fonctions / Expressions
- Fonctions d'aggrégation
- Interrogation de la base (SELECT)
- Manipulation des données (UPDATE, INSERT, DELETE)
- Définitions des données
- Références
Le language standard pour dialoguer avec une base de données est le SQL
L’abréviation SQL signifie « Structured Query Language », un langage informatique servant à l’administration de structures de bases de données. Les opérations possibles comprennent des requêtes, des insertions, mises à jour et suppressions de fichiers de données.
-
Open Source
-
MySql
Logiciel développé par la société suédoise MySQL AB en 1994 est désormais sous le patronage d’Oracle Corporation et est distribué sur la base d’un système de double licence. En dehors de la version propriétaire entreprise, Oracle offre une licence GPL open source.
-
MariaDB
Dès 2009, l’équipe de développement et le fondateur de MySQL Michael Monty Widenius tournait le dos au système de base de données populaire et a lancé le fork à source ouverte MariaDB.
Fin 2012, Fedora, OpenSUSE, Slackware et Arch Linux présentaient les premières distributions Linux pour passer de MySQL à MariaDB comme installation standard. De nombreux projets open source, ainsi que les sociétés de logiciels bien connus et plateformes Web ont suivi cet exemple, à l’image de Mozilla, Ubuntu, Google, Red Hat Entreprise Linux, Web of Trust, TeamSpeak, la fondation Wikimedia ainsi que le projet de logiciels XAMPP.
MariaDB se caractérise déjà par un développement continu, en comparaison avec d’autres systèmes MySQL open source. Il est donc probable que ce fork dépasse un jour son projet-mère.
- points forts :
- hébergement très répendu et bon marché.
- beaucoup de code près à l'emploi disponible en php. Parfait pour débuter.
- phpMyAdmin
- points faibles :
- Les performances se dégradent dès qu'il y a de nombreuses jointures.
- points forts :
-
PostgreSQL
A ce jour, elle reste la base de donnée la plus robuste disponible. Les plus grandes bases de données mondiales sont sous PostgreSQL (ex: Yahoo).
Toutefois sa mise en route et le déploiement d'applications apportent un surcoût (serveur dédié).
-
SQLite
A la différence des BD évoquées ci-dessus, elle ne fonctionne pas sur une architecture client/serveur.
SQLite n'a besoin que d'un simple fichier pour stocker une base de données. En conséquence elle ne gère pas les accès concurrentiels, c'est "chacun son tour" pour obtenir un vérrou d'écriture.
Vous l'utilisez tous les jours : historique de votre navigateur, carnet d'adresse de votre téléphone portable, etc...
Elle peut être utilisée comme base de donnée locale à l'intérieur même du navigateur (javascript) ou coté serveur. Elle est souvent utilisée pour les phases de développement. (On utilisera alors un ORM - une abstraction objet de la base de donnée. Ex: RedBeanPHP, Doctrine ORM).
-
-
Propriétaire / Closed Source
-
Oracle
Leader du marché et très puissant, toutefois les licences sont très coûteuses. (L'édition entreprise est à 37 492 € HT par processeur - 2015)
-
SQL Server (MS SQL)
Sur le papier est presque comparable à PostgreSQL mais en pratique son coût ne justifie pas son seul avantage, le GUI.
Notons que Microsoft interdit la publication de benchmark visant à comparer les performances de son produit face à la concurrence... Je crois que tout est dit.
-



CREATE TABLE `point` (
id int,
`name` VARCHAR(64),
lat FLOAT,
lng FLOAT
)
CREATE TABLE simple_graph (
start_point_id int,
end_point_id int,
path_id int,
);SQL signifie "Structured Query Language" c'est-à-dire "Langage d'interrogation structuré". En fait SQL est un langage complet de gestion de bases de données relationnelles. Il a été conçu par IBM dans les années 70. Il est devenu le langage standard des systèmes de gestion de bases de données (SGBD) relationnelles (SGBDR). C'est à la fois :
- un langage d'interrogation de la base (ordre SELECT)
- un langage de manipulation des données (LMD ; ordres UPDATE, INSERT, DELETE)
- un langage de définition des données (LDD ; ordres CREATE, ALTER, DROP),
- un langage de contrôle de l'accès aux données (LCD ; ordres GRANT, REVOKE).
Le langage SQL est utilisé par les principaux SGBDR : DB2, Oracle, Informix, Ingres, RDB,... Chacun de ces SGBDR a cependant sa propre variante du langage. Ce support de cours présente un noyau de commandes disponibles sur l'ensemble de ces SGBDR,
SQL a été normalisé dès 1986 mais les premières normes, trop incomplètes, ont été ignorées par les éditeurs de SGBD.
La norme SQL2 (appelée aussi SQL92) date de 1992. Le niveau est à peu près respecté par tous les SGBD relationnels qui dominent actuellement le marché.
SQL-2 définit trois niveaux :
- Full SQL (ensemble de la norme)
- Intermediate SQL
- Entry Level (ensemble minimum à respecter pour se dire à la norme SQL-2)
SQL3 (appelée aussi SQL99) est la nouvelle norme SQL. Malgré ces normes, il existe des différences non négligeables entre les syntaxes et fonctionnalités des différents SGBD. En conséquence, écrire du code portable n'est pas toujours simple dans le domaine des bases de données.
SQL utilise des identificateurs pour désigner les objets qu'il manipule : utilisateurs, tables, colonnes, index, fonctions, etc...
Un identificateur est un mot formé d'au plus 30 caractères, commençant obligatoirement par une lettre de l'alphabet.
Les caractères suivants peuvent être une lettre, un chiffre, ou l'un des symboles # $ et _.
SQL ne fait pas la différence entre les lettres minuscules et majuscules. (Mais MySQL sous linux oui!!! Alors que sous windows non.)
Les voyelles accentuées ne sont pas acceptées. (Même si MySQL les acceptent, évitez absolument!)
Un identificateur ne doit pas figurer dans la liste des mot clés réservés. Voici quelques mots clés que l'on risque d'utiliser comme identificateurs : ASSERT, ASSIGN, AUDIT, COMMENT, DATE, DECIMAL, DEFINITION, FILE, FORMAT, INDEX, LIST, MODE, OPTION, PARTITION, PRIVILEGES, PUBLIC, REF, REFERENCES, SELECT, SEQUENCE, SESSION, SET, TABLE, TYPE, NAME...
Voir la liste complète : MariaDB Reserved Words
Avec MySQL les mots réservés sont employés comme nom d'un identificateur (table, champ, base de données, etc...) sont "échapés" avec l'apostrophe inversé `
Exemple :
CREATE TABLE `user` (
id SERIAL,
`name` VARCHAR(255)
);Les relations (d'un schéma relationnel) sont stockées sous forme de tables composées de lignes et de colonnes.
Il est d'usage (mais non obligatoire évidemment) de mettre les noms de table au singulier : plutôt EMPLOYE que EMPLOYES pour une table d'employés.
Table DEPT des départements :
| DEPT | NOM | LIEU |
|---|---|---|
| 10 | FINANCES | PARIS |
| 20 | RECHERCHE | GRENOBLE |
| 30 | VENTE | LYON |
| 40 | FABRICATION | ROUEN |
Les données contenues dans une colonne doivent être toutes d'un même type de données. Ce type est indiqué au moment de la création de la table qui contient la colonne. Chaque colonne est repérée par un identificateur unique à l'intérieur de chaque table. Deux colonnes de deux tables différentes peuvent porter le même nom. Il est ainsi fréquent de donner le même nom à deux colonnes de deux tables différentes lorsqu'elles correspondent à une clé étrangère à la clé primaire référencée.
Une colonne peut porter le même nom que sa table.
Le nom complet d'une colonne est en fait celui de sa table, suivi d'un point et du nom de la colonne. Par exemple, la colonne DEPT.LIEU
Le nom de la table peut être omis quand il n'y a pas d'ambiguïté sur la table à laquelle elle appartient, ce qui est généralement le cas.
Documentation officielle MariaDB (en)
La version française est très incomplète.
Les types numériques sont :
-
Nombres entiers : SMALLINT (sur 2 octets, de -32.768 à 32.767), INTEGER (sur 4 octets, de -2.147.483.648 à 2.147.483.647), BIGINT (sur 8 octets, de -9 milliards de milliards à +9).
Exemples
CREATE TABLE ints (a INT,b INT UNSIGNED,c INT ZEROFILL);
With strict_mode set, the default from MariaDB 10.2.4:
INSERT INTO ints VALUES (-10,-10,-10); -- ERROR 1264 (22003): Out of range value for column 'b' at row 1 INSERT INTO ints VALUES (-10,10,-10); -- ERROR 1264 (22003): Out of range value for column 'c' at row 1 INSERT INTO ints VALUES (-10,10,10); INSERT INTO ints VALUES (2147483648,2147483648,2147483648); -- ERROR 1264 (22003): Out of range value for column 'a' at row 1 INSERT INTO ints VALUES (2147483647,2147483648,2147483648); SELECT * FROM ints; +------------+------------+------------+ | a | b | c | +------------+------------+------------+ | -10 | 10 | 0000000010 | | 2147483647 | 2147483648 | 2147483648 | +------------+------------+------------+
-
Nombres décimaux avec un nombre fixe de décimales : NUMERIC, DECIMAL (la norme impose à NUMERIC d'être implanté avec exactement le nombre de décimales indiqué alors que l'implantation de DECIMAL peut avoir plus de décimales) : DECIMAL(p, d) correspond à des nombres décimaux qui ont p chiffres significatifs et d chiffres après la virgule ; NUMERIC a la même syntaxe.
Examples
CREATE TABLE t1 (d DECIMAL UNSIGNED ZEROFILL); INSERT INTO t1 VALUES (1),(2),(3),(4.0),(5.2),(5.7); -- Query OK, 6 rows affected, 2 warnings (0.16 sec) -- Records: 6 Duplicates: 0 Warnings: 2 -- Note (Code 1265): Data truncated for column 'd' at row 5 -- Note (Code 1265): Data truncated for column 'd' at row 6 SELECT * FROM t1; +------------+ | d | +------------+ | 0000000001 | | 0000000002 | | 0000000003 | | 0000000004 | | 0000000005 | | 0000000006 | +------------+
CREATE TABLE t2 (salaire DECIMAL(8,2) UNSIGNED); -- Query OK, 0 rows affected (0.020 sec) INSERT INTO t2 VALUES (1),(2),(3),(4.0),(5.2),(5.7); -- Query OK, 6 rows affected (0.007 sec) -- Records: 6 Duplicates: 0 Warnings: 0 SELECT * FROM t2; +---------+ | salaire | +---------+ | 1.00 | | 2.00 | | 3.00 | | 4.00 | | 5.20 | | 5.70 | +---------+
-
Numériques non exacts à virgule flottante : REAL (simple précision, avec au moins 7 chiffres significatifs), DOUBLE PRECISION ou FLOAT (double précision, avec au moins 15 chiffres significatifs). (SQL-2)
La définition des types non entiers dépend du SGBD (le nombre de chiffres significatifs varie). Reportez-vous au manuel du SGBD que vous utilisez pour plus de précisions.
En l'occurrence, avec MariaDB tout est inversé!
FLOAT = Single pression
REAL = Double pression
Dans MariaDB tous les calculs internes son effectués en DOUBLE, il est préférable d'utiliser REAL pour éviter les surprises.
Exemple
CREATE TABLE t1 (d DOUBLE(5,0) zerofill); INSERT INTO t1 VALUES (1),(2),(3),(4); SELECT * FROM t1; +-------+ | d | +-------+ | 00001 | | 00002 | | 00003 | | 00004 | +-------+
-
Le type BIT permet de ranger une valeur booléenne (un bit) en SQL-2.
Exemples
CREATE TABLE b ( b1 BIT(8) ); -- With strict_mode set, the default from MariaDB 10.2.4: INSERT INTO b VALUES (b'11111111'); INSERT INTO b VALUES (b'01010101'); INSERT INTO b VALUES (b'1111111111111'); -- ERROR 1406 (22001): Data too long for column 'b1' at row 1 SELECT b1+0, HEX(b1), OCT(b1), BIN(b1) FROM b; +------+---------+---------+----------+ | b1+0 | HEX(b1) | OCT(b1) | BIN(b1) | +------+---------+---------+----------+ | 255 | FF | 377 | 11111111 | | 85 | 55 | 125 | 1010101 | +------+---------+---------+----------+
-
CHAR(n)
Chaîne de longueur fixe qui est toujours complétée à droite avec des espaces jusqu'à la longueur spécifiée lorsqu'elle est stockée. M représente la longueur de la colonne en caractères. La plage de M va de 0 à 255. Si M est omis, la longueur est de 1.
Les colonnes CHAR (0) peuvent contenir 2 valeurs : une chaîne vide ou NULL. Ces colonnes ne peuvent pas faire partie d'un index.
-
VARCHAR(n)
Equivalences :
VARCHAR(30) CHARACTER SET utf8 NATIONAL VARCHAR(30) NVARCHAR(30) NCHAR VARCHAR(30) NATIONAL CHARACTER VARYING(30) NATIONAL CHAR VARYING(30)
Espaces de fin (Trailing spaces) :
CREATE TABLE strtest (v VARCHAR(10)); INSERT INTO strtest VALUES('Maria '); SELECT v='Maria',v='Maria ' FROM strtest; +-----------+--------------+ | v='Maria' | v='Maria ' | +-----------+--------------+ | 1 | 1 | +-----------+--------------+ SELECT v LIKE 'Maria',v LIKE 'Maria ' FROM strtest; +----------------+-------------------+ | v LIKE 'Maria' | v LIKE 'Maria ' | +----------------+-------------------+ | 0 | 1 | +----------------+-------------------+
Avec MariaDB le maximum est VARCHAR(65532) mais attention, l'index ne pourra pas dépasser 191 caractères en utf8mb4.
InnoDB Limitations
MariaDB imposes a row-size limit of 65,535 bytes for the combined sizes of all columns. If the table contains BLOB or TEXT columns, these only count for 9 - 12 bytes in this calculation, given that their content is stored separately.
La différence principale entre
VARCHAR()etTEXTrepose sur le fait queVARCHAR()peut être pleinement indexé. -
TEXT / MEDIUMTEXT / LONGTEXT
Une colonne
TEXTavec une longueur maximum de 65,535 (216 - 1) caractères (65k).MEDIUMTEXTest une colonneTEXTavec une longueur de 16MB (224 - 1) caractères. (coût 3 bytes)LONGTEXTest une colonneTEXTavec une longueur de 4GB (232 - 1) caractères. (coût 4 bytes) -
BLOB / MEDIUMBLOB / LONGBLOB
Un
BLOBest un objet binaire de taille variable. -
ENUM()
Syntaxe :
ENUM('value1','value2',...) [CHARACTER SET charset_name] [COLLATE collation_name]Index numérique
Les valeurs ENUM sont indexées numériquement dans l'ordre dans lequel elles sont définies, et le tri sera effectué dans cet ordre numérique. Nous suggérons de ne pas utiliser ENUM pour stocker des chiffres, car il y a peu ou pas d'avantage d'espace de stockage, et il est facile de confondre l'entier d'énumération avec la valeur numérique d'énumération en omettant les guillemets.
Un ENUM défini comme ENUM ('apple', 'orange', 'pear') aurait les valeurs d'index suivantes :
Index Value NULL NULL 0 '' 1 'apple' 2 'orange' 3 'pear' Exemple
CREATE TABLE fruits ( id INT NOT NULL auto_increment PRIMARY KEY, fruit ENUM('apple','orange','pear'), bushels INT ); DESCRIBE fruits; +---------+-------------------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +---------+-------------------------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | fruit | enum('apple','orange','pear') | YES | | NULL | | | bushels | int(11) | YES | | NULL | | +---------+-------------------------------+------+-----+---------+----------------+ INSERT INTO fruits (fruit,bushels) VALUES ('pear',20), ('apple',100), ('orange',25); INSERT INTO fruits (fruit,bushels) VALUES ('avocado',10); -- ERROR 1265 (01000): Data truncated for column 'fruit' at row 1 SELECT * FROM fruits; +----+--------+---------+ | id | fruit | bushels | +----+--------+---------+ | 1 | pear | 20 | | 2 | apple | 100 | | 3 | orange | 25 | +----+--------+---------+
Exemple de différence avec PostgreSQL
CREATE TABLE students ( id INT NOT NULL auto_increment PRIMARY KEY, full_name VARCHAR(128), gender ENUM('M','F') ); INSERT INTO students (full_name, gender) VALUES ('Michael Jackson', 'M'), ('Bruce Lee', 'M'), ('Agatha Christie', 'F'), ('Marie Curie', 'F'); -- MariaDB SELECT * FROM students WHERE gender > 'M'; -- Empty set (0.000 sec) -- PostgreSQL SELECT * FROM students WHERE gender > 'M'; id | full_name | gender ----+-----------------+-------- 3 | Agatha Christie | F 4 | Marie Curie | F (2 lignes)
-
SET()
Fonctionne un peut sur le même principe que
ENUM()à la différence qu'un champENUMn'acceptera qu'une seule valeur, alors queSETpeut en accepter plusieurs.CREATE TABLE set_test ( attrib SET('bold','italic','underline') ); INSERT INTO set_test (attrib) VALUES ('bold'); INSERT INTO set_test (attrib) VALUES ('bold,italic'); INSERT INTO set_test (attrib) VALUES ('bold,italic,underline'); SELECT * FROM set_test WHERE FIND_IN_SET('italic', attrib); +-----------------------+ | attrib | +-----------------------+ | bold,italic | | bold,italic,underline | +-----------------------+ SELECT * FROM set_test WHERE attrib = 'bold'; +--------+ | attrib | +--------+ | bold | +--------+ SELECT * FROM set_test WHERE attrib LIKE '%bold%'; +-----------------------+ | attrib | +-----------------------+ | bold | | bold,italic | | bold,italic,underline | +-----------------------+ SELECT * FROM set_test WHERE attrib = 'italic'; -- Empty set (0.000 sec)
-
DATE
The date type YYYY-MM-DD.
-
TIME
Time format HH:MM:SS.ssssss
-
DATETIME
Date and time combination displayed as YYYY-MM-DD HH:MM:SS.
-
TIMESTAMP
TIMESTAMP [(microsecond precision)]TIMESTAMP (6)
YYYY-MM-DD HH:MM:SS.ffffff
Une colonne qui n'est pas renseignée, et donc vide, est dite contenir la valeur NULL. Cette valeur n'est pas zéro, c'est une absence de valeur.
Toute expression dont au moins un des termes a la valeur NULL donne comme résultat la valeur NULL.
Une exception à cette règle est la fonction COALESCE. COALESCE (expr1, expr2,...) renvoie la première valeur qui n'est pas null parmi les valeurs des expressions expr1, expr2,...
COALESCE permet de remplacer la valeur null par une autre valeur.
Remarque importante : les valeurs NULL ne sont pas inclues dans les indexes (d'autant plus intéressant dans le cas des indexes uniques).
Dans le langage SQL, l’opérateur IS permet de filtrer les résultats qui contiennent la valeur NULL. Cet opérateur est indispensable car la valeur NULL est une valeur inconnue et ne peut par conséquent pas être filtrée par les opérateurs de comparaison (cf. égal, inférieur, supérieur ou différent).
Syntaxe Pour filtrer les résultats où les champs d’une colonne sont à NULL il convient d’utiliser la syntaxe suivante:
SELECT *
FROM `table`
WHERE nom_colonne IS NULLA l’inverse, pour filtrer les résultats et obtenir uniquement les enregistrements qui ne sont pas null, il convient d’utiliser la syntaxe suivante:
SELECT *
FROM `table`
WHERE nom_colonne IS NOT NULL;
-- strictement équivalent à :
SELECT *
FROM `table`
WHERE NOT nom_colonne IS NULL;A savoir : l’opérateur IS retourne en réalité un booléen, c’est à dire une valeur TRUE si la condition est vrai ou FALSE si la condition n’est pas respectée. Cet opérateur est souvent utilisé avec la condition WHERE mais peut aussi trouvé son utilité lorsqu’une sous-requête est utilisée.
% aussi dit modulo retourne le reste d'une division. Pratique pour tester pai/impaire ou pour connaitre la ligne dans un tableau paginé.
SELECT 8 % 3;
+-------+
| 8 % 3 |
+-------+
| 2 |
+-------+-- Not equal
SELECT 'zapp' <> 'zappp', 'zapp' != 'zappp';
+-------------------+-------------------+
| 'zapp' <> 'zappp' | 'zapp' != 'zappp' |
+-------------------+-------------------+
| 1 | 1 |
+-------------------+-------------------+NULL-safe égal. Cet opérateur effectue une comparaison d'égalité comme l'opérateur =, mais renvoie 1 plutôt que NULL si les deux opérandes sont NULL, et 0 plutôt que NULL si un opérande est NULL.
L'opérateur <=> est équivalent à l'opérateur SQL standard IS NOT DISTINCT FROM.
SELECT 1 <=> 1, NULL <=> NULL, 1 <=> NULL;
+---------+---------------+------------+
| 1 <=> 1 | NULL <=> NULL | 1 <=> NULL |
+---------+---------------+------------+
| 1 | 1 | 0 |
+---------+---------------+------------+
SELECT 1 = 1, NULL = NULL, 1 = NULL;
+-------+-------------+----------+
| 1 = 1 | NULL = NULL | 1 = NULL |
+-------+-------------+----------+
| 1 | NULL | NULL |
+-------+-------------+----------+SELECT *
FROM `user`
WHERE created_at BETWEEN '2021-01-01' AND '2021-01-31';
-- equivalent
SELECT *
FROM `user`
WHERE ('2021-01-01' <= created_at AND created_at <= '2021-01-31')SELECT 2 IN (0,3,5,7);
+----------------+
| 2 IN (0,3,5,7) |
+----------------+
| 0 |
+----------------+
SELECT (3,4) IN ((1,2), (3,4));
+-------------------------+
| (3,4) IN ((1,2), (3,4)) |
+-------------------------+
| 1 |
+-------------------------+
SELECT val1 FROM tbl1 WHERE val1 IN (1,2,'a');L’opérateur LIKE est utilisé dans la clause WHERE des requêtes SQL. Ce mot-clé permet d’effectuer une recherche sur un modèle particulier. Il est par exemple possible de rechercher les enregistrements dont la valeur d’une colonne commence par telle ou telle lettre. Les modèles de recherches sont multiple.
SELECT 'This is a string' LIKE '%ing';
+--------------------------------+
| 'This is a string' LIKE '%ing' |
+--------------------------------+
| 1 |
+--------------------------------+La syntaxe à utiliser pour utiliser l’opérateur LIKE est la suivante :
SELECT *
FROM table
WHERE colonne LIKE modeleDans cet exemple le “modèle” n’a pas été défini, mais il ressemble très généralement à l’un des exemples suivants:
LIKE'%a' : le caractère “%” est un caractère joker qui remplace tous les autres caractères. Ainsi, ce modèle permet de rechercher toutes les chaines de caractère qui se termine par un “a”.LIKE'a%' : ce modèle permet de rechercher toutes les lignes de “colonne” qui commence par un “a”.LIKE'%a%' : ce modèle est utilisé pour rechercher tous les enregistrement qui utilisent le caractère “a”.LIKE'pa%on' : ce modèle permet de rechercher les chaines qui commence par “pa” et qui se terminent par “on”, comme “pantalon” ou “pardon”.LIKE'a_c' : le caractère “_“ (underscore) peut être remplacé par n’importe quel caractère, mais un et un seul caractère uniquement (alors que le symbole pourcentage “%” peut être remplacé par un nombre indéterminé de caractères. Ainsi, ce modèle permet de retourner les lignes “aac”, “abc” ou même “azc”.
Dans le langage SQL, la commande CASE … WHEN … permet d’utiliser des conditions de type “si / sinon” (cf. if / else) similaire à un langage de programmation pour retourner un résultat disponible entre plusieurs possibilités. Le CASE peut être utilisé dans n’importe quelle instruction ou clause, telle que SELECT, UPDATE, DELETE, WHERE, ORDER BY ou HAVING.
L’utilisation du CASE est possible de 2 manières différentes :
Comparer une colonne à un set de résultat possible Élaborer une série de conditions booléennes pour déterminer un résultat Comparer une colonne à un set de résultat Voici la syntaxe nécessaire pour comparer une colonne à un set d’enregistrement :
SELECT
CASE t.a
WHEN 1 THEN 'un'
WHEN 2 THEN 'deux'
WHEN 3 THEN 'trois'
ELSE 'autre'
END AS undeuxtroisautre,
t.a
FROM
(
SELECT FLOOR(RAND() * 10) AS a
) AS t;
+------------------+---+
| undeuxtroisautre | a |
+------------------+---+
| autre | 6 |
+------------------+---+Dans cet exemple les valeurs contenus dans la colonne “a” sont comparé à 1, 2 ou 3. Si la condition est vrai, alors la valeur située après le THEN sera retournée.
A noter : la condition ELSE est facultative et sert de ramasse-miette. Si les conditions précédentes ne sont pas respectées alors ce sera la valeur du ELSE qui sera retournée par défaut.
Élaborer une série de conditions booléennes pour déterminer un résultat.
Il est possible d’établir des conditions plus complexes pour récupérer un résultat ou un autre. Cela s’effectue en utilisant la syntaxe suivante:
SELECT
CASE
WHEN a=b THEN 'A égal à B'
WHEN a>b THEN 'A supérieur à B'
ELSE 'A inférieur à B'
ENDDans cet exemple les colonnes “a”, “b” et “c” peuvent contenir des valeurs numériques. Lorsqu’elles sont respectées, les conditions booléennes permettent de rentrer dans l’une ou l’autre des conditions.
Il est possible de reproduire le premier exemple présenté sur cette page en utilisant la syntaxe suivante:
CASE
WHEN a=1 THEN 'un'
WHEN a=2 THEN 'deux'
WHEN a=3 THEN 'trois'
ELSE 'autre'
ENDComme cela a été expliqué au début, il est aussi possible d’utiliser le CASE à la suite de la commande SET d’un UPDATE pour mettre à jour une colonne avec une données spécifique selon une règle. Imaginons par exemple que l’ont souhaite offrir un produit pour tous les achats qui ont une surcharge inférieur à 1 et que l’ont souhaite retirer un produit pour tous les achats avec une surcharge supérieur à 1. Il est possible d’utiliser la requête SQL suivante :
UPDATE `achat`
SET `quantite` = (
CASE
WHEN `surcharge` < 1 THEN `quantite` + 1
WHEN `surcharge` > 1 THEN `quantite` - 1
ELSE quantite
END
)SELECT NOT TRUE;
+----------+
| NOT TRUE |
+----------+
| 0 |
+----------+
SELECT ! FALSE;
+---------+
| ! FALSE |
+---------+
| 1 |
+---------+SELECT true && false, true AND false;
+---------------+----------------+
| true && false | true AND false |
+---------------+----------------+
| 0 | 0 |
+---------------+----------------+
SELECT true || false, true OR false;
+---------------+---------------+
| true || false | true OR false |
+---------------+---------------+
| 1 | 1 |
+---------------+---------------+SELECT LEAST(34.0,3.0,5.0,767.0);
+---------------------------+
| LEAST(34.0,3.0,5.0,767.0) |
+---------------------------+
| 3.0 |
+---------------------------+
SELECT LEAST('B','A','C');
+--------------------+
| LEAST('B','A','C') |
+--------------------+
| A |
+--------------------+
SELECT GREATEST(34.0,3.0,5.0,767.0);
+------------------------------+
| GREATEST(34.0,3.0,5.0,767.0) |
+------------------------------+
| 767.0 |
+------------------------------+SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz');
+-------------------------------------+
| TRIM(TRAILING 'xyz' FROM 'barxxyz') |
+-------------------------------------+
| barx |
+-------------------------------------+SELECT UCASE('Voiture'), LCASE('Camion');
+------------------+-----------------+
| UCASE('Voiture') | LCASE('Camion') |
+------------------+-----------------+
| VOITURE | camion |
+------------------+-----------------+
-- Dans le cas où vous utilisez une collation
-- qui gère les caractères accentués (utf8, latin1, etc...)
SELECT UCASE('Véhicule');
+--------------------+
| UCASE('Véhicule') |
+--------------------+
| VÉHICULE |
+--------------------+SELECT SUBSTRING('Quadratically',5);
-> 'ratically'
SELECT SUBSTRING('foobarbar' FROM 4);
-> 'barbar'
SELECT SUBSTRING('Quadratically',5,6);
-> 'ratica'
SELECT SUBSTRING('Sakila', -3);
-> 'ila'
SELECT SUBSTRING('Sakila', -5, 3);
-> 'aki'
SELECT SUBSTRING('Sakila' FROM -4 FOR 2);
-> 'ki'SQL LENGTH() et utf8 ¡¡¡ Attention !!!
SELECT LENGTH('mange');
+-----------------+
| LENGTH('mange') |
+-----------------+
| 5 |
+-----------------+
SELECT LENGTH('mangé');
+------------------+
| LENGTH('mangé') |
+------------------+
| 6 |
+------------------+
SELECT CHAR_LENGTH('mangé');
+-----------------------+
| CHAR_LENGTH('mangé') |
+-----------------------+
| 5 |
+-----------------------+SET NAMES 'utf8' COLLATE 'utf8_unicode_ci';
SELECT 'é' = 'e';
+------------+
| 'é' = 'e' |
+------------+
| 1 |
+------------+
SELECT "ß" = "ss" COLLATE utf8_unicode_ci;
+-------------------------------------+
| "ß" = "ss" COLLATE utf8_unicode_ci |
+-------------------------------------+
| 1 |
+-------------------------------------+SELECT CONCAT_WS(", ", Address, PostalCode, City) AS Address
FROM Customers;Documentation officielle mariadb.com/kb/en/aggregate-functions/
CREATE TABLE student (name CHAR(10), test CHAR(10), score INT);
INSERT INTO student VALUES
('Chun', 'SQL', 75), ('Chun', 'Tuning', 73),
('Esben', 'SQL', 43), ('Esben', 'Tuning', 31),
('Kaolin', 'SQL', 56), ('Kaolin', 'Tuning', 88),
('Tatiana', 'SQL', 87), ('Tatiana', 'Tuning', 83);
SELECT COUNT(*) FROM student;
+----------+
| COUNT(*) |
+----------+
| 8 |
+----------+
-- COUNT(DISTINCT) example:
SELECT COUNT(DISTINCT (name)) FROM student;
+------------------------+
| COUNT(DISTINCT (name)) |
+------------------------+
| 4 |
+------------------------+
-- Dans une fonction de fenêtre (window function)
SELECT `name`, test, score,
COUNT(score) OVER (PARTITION BY `name`) AS tests_written
FROM student_test;
+---------+--------+-------+---------------+
| name | test | score | tests_written |
+---------+--------+-------+---------------+
| Chun | SQL | 75 | 2 |
| Chun | Tuning | 73 | 2 |
| Esben | SQL | 43 | 2 |
| Esben | Tuning | 31 | 2 |
| Kaolin | SQL | 56 | 2 |
| Kaolin | Tuning | 88 | 2 |
| Tatiana | SQL | 87 | 1 |
+---------+--------+-------+---------------+CREATE TABLE sales (sales_value INT);
INSERT INTO sales VALUES(10),(20),(20),(40);
SELECT SUM(sales_value) FROM sales;
+------------------+
| SUM(sales_value) |
+------------------+
| 90 |
+------------------+
SELECT SUM(DISTINCT(sales_value)) FROM sales;
+----------------------------+
| SUM(DISTINCT(sales_value)) |
+----------------------------+
| 70 |
+----------------------------+De façon générale SUM est utilisé en combinaison avec GROUP BY
CREATE TABLE sales (name CHAR(10), month CHAR(10), units INT);
INSERT INTO sales VALUES
('Chun', 'Jan', 75), ('Chun', 'Feb', 73),
('Esben', 'Jan', 43), ('Esben', 'Feb', 31),
('Kaolin', 'Jan', 56), ('Kaolin', 'Feb', 88),
('Tatiana', 'Jan', 87), ('Tatiana', 'Feb', 83);
SELECT name, SUM(units) FROM sales GROUP BY name;
+---------+------------+
| name | SUM(units) |
+---------+------------+
| Chun | 148 |
| Esben | 74 |
| Kaolin | 144 |
| Tatiana | 170 |
+---------+------------+La clause GROUP BY est requise quand on la combine avec d'autres données au risque d'obtenir des donnée non cohérentes. Voici un exemple d'erreur fréquent:
SELECT `name`, SUM(units) FROM sales;
+------+------------+
| name | SUM(units) |
+------+------------+
| Chun | 536 |
+------+------------+Dans une fonction de fenêtre :
CREATE OR REPLACE TABLE student_test (name CHAR(10), test CHAR(10), score TINYINT);
INSERT INTO student_test VALUES
('Chun', 'SQL', 75), ('Chun', 'Tuning', 73),
('Esben', 'SQL', 43), ('Esben', 'Tuning', 31),
('Kaolin', 'SQL', 56), ('Kaolin', 'Tuning', 88),
('Tatiana', 'SQL', 87);
SELECT name, test, score,
SUM(score) OVER (PARTITION BY name) AS total_score
FROM student_test;
+---------+--------+-------+-------------+
| name | test | score | total_score |
+---------+--------+-------+-------------+
| Chun | SQL | 75 | 148 |
| Chun | Tuning | 73 | 148 |
| Esben | SQL | 43 | 74 |
| Esben | Tuning | 31 | 74 |
| Kaolin | SQL | 56 | 144 |
| Kaolin | Tuning | 88 | 144 |
| Tatiana | SQL | 87 | 87 |
+---------+--------+-------+-------------+SELECT id, GROUP_CONCAT( nom_colonne SEPARATOR ', ' )
FROM table
GROUP BY idSELECT
[ALL | DISTINCT | DISTINCTROW]
select_expr [, select_expr ...]
[ FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position} [ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position} [ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset } ]
Exemples
SELECT
id,
title
FROM
category
WHERE
`status` = 'Published'
LIMIT 10000 OFFSET 10;
-- Equivalent
-- LIMIT 10, 10000;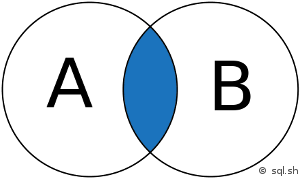 Source :
sql.sh/cours/jointures
Source :
sql.sh/cours/jointures
SELECT *
FROM A
INNER JOIN B ON A.key = B.keyNotons que c'est strictement équivalent à :
SELECT *
FROM A, B
WHERE A.key = B.key-- Sans utiliser le terme JOIN, mais c'est équivalent
SELECT
p.id AS post_id,
p.title AS post_title,
p.`content` AS post_content,
c.title AS category_title
FROM
post AS p,
category AS c
WHERE
p.category_id = c.id
AND p.status = 'Published'
AND p.id = 1;
-- En utilisant la syntaxe JOIN
SELECT
p.id AS post_id,
p.title AS post_title,
p.`content` AS post_content,
c.title AS category_title
FROM
post AS p
INNER JOIN category AS c ON (p.category_id = c.id)
WHERE
p.status = 'Published'
AND p.id = 1;<?php
$sql = 'SELECT
p.id AS post_id,
p.title AS post_title,
p.`content` AS post_content,
c.title AS category_title
FROM
post AS p
JOIN category AS c ON (p.category_id = c.id)
WHERE
p.status = :post_status,
AND p.id = :post_id';
$st = $db->prepare($sql);
$st->execute(
array(
':post_id' => 1,
':post_status' => 'Published'
)
);
$post_1 = $st->fetchAll();Il peut être utile de rassembler des informations venant d'une ligne d'une table avec des informations venant d'une autre ligne de la même table.
Dans ce cas il faut renommer au moins l'une des deux tables en lui donnant un synonyme, afin de pouvoir préfixer sans ambiguïté chaque nom de colonne.
SELECT
c.title AS category_title,
cp.title AS category_parent_title
FROM
category AS c
JOIN category AS cp ON (cp.id = c.parent_id)
WHERE
-- exclure les catégories racine
c.parent_id NOT IS NULL
AND c.parent_id != c.id;
+-----------------+-----------------------+
| category_title | category_parent_title |
+-----------------+-----------------------+
| MySQL / MariaDB | Cours |
+-----------------+-----------------------+
SELECT
p.id AS post_id,
p.title AS post_title,
c.title AS category_title
FROM
post AS p
RIGHT OUTER JOIN post_category AS pc ON (pc.post_id = p.id)
RIGHT OUTER JOIN category AS c ON (c.id = pc.category_id);
+---------+----------------------------+-----------------+
| post_id | post_title | category_title |
+---------+----------------------------+-----------------+
| NULL | NULL | Non Classé |
| 1 | MySQL Initiation (3 jours) | Cours |
| 1 | MySQL Initiation (3 jours) | MySQL / MariaDB |
+---------+----------------------------+-----------------+La jointure externe ajoute des lignes fictives dans une des tables pour faire la correspondance avec les lignes de l'autre table. Dans l'exemple précédent, une ligne fictive (une catégorie fictive) est ajoutée dans la table des catégories si un post n'a pas de catégorie. Cette ligne aura tous ses attributs null, sauf celui des colonnes de jointure.
RIGHT indique que la table dans laquelle on veut afficher toutes les lignes (la table post) est à droite de RIGHT OUTER JOIN. C'est dans l'autre table (celle de gauche) dans laquelle on ajoute des lignes fictives. De même, il existe LEFT OUTER JOIN qui est utilisé si on veut afficher toutes les lignes de la table de gauche (avant le LEFT OUTER JOIN) et FULL OUTER JOIN si on veut afficher toutes les lignes des deux tables.
Syntaxe :
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [PARTITION (partition_list)] [(col,...)]
{VALUES | VALUE} ({expr | DEFAULT},...),(...),...
[ ON DUPLICATE KEY UPDATE
col=expr
[, col=expr] ... ] [RETURNING select_expr
[, select_expr ...]]Ou :
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [PARTITION (partition_list)]
SET col={expr | DEFAULT}, ...
[ ON DUPLICATE KEY UPDATE
col=expr
[, col=expr] ... ] [RETURNING select_expr
[, select_expr ...]]Ou :
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name [PARTITION (partition_list)] [(col,...)]
SELECT ...
[ ON DUPLICATE KEY UPDATE
col=expr
[, col=expr] ... ] [RETURNING select_expr
[, select_expr ...]]Exemple :
INSERT INTO `category` (
`id`,
`parent_id`,
`slug`,
`title`,
`content`,
`created_at`,
`updated_at`
) VALUES
(1, NULL, 'non-classe', 'Non Classé', '', '2021-05-30 16:46:52', NULL),
(2, 2, 'cours', 'Cours', '', '2021-05-30 16:47:38', NULL),
(3, 2, 'mysql', 'MySQL', '', '2021-05-30 16:48:18', NULL);Single-table syntax:
UPDATE [LOW_PRIORITY] [IGNORE] table_reference
[PARTITION (partition_list)]
SET col1={expr1|DEFAULT} [,col2={expr2|DEFAULT}] ...
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]Multiple-table syntax:
UPDATE [LOW_PRIORITY] [IGNORE] table_references
SET col1={expr1|DEFAULT} [, col2={expr2|DEFAULT}] ...
[WHERE where_condition]Exemple :
UPDATE `category`
SET `title` = 'MySQL / MariaDB'
WHERE
id = 3;Single-table syntax:
DELETE [LOW_PRIORITY] [QUICK] [IGNORE]
FROM tbl_name [PARTITION (partition_list)]
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
[RETURNING select_expr
[, select_expr ...]]Syntaxe multiple-table :
DELETE [LOW_PRIORITY] [QUICK] [IGNORE]
FROM tbl_name[.*] [, tbl_name[.*]] ...
USING table_references
[WHERE where_condition]Exemples :
DELETE p
FROM post p
JOIN category c ON c.id = p.category_id
WHERE
c.id = :category_idUsage de la clause RETURNING :
-- How to use the RETURNING clause:
DELETE FROM t RETURNING f1;
+------+
| f1 |
+------+
| 5 |
| 50 |
| 500 |
+------+CREATE [OR REPLACE] {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_specification] ...
create_specification:
[DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
| COMMENT [=] 'comment'
Exemple :
CREATE OR REPLACE DATABASE ma_premiere_db
CHARACTER SET = 'utf8mb4'
COLLATE = 'utf8mb4_general_ci';
-- équivalent à
DROP DATABASE IF EXISTS ma_premiere_db;
CREATE DATABASE ma_premiere_db;Exemple :
CREATE TABLE `post` (
`id` int AUTO_INCREMENT PRIMARY KEY,
`status` enum('Draft','Waiting','Published') NOT NULL DEFAULT 'Draft',
`type` set('','Featured','News','Article','Video','Product') NOT NULL DEFAULT '',
`slug` varchar(255) NOT NULL,
`title` varchar(255) NOT NULL,
`content` longtext NOT NULL,
`comments_open` int NOT NULL DEFAULT 0,
`comments_count` int DEFAULT NULL,
`published_at` datetime DEFAULT current_timestamp(),
`created_at` datetime NOT NULL DEFAULT current_timestamp(),
`updated_at` datetime DEFAULT NULL,
`category_id` int NOT NULL,
CONSTRAINT fk_post_category_id
FOREIGN KEY (category_id)
REFERENCES category (id)
ON UPDATE CASCADE
ON DELETE RESTRICT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;Pour vous simplifier la vie vous utiliserez phpMyAdmin :)