A-tomicity C-onsistency I-solation D-urability
Indexing will create an index table whcih will have an underlying pointer to the document in the table, this allow improved searching such as using binary trees, binary search etc.

We introduce a different data index instead of ordering the true data because there may be in occassion where we want to order the datas differently(based on 2 columns or more). Managing the constant reordering of database table is very time consuming.
In NoSQL database, index are mostly created as composite index hence we cannot avoid the redundancy/discouraging the use of normalization.
The key chose must be a uniform key such that the data is distributed uniformly. We can assume that the has function provided by database is already a uniform hash algorithm.
The index is usually a B-Tree, which means that if the index is (type, status, user_id) the database can normally still use it to search for (type, status) because it's the first part of the combined index. But that would not be the case if you use (status, user_id).


Clustered index means that the rows are stored physically closed to each other on the disk. Therefore there can only be one clustered index. Each new index will increase the time it takes to write new records because the rows have to be rearranged. Read on clustered index will generally be faster because we can directly read from the table(already sort close to each other).
Advantages: backup, scale out read operations Master-Slave pattern is most commonly used(must be odd video)
- Never allowed servers to send write commands to slave
- Propagate the to query to a master server
- Both Master nodes, this is an anti-pattern because in a distributed environment, if the connection breaks, both A and B will think themselves as master servers and will both write different data.
Solution is distributed consensus: A way which multiple nodes agree on a value. Some common protocols are 2Phase Commit, 3 Phase Commit, Multi Version Concurrency Control(MVCC), SAGA.
2PC - coordinator asks all of the followers to commit a transactions. Then every follower executes the command and if it succeeds then it replies with an agreement to commit, otherwise it replies with an abort. That is the first phase, the voting phase. When all agreement messages are received, coordinator commits the transaction. If there is an abort message from any follower, the coordinator aborts the transaction. This is the second phase, the completion phase.
MVCC(PostGres), it keeps multiple copies of the same data, depending on the setting, it can allow dirty reads, no phantom reads etc based on setting. SAGA, it's a really long transaction which for any point that may fail, for example if you have multiple withdraws from your bank account, it will first lock the total amount, then break it into multiple small transaction. At the end then it will decide if the SAGA is completed or all should be rolled back.
Commit: After all instructions of a transaction are successfully executed, the changes made by transaction are made permanent in the database. Rollback: If a transaction is not able to execute all operations successfully, all the changes made by transaction are undone.
Properties of a transaction
- Atomicity: As a transaction is set of logically related operations, either all of them should be executed or none. A debit transaction discussed above should either execute all three operations or none.
- Abort: If a transaction aborts, changes made to database are not visible.
- Commit: If a transaction commits, changes made are visible.
- Consistency: Database must be consistent before and after the trnasaction.
- Isolation: Result of a transaction should not be visible to others before transaction is committed (Dirty reads)
- This property ensures that the execution of transactions concurrently will result in a state that is equivalent to a state achieved these were executed serially in some order.
- Durable: Once database has committed a transaction, the changes made by the transaction should be permanent.
- persist even if a system failure occurs.
A schedule is a series of operations from one or more transactions. A schedule can be of two types:
- Serial Schedule: When one transaction completely executes before starting another transaction, the schedule is called serial schedule
- Concurrent Schedule: When operations of a transaction are interleaved with operations of other transactions of a schedule.
Recovery techniques are heavily dependent upon on a special file known as system log. It contains the start and end of each transaction and any updates which occur. It can be used incase of recovery or failure. A transaction reaches it's commit point when all operations execute successfully.
- Undoing - if atranscation crashes, recovery manager will undo transaction
- Deferred update - does not update database until a transaction reaches it's commit point
- Immediate Update - database is immediately updated, but there is an additional log file for roll back/undo in case
- Caching/Buffering - data items to be updated are cached into main memory before written back to disk
- shadow paging - the current directory is copied into shadow copy. A shadow page contains all updates which will be written to disk once it is ready to become durable.
- Dirty Read - A dirty read is when a transaction reads data that has not yet been committed. If transaction 1 rolls back a data, but transaction 2 reads the updated data.
- Non Repeatable Read - When a transaction reads the same row twice and get different data. Transaction 1 read data while T2 writes. T1(R) -> T2(W) -> T1(R')
- Phantom Read - Same as dirty read but happens on committed data.
- Read Uncommitted - Lowest isolation level, one transaction may read not yet committed changes(allowing dirty read)
- Read Commmitted - Guarantees any data read is committed at the moment of read. Holds a read or write lock on the current row, hence prevent other transactions from reading, updating or deleting it
- Repeatable Read - Most Restrictive Isolation level. It holds read locks on all row references and write locks on all CUD operation. Other transaction cannot do CRUD, avoid non-repeatable read.
- Serializable - Highest isolation level, an execution of operations in which concurrently executing transactions appears to be serially executing.
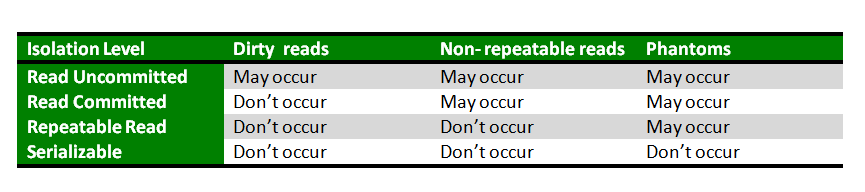
Read committed is an isolation level that guarantees that any data read was committed at the moment is read. It simply restricts the reader from seeing any intermediate, uncommitted, 'dirty' read. It makes no promise whatsoever that if the transaction re-issues the read, will find the Same data, data is free to change after it was read.
Repeatable read is a higher isolation level, that in addition to the guarantees of the read committed level, it also guarantees that any data read cannot change, if the transaction reads the same data again, it will find the previously read data in place, unchanged, and available to read.
The next isolation level, serializable, makes an even stronger guarantee: in addition to everything repeatable read guarantees, it also guarantees that no new data can be seen by a subsequent read.
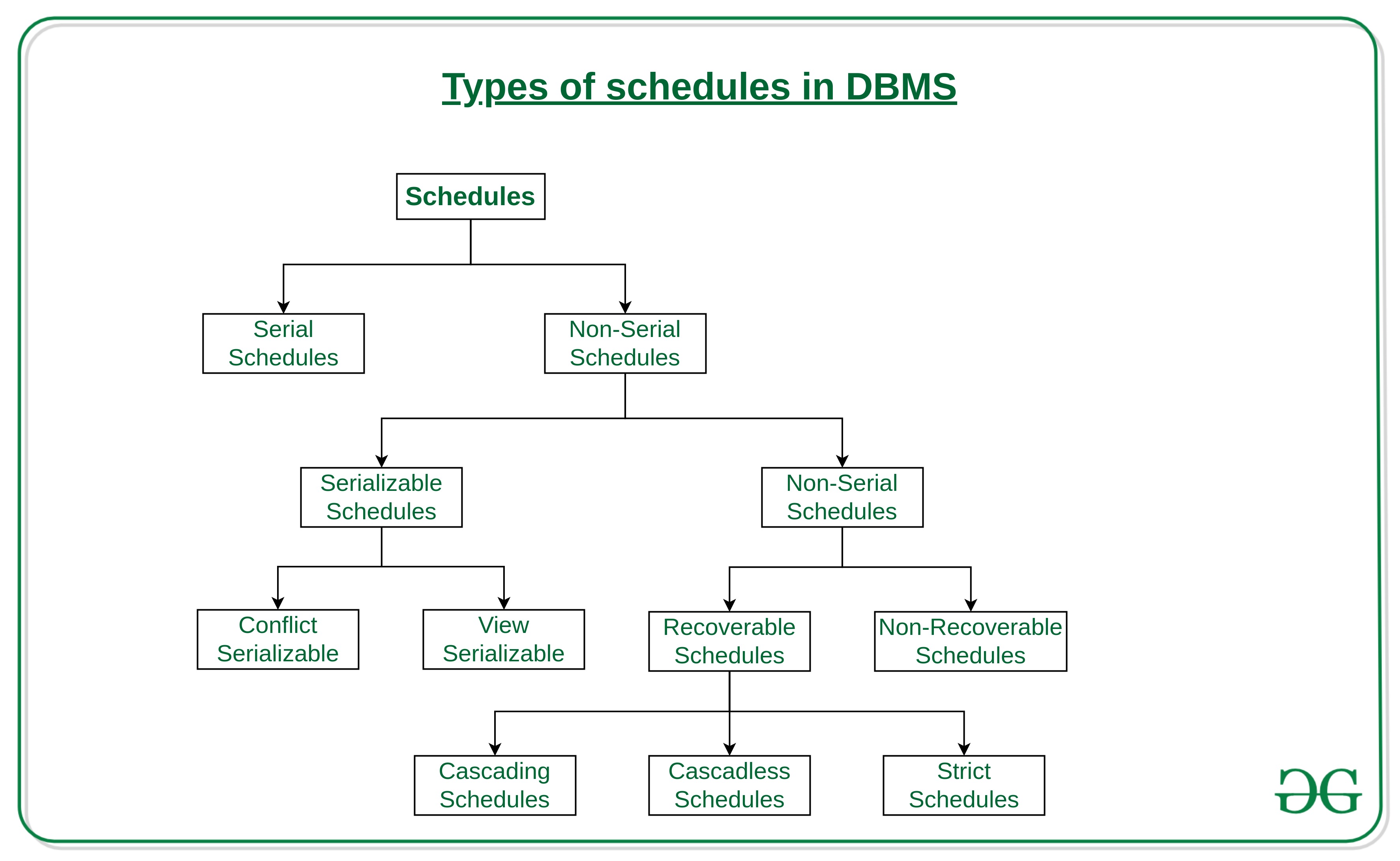
- Serial Schedules - no transaction starts until another completes
- Non-Serial Schedules - Transactions are interleaved
- Serializable Schedule
- Conflict Serializable, can be converted to serial schedule by swapping operations
- View Serializable, cannot contain blind writes
- Non-Serilizable
- Recoverable Schedules - Cascading Schedule(T1->T2->T3) T3 Fail will cause roll backs, Cascadeless Schedule(only read data when previous transaction commits), Strict Schedule(even read are locked)
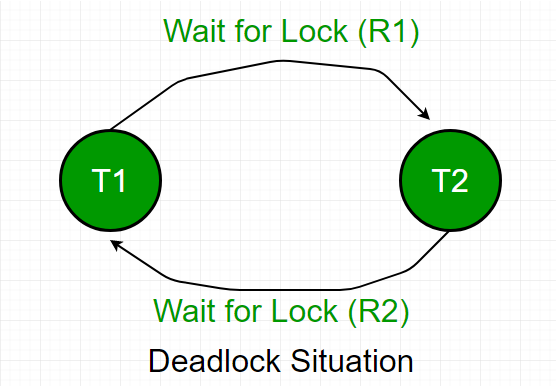
Two or more transactions waiting indefinitely for one another to give up locks. T1 holds a lock on some rows to update. T2 holds the lock for the rows that T1 needs, but need to update the row that T1 is holding. All activity will come to a halt until one transaction aborts.
Strategies:
Deadlock Avoidance is always better than restarting or aborting the database. Avoidance is suitable for smaller database while deadlock prevention is suitable for larger database. It can be done using application consistent logic, T1 always happen before T2
Deadlock Detection The DBMS should detect the transaction involved in the deadlock using Wait-For-Graph! Cyclic Detection algorithm involves tortoise and hare algorithm
Deadlock Prevention to allocate resource in such a way that deadlock never occur.
- Wait-Die Scheme - if T1<T2, T1 waits, else T1 restarts
When an older transaction tries to lock a DB element that has been locked by a younger transaction, it waits. When a younger transaction tries to lock a DB element that has been locked by an older transaction, it dies. - Wound Wait Scheme - if T1>T2, T1 waits but kills/wound T2 and force it to restart
When an older transaction tries to lock a DB element that has been locked by a younger transaction, it wounds the younger transaction. When a younger transaction tries to lock a DB element that has been locked by an older transaction, it waits. Both schemes prefer older transactions with an older timestamp. Old transaction normally holds more lock and is more expensive to abort.
Starvation or Livelock is the situation when a transaction has to wait for a indefinite period of time to acquire a lock. Happens when:
- If waiting scheme for locked items is unfair. ( priority queue )
- Victim selection. ( same transaction is selected as a victim repeatedly )
- Resource leak.
- Via denial-of-service attack.
Strategy:
- Increasing Priority - increase priority the longer someone stays in queue
- Modification in Victim Selection algorithm - change algorithm to lower it's priority
- First Come First Serve
- Wait Die and Wound Wait
It is required in this protocol that all the data items must be accessed in a mutually exclusive manner. The two most common locks are
- Shared Lock(S) - Read only lock
- Exclusive Lock(X) - Data item can both read as well as written
T is allowed to upgrade a S(T) lock to X(T) lock if he's the only transaction holding S-lock. We can downgrade X(T) to S(T) when we no longer want to write data on item A, as it's an X-lock, no conditions need to be checked.
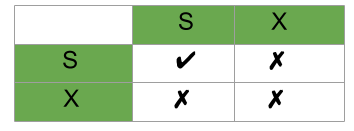
A transaction is said to follow Two Phase Locking protocol if Locking and Unlocking can be done in two phases.
- Growing Phase: New locks on data items may be acquired but none can be released.
- Shrinking Phase: Existing locks may be released but no new locks can be acquired.
Note – If lock conversion is allowed, then upgrading of lock( from S(a) to X(a) ) is allowed in Growing Phase and downgrading of lock (from X(a) to S(a)) must be done in shrinking phase.

Disadvantages:
- Cascading Rollback is possible under 2-PL.
- Deadlocks and Starvation is possible.

Solution:
- Strict 2-PL - all Exclusive(X) Locks held by the transaction be released until after the Transaction Commits. (Deadlocks are possible)
- Rigorous 2-PL - all Exclusive(X) and Shared(S) Locks held by the transaction be released until after the Transaction Commits.
- Conservative 2-PL - all the items it access before the Transaction begins execution. If it cannot lock, it waits
The main idea for this protocol is to order the transactions based on their Timestamps. Each transaction is given a timestamp when they enter the system.
W_TS(X) is the largest timestamp of any transaction that executed write(X) successfully.
R_TS(X) is the largest timestamp of any transaction that executed read(X) successfully.
if latest successful is more than timestamp of transaction, abort and rollback. f R_TS(X) > TS(T) or if W_TS(X) > TS(T), then abort and rollback T and reject the operation
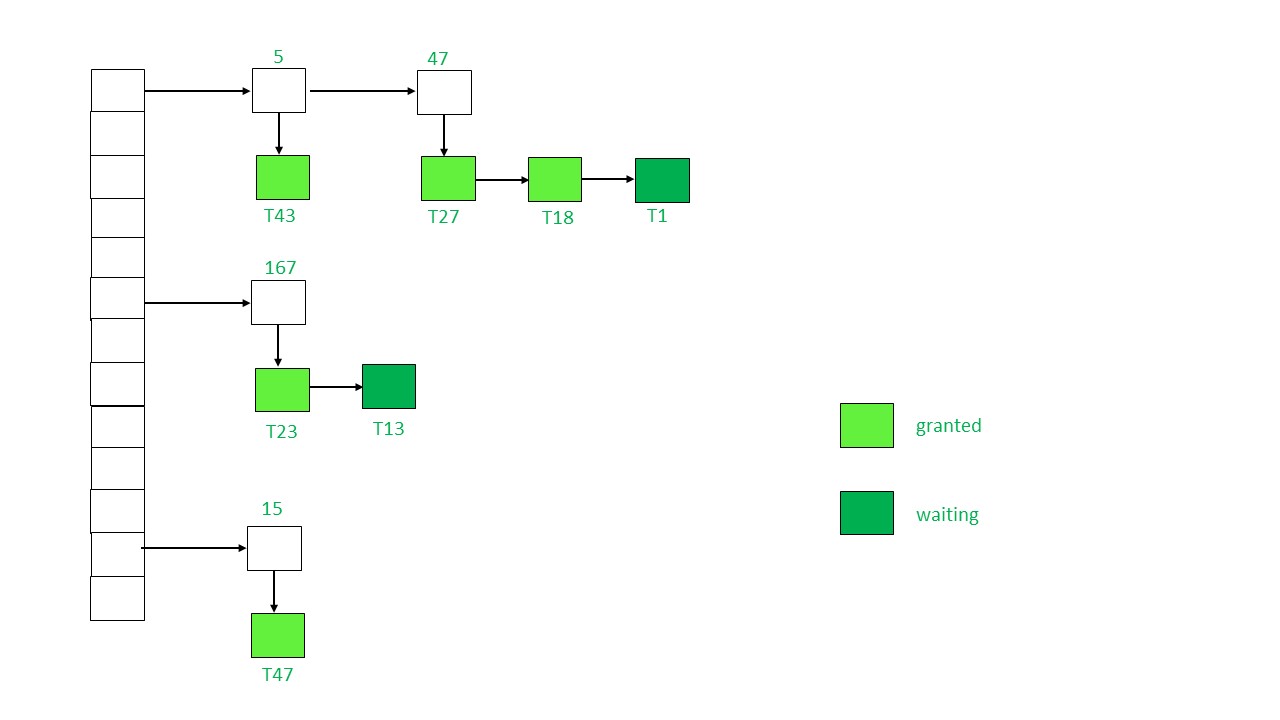
The data structure required for implementation of locking is called as Lock table.
- It is a hash table where name of data items are used as hashing index.
- Each locked data item has a linked list associated with it.
- Every node in the linked list represents the transaction which requested for lock, mode of lock requested (mutual/exclusive) and current status of the request (granted/waiting).
- Every new lock request for the data item will be added in the end of linked list as a new node. Collisions in hash table are handled by technique of separate chaining.
- Initially the table is empty
- When a new lock request is received for transaction T:
- Item is not locked, add a linked list and grant the lock
- Item is locked, add a new node
- If the lock mode requested is compatible with the transaction lock, T will acquire the lock and become
granted, else it will bewaiting - If an item wants to unlock the lock, it will send a request and the lock manager will remove the node. Lock will be granted to next item in the node list.
- If the transaction is aborted, all the waiting request by T will be deleted from the lock table. Once completed, locks will be released.