
An open source project to help you learn about system design step by step
NOTE: The work on this repo is still in progress. Some information might be lacking or missing at this point.
- Topics
- Topics Explained
- Exercises
- Questions
- Resources
- System Design
- System Design Process
- Interview Tips
- Q&A
- Credits
 Requirements |
 Functional Requirements |
 Non-Functional Requirements |
 Server |
 Client |
 Load Balancer |
 API Gateway |
 DNS |
 Scalability |
Horizontal Scaling |
Vertical Scaling |
 Scalability Factor |
 Availability |
 Failover |
|
 Cold Standby |
 Warm Standby |
 Hot Standby |
 Networking |
 Databases |
 CAP Theorem |
 Distrubuted Systems |
 Clock Diff |
 CDN |
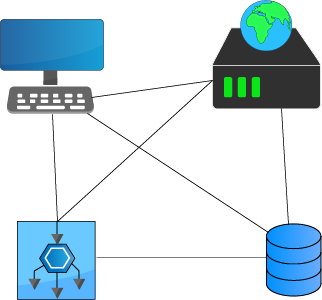
The following is an architecture of a server which runs a web server and a database on it. There are a dozen of clients connecting to the server. Answer the following questions
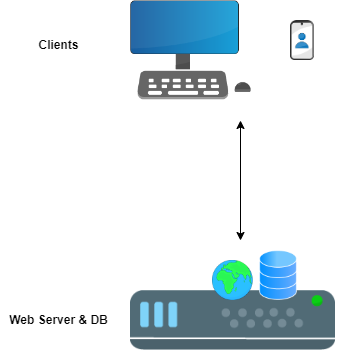
- Name two issues with this architecture
- What term/concept in system design used to describe one of the issues you specified?
- Suggest an improvement to the architecture WITHOUT adding more components
- If the suggested improvement is "vertical scaling", is it a permanent improvement?
- Suggest two improvements to the architecture, given that additional components can be added

- What term/concept in system design used to describe one of the issues you specified?
- If the suggested improvement is "vertical scaling", is it a permanent improvement?
-
Two issues:
- Single point of failure - if the server is down, the users would not be able to connect the application and the server will have to be restored or created from scratch
- If the web process is using all the RAM and/or CPU, then it might affect the DB since it won't have enough resource to handle requests. This is true also the opposite way of DB consuming all resources, not leaving enough for web server processes.
- The term used to describe the issue it "scalability". The server doesn't scale by demand and eventually users will experience issues
-
Apply vertical scaling. By adding more resources to the server (i.e. CPU & RAM) it will allow it to handle more load. This is nota permanent solution because at some point the load might scale to a point where it's not possible to add more RAM and CPU to the instance nor it's really worthwhile.
-
The two improvements would be:
- Separate DB and web server into two components (instead of both running on the same instance)
- Apply horizontal scaling - add more web server servers (it's also possible to add more DB instances)

Design the most basic architecture for a web application (server based) that tells a single user what time is it (no DB, no scaling, ...) with maximum of two components

In this case what you need is two components:
- EC2 instance - this is where our application will run. A basic micro t2 instance is more than enough
- Elastic IP address - This is the static IP address our user will use every time to reach the application. In case the instance is not operational, we could always move the IP address to one that it is (if we manage more than one instance)
Your web app became a huge success and many users start using it. What might be the problem with moving from one user to multiple users and how to deal with it using a single improvement of the architecture?
Your instance might not be strong enough to handle requests from multiple users and soon enough you might see RAM and CPU utilized fully. One way to deal with it is, to perform what is called "Vertical Scaling" which is the act of adding more resources to your instance. In AWS case, switching to an instance type with more resources like M5 for example.
Note: The problem with vertical scaling (in case you have one node) is downtime (when upgrading the instance type, the instance will be down) so another thing you would want to do is "Horizontal Scaling" which is the act of adding more instances/resources.

You would like to change the architecture offered in the solution, to not use elastic IP addresses for obvious reasons that it's not really scalable (each EC2 instance has a different IP and users are not able to remember them all). Offer an improvement
Instead of using elastic IP addresses we can add a record in the DNS, using the Route 53 service, to have a record from the type A. This way, all users will be able to access the app using an hostname and the IP address will be provided to them by the DNS

It's important to note that this solution is not optimal if you plan to scale down and up at some point. Due to the TTL value of a record, a user will keep contacting the same IP address, even if the node is already down.
A more proper and complete architecture would be to use an ELB

But even with ELB used and "Auto scaling group" for automatically scaling the nodes, this architecture is not optimal. Can you point what is the problem with current architecture? (from two different aspecs)
State the issues with current architecture and what would you imrpove
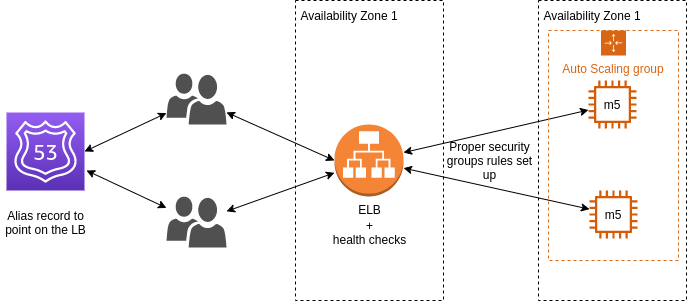
With current architecture, the application is perhaps able to scale up and down, but when the availability zone is down, your entire application is down. So the first improvement would be to make both ELB and the application itself (the EC2 instances) multi-AZ.
Secondly, if you know you always need an instance (or two) for the application, you might want to have reserved nodes. Reserved nodes means you pay less for instances which means you save on costs.

The following architecture was proposed for an online video games shop with the requirements of:
- Support thousands of users at any given point of time
- Users can register
- Shopping cart items shouldn't be lost when the user browsing the store
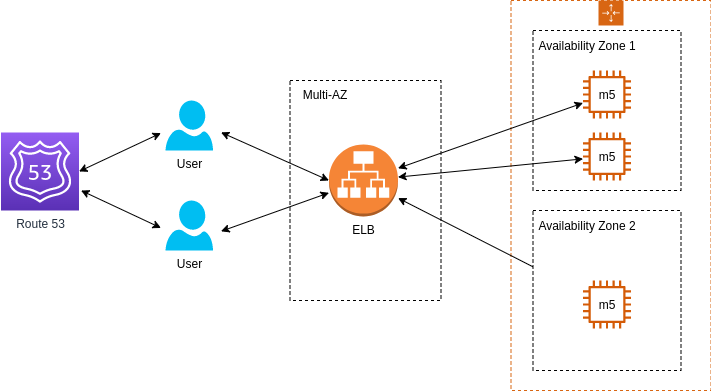
The problem is that users report that when they browse for additional video games to buy, they lose their shopping cart. What is the problem with the current architecture and how to deal with it?

Such application is a stateful application, meaning it's important that we'll keep the information about the client from one session to another. It seems that with current architecture, every time the user initiates new session, it's perform against a different instance without saving client information.
There are a couple of solutions that can be applied in this case:
- Load Balancer Sticky Sessions: users will be redirected to the instance they initiated previously session with, in order to to not lose client's data. There is a disadvantage here of losing
- User cookies: the client/user stores the relevant data (shopping cart in this case) and in this case it doesn't matter with which EC2 instance the user interacts with, the data on the shopping cart will be sent from the client/user to the relevant instance. The disadvantages: HTTP requests are much heavier because data is attached with each request and it holds some security risks as cookies can be potentially modified
Following the last exercise, is there another way to deal with user's data (short and long term) except user's cookies and sticky sessions?
There is something called "server session" where we need to add a new component to the architecture - ElastiCache or DynamoDB, to store the data on the shopping cart of each user. In order to identify it, we'll use a session ID which will be sent by the client/user every request
For long term data (user name, address, etc.) we'll use a database (e.g. RDS). There are a couple of variations as to how we can use it. A master instance where we'll write the data and a replication from which we'll read data:

A different approach can be to use Cache + DB, where for each session, we'll check if the data is in the cache and if it's not, then we'll access the DB (this is also called "Write Through"):

Note: Exercises may repeat themselves in different variations to practice and emphasize different concepts.
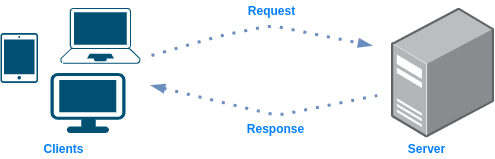
You have the following simple architecture of a server handling requests from a client. What are the drawbacks of this design and how to improve it?

-
Limitations:
- Load - at some point it's possible the server will not be able to handle more requests and it will fail or cause delays
- Single point of failure - if the server goes down, nothing will be able to handle the requests
-
How to improve:
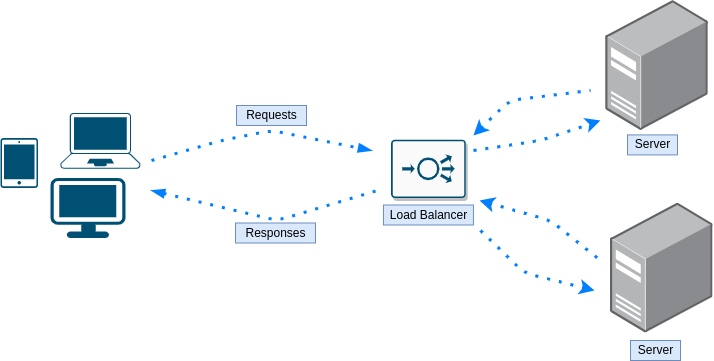
-
Further limitations:
- Load was handled as well as the server being a single point of failure, but now the load balancer is a single point of failure.

Is there a way to improve the above design without adding an actual load balancer instance?
Yes, one could use DNS load balancing.
Bonus question: which algorithm a DNS load balancer will use?
What are the drawbacks of round robin algorithm in load balancing?
- A simple round robin algorithm knows nothing about the load and the spec of each server it forwards the requests to. It is possible, that multiple heavy workloads requests will get to the same server while other servers will got only lightweight requests which will result in one server doing most of the work, maybe even crashing at some point because it unable to handle all the heavy workloads requests by its own.
- Each request from the client creates a whole new session. This might be a problem for certain scenarios where you would like to perform multiple operations where the server has to know about the result of operation so basically, being sort of aware of the history it has with the client. In round robin, first request might hit server X, while second request might hit server Y and ask to continue processing the data that was processed on server X already.
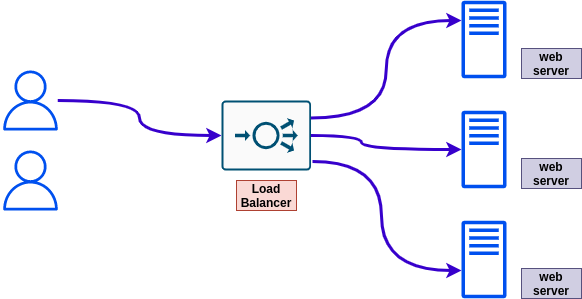
The following is an architecture of a load balancer serving and three web servers. Assuming, we would like to have a secured architecture, that makes sense, where would you set a public IP and where would you set a private IP?
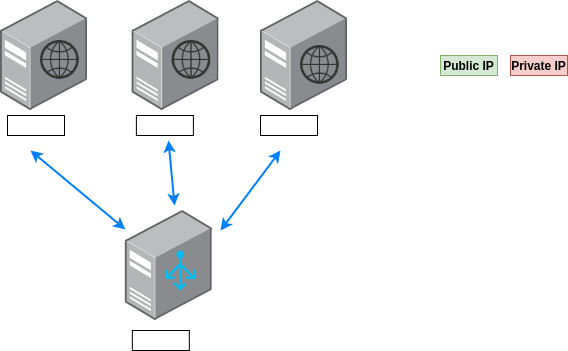


It makes sense to hide the web servers behind the load balancers instead of giving users direct access to them, so each one of them will have a private IP assigned to it. The load balancer should have a public IP since, we except anyone who would like to access a certain web page/resource, to go through the load balancer hence, it should be accessible to users.
What load balancing techniques are there?
- Round Robin
- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
The following is a simple architecture of a client making requests to web server which in turn, retrieves the data from a datastore. What are the drawbacks of this design and how to improve it?
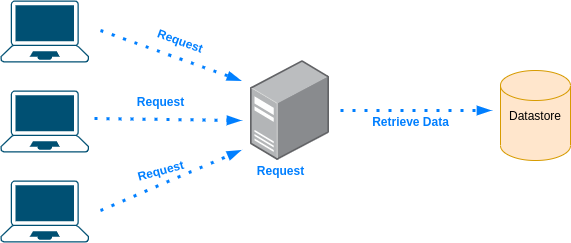

-
Limitations:
- Time - retrieving the data from the datastore every time a request is made from the client, might take a while
- Single point of failure - if the datastore is down (or even slow) it wouldn't be possible to handle the requests
- Load - the datastore getting all the requests can result in high load on the datastore which might result in a downtime
-
How to improve:
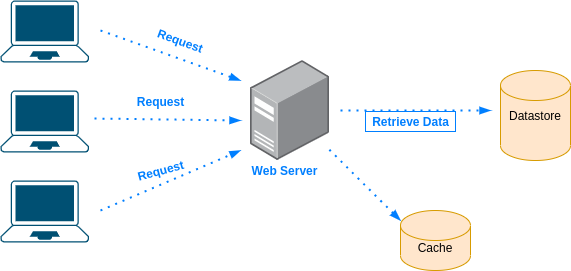

Are you able to explain what is Cache and in what cases you would use it?
Why to use cache?
- Save time - Accessing a remote datastore, and in general making network calls, takes time
- Reduce load - Instead of the datastore handling all the requests, we can take some of its load and reduce by accessing the cache
- Avoid repetitive tasks - Instead of querying the data and processing it every time, do it once and store the result in the cache
Why not storing everything in the cache?
For multiple reasons:
- The hardware on which we store the cache is in some cases much more expensive
- More data in the cache, the bigger it gets and longer the put/get actions will take
The following is a system design of a remote database and three applications servers
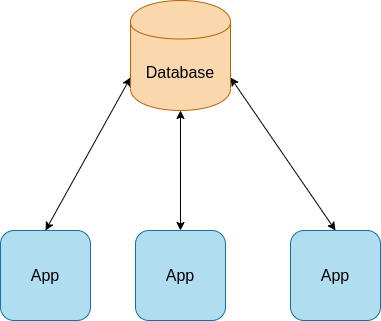

-
Limitations:
- Latency. Every query made to the remote database will hit latency, even if small.
- In case the remote database crashes, the app will stop working
-
How to improve:
* Replicate each database to the local app server. This has several advantages. First, we are not bound to latency anymore. Secondly, a fai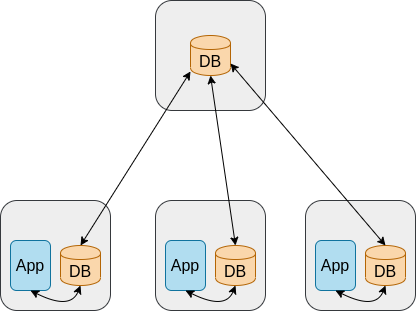
-
Further limitations:
- We are bound now to bandwidth
- If the remote database isn't accessible for a long period of time, we'll have an outdated database and each app has the potential to work against a different DB
The following is an improvement of the previous system design

-
Limitations:
- Queries to database might be slow, even on the server itself where the app is running
- Once the remote database isn't available, the local databases will not by in sync
-
How to improve:
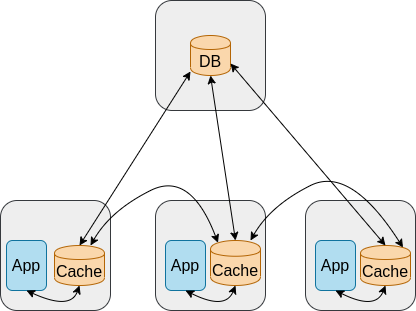

Every request sent by the same client, is routed every time to a different web server. What problem the user might face with such design? How to fix it?

- The problem: the user might need to authenticate every single request, because different web servers handle its requests.
- A possible solution: use sticky sessions where the user is routed to the same instance every single time

You have a design of load balancer and a couple of web instances behind it. Sometimes the instances crash and the user report the application doesn't works for them. Name one possible way to deal with such situation.
One possible way to deal with it, is by using health checks. Where an instance that doesn't pass the health check, will be excluded from the list of instances used by the load balancer to forward traffic to.

You have a production application using a database for reads and writes. Your organization would like to add another application to work against the same database but for analytics purposes (read only). What problem might arise from this new situation and what one improvement you can apply to the design?
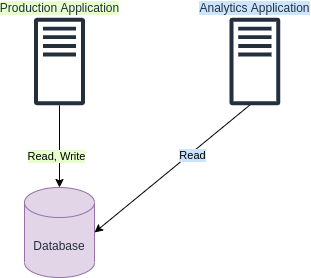

Adding another application to work against the same database can create additional load on your database which may lead to issues since the additional load might reach the limits of your database capacity constraints.
One improvement to the design could be to add a read replica instance of your database. This way the new application can work against the read replica instead of the original database. The replication will be asynchronous but in most cases, for analytics applications, that's good enough.

This is a more "simplified" version of exercises section. No drawings, no evolving exercises, no strange exercises names, just straightforward questions, each in its own category.
Your website usually serves on average a dozen of users and has good CPU and RAM utilization. It suddenly becomes very popular and many users try to access your web server but they are experiencing issues, and CPU, RAM utilization seems to be on 100%. How would you describe the issue?
Scalability issue. The web server doesn't scales :'(
In order to avoid such issues, the web server has to scale based on the usage. More users -> More CPU, RAM utilization -> Add more resources (= scale up). An
When there are less users accessing the website, scale down.
Tell me everything you know about Cache
True or False? While caching can reduce load time, it's increasing the load on the server
False. If your server doesn't have to execute the request since the result is already in the cache, then it's actually the opposite - there is less load on the server in addition to reduced load times.
What is a DNS?
Can you use DNS for load balancing?
What is RAID?
What is CDN?
How operating systems able to run tasks simultaneously? for example, open a web browser while starting a game
The CPU have multiple cores. Each task is executed by a different core.
Also, it might only appear to run simultaneously. If every process is getting CPU allocation every nanosecond, the user might think that both processes are running simultaneously.
What is a VPS?
From wikipedia: "A virtual private server (VPS) is a virtual machine sold as a service by an Internet hosting service."
True or False? VPS is basically a shared server where each user is allocated with a portion of the server OS
False. You get a private VM that no one else can or should use.
What are some of the challenges one has to face when designing and managing distributed systems, but not so much when dealing with systems/services running on a single host?
There many great resources out there to learn about system design in different ways - videos, blogs, etc. I've gathered some of them here for you
Scalability
- awesome-scalability - "An updated and organized reading list for illustrating the patterns of scalable, reliable, and performant large-scale systems"
Videos
- Gaurav Sen - Excellent series of videos on system design topics
- System Design Interview - How to get through system design interviews. Covering both architecture and code
Repositories
- awesome-scalability - "An updated and organized reading list for illustrating the patterns of scalable, reliable, and performant large-scale systems"
- system-design-primer - "Learn how to design large-scale systems. Prep for the system design interview."
Books
This section focusing on the development aspect of system design (e.g. Version Control, Development Environment, etc.). Note: it might overlap with other sections such 'Cloud System Design'.
For each scenario try to identify the following:
- Problem Statement & Analysis
- Solution(s)
You are part of a team which owns a Git monorepo. Recently this monorepo grown quite a lot and now includes hundred thousands of files. Recently, developers in your team complain it takes a lot of time to run some Git commands, especially those related to filesystem state (e.g. git status takes a couple of seconds or even minutes). What would you suggest the team to do?
Let's start with stating the facts:
- The repo has grown to include million of files
- It takes seconds or minutes to run Git operations while usually it takes approximately 1-2 seconds at most
Next, it would be good to understand how exactly these different commands work in order to understand what we can do about the problem.
In case of git status, it runs diffs on HEAD and the index and also the index and working directory, to understand what is being tracked and what's not. This results in running lstat() system call which returns a struct on each file (including information like device ID, permissions, inode number, timestamp info, etc.). Running this on hundred thousands of files takes time, which explains why git status takes seconds, if not minutes, to run.
The solution should be focusing on how Git can perform less work in regards to its operations. In this case it's very technology specific, but there is always something to learn, even in specific implementations, on the general design approach.
- Use the built-in
fsmonitor(filesystem monitor) of Git. With fsmonitor (which integrated with Watchman), Git spawn a daemon that will watch for any changes continuously in the working directory of your repository and will cache them . This way, when you rungit statusinstead of scanning the working directory, you are using a cached state of your index.

-
Enable
feature.manyFilewithgit config feature.manyFiles true. This does two things: -
Sets
index.version = 4which enables path-prefix compression in the index -
Sets
core.untrackedCache=truewhich by default is set tokeep. The untracked cache is quite important concept. What it does is to record the mtime of all the files and directories in the working directory. This way, when time comes to iterate over all the files and directories, it can skip those whom mtime wasn't updated.
Before enabling it, you might want to run git update-index --test-untracked-cache to test it out and make sure mtime operational on your system.
-
Git also has the built-in
git-maintainencecommand which optimizes Git repository so it's faster to run commands likegit addorgit fatchand also, the git repository takes less disk space. It's recommended to run this command periodically (e.g. each day). -
Track only what is used/modified by developers - some repositories may include generated files that are required for the project to run properly (or support certain accessibility options), but not actually being modified by any way by the developers. In that case, tracking them is futile. In order to avoid populating those file in the working directory, one can use the
sparse checkoutfeature of Git. -
Finally, with certain build systems, you can know which files are being used/relevant exactly based on the component of the project that the developer is focusing on. This, together with the
sparse checkoutcan lead to a situation where only a small subset of the files are being populated in the working directory. Making commands likegit add,git status, etc. really quick
This section covers system designs of different types of applications. Nothing too specific, but yet quite common in the real world as a type of application.
For each type of application we are going to mention its:
- Requirements
- API endpoints (public and internal)
Design a payment and reservation system for parking garages that supports three type of vehicles:
- regular
- large
- compact
With flat rate based on vehicle type and time
Note: if you've been told to design this type of system without any other requirements, the rate and special parking, is something you should ask about.
Ask clarifying questions such as:
- Who are the users and how they are going to use the system?
- What inputs and outputs should the system support?
- How much data do we expect the system to handle?
- How many requests per second?
- User to be able to reserve a parking spot and receive a ticket
- User can't reserve a parking spot reserved by someone else
- System to support the following types of vehicles: regular, large and compact
- System to support flat rate based on vehicle type and time the vehicle spent in the parking
-
/reserve- Parameters: garage_id, start_time, end_time
- Returns: (spot_id, reservation_id)
-
/cancel- Parameters: reservation_id
-
/payment- Parameters: reservation_id
- Use existing API like Squre, PayPal, Stripe, etc.
-
/calculate_payment- calculate the payment for reserving a parking spot- Parameters: reservation_id
-
/free_spots- get free spots where the car can park (note: small car might be able to park in bigger car spot)- Parameters: garage_id, vehicle_type, time
-
/allocate_spot- do the actual reservation of a parking spot- Parameters: garage_id, vehicle_type, time
-
/create_account- the ability to create an account so users can use the app and reserve parking spots- Parameters: email, username, first_name (optional), last_name (optional), password (optional)
-
/login- Parameters: email, username (optional), password
We can assume that the number of users is limited to the number of parking spots in each garage and taking into account the number of garages of course.
Given that, users scale is pretty predictable and can't reach unexpected count (assuming no new garages can be added or fixed rate of new garages being added)
SQL based database with the following tables
Reservations
| Field | Type |
|---|---|
| id | primary key, serial |
| start | timestamp |
| end | timestamp |
| paid | boolean |
Garages
| Field | Type |
|---|---|
| id | primary key, serial |
| zipcode | varchar |
| rate_compact | decimal |
| rate_compact | decimal |
| rate_regular | decimal |
| rate_large | decimal |
Spots
| Field | Type |
|---|---|
| id | primary key, serial |
| garage_id | foreign_key, int |
| vehicle_type | enum |
| status | enum |
Users
| Field | Type |
|---|---|
| id | primary key, serial |
| varchar (SHA-256) | |
| first_name | varchar |
| last_name | varchar |
Vehicles
| Field | Type |
|---|---|
| id | primary key, serial |
| license | varchar |
| type | enum |

This section covers system designs of real world applications.
Each section here will include full details on the system. It's recommended, as part of your learning process, that you will NOT look at these full details and start by trying figuring them out by yourself. More specifically, for every system:
- Create a list of its functional requirements, features
- Create a list of its non functional requirements
- Design API spec
- Perform high-level design
- Perform detailed design
- Messaging with individuals and groups (send and receive)
- Sharing documents, images, videos
- User status - online, last seen, etc.
- Message status - delivered, read (and who read it)
- Encryption - encrypt end-to-end communication
- Scale
- Minimal Latency
- High Availability
- Consistency
- Durability
Messaging:
- Direct Chat Session
- Input: API key, user ID, user ID (recipient)
- Send Message
- Input: API key, session ID, message type, message
User account:
- Register account
- Input: API key, user data
- Validate account
- Input: API key, user ID, validation code
TODO
TODO
- Accounts
- Users have their account (they able to login or logout from it)
- Uploading videos
- Support uploading videos (and video thumbnail) by content creators/producers
- Only certain accounts can upload videos not everyone
- Set limit for uploads
- Video length (e.g. 5 hours)
- Size per hour of video (if 5 hours and 1GB per hour = 5GB)
- Thumbnail size (e.g. 50 MB)
- Streaming videos
- Users able to stream videos to different devices
- UI differ based on devices
- Buffering (over quality) (Note: A trade off)
- Store different quality versions of the same video
- Users able to stream videos to different devices
- Browsing videos
- Be able to tag videos (genre, date, ...)
- Allow users to search for videos (based on name, tag, ...)
- Reliability (Reliable video storage for storing uploaded videos and streaming them when needed)
- Scalability (be able to onboard users without hitting performance issues)
- High Availability (if one of the components fail, the system would still be usable)
How to perform system design? TODO(abregman): this section is not yet ready
- Define clearly the requirements - if requirements are not clear, make sure to clarify them
- Answer the question what is the projected traffic?
- Define which quality attributes are important for your system - scalability, efficiency, reliability, etc.
- TODO
If you are here because you have a system design interview, here are a couple of suggestions:
- Choose the simplest architecture that captures the requirements (functional requirements but also expected traffic for example) of the system. No need to complicate things :)
More specific suggestions based on the phase of the interview:
Note: You might want to ask yourself these questions also after you've done performing a system design
- Does it scale if I add more users?
- Is there a single point of failure in the design?
- Don't be shy about asking for clarifications on a given system design. Some system design are vague on purpose
- What are the requirements?
- How the system is used?
- How much users are expected to access the system?
- How often the users access the system?
- Where the users access the system from?
- Are there any constraints?
- Ask for clarifications if needed. Sometimes instructions or requirements are vague on purpose.
- List the required features of the system
- State problem you expect to encounter
- State the traffic you expect the system to handle
- At each decision made about the system design, state what are the cons and pros of such decision
The project banner, the icons used in "General" exercises section and the system design index, designed by Arie Bregman
If you would like to contribute to the project, please read the contribution guidelines