🔥 Official implementation of "Adversarial Supervision Makes Layout-to-Image Diffusion Models Thrive" (ICLR 2024)


Our environment is built on top of ControlNet:
conda env create -f environment.yaml
conda activate aldm
pip install mit-semseg # for segmentation network UperNet
Pretrained models ade20k_step9.ckpt and cityscapes_step9.ckpt can be downloaded from here. They should be stored in the checkpoint folder.
Datasets should be structured as follows to enable ALDM training. Dataset path should be adjusted accordingly in dataloader/cityscapes.py, dataloader/ade20k.py and dataloader/coco_stuff.py. Check convert_coco_stuff_id.ipynb for converting coco stuff labels.
Click to expand
datasets
├── cityscapes
│ ├── gtFine
│ ├── train
│ └── val
│ └── leftImg8bit
│ ├── train
│ └── val
├── ADE20K
│ ├── annotations
│ ├── train
│ └── val
│ └── images
│ ├── train
│ └── val
├── COCOStuff
│ ├── train_img
│ ├── val_img
│ ├── train_label
│ ├── val_label
│ ├── train_label_convert # New: after converting
│ └── val_label_convert # New: after converting
└── ...
We provide three ways for testing: (1) JupyterNotebook, (2) Gradio Demo, (3) Bash scripts.
-
JupyterNotebook: we provided one sample layout for quick test without requiring dataset setup.
-
Run the command after the dataset preparation.
gradio gradio_demo/gradio_seg2image_cityscapes.py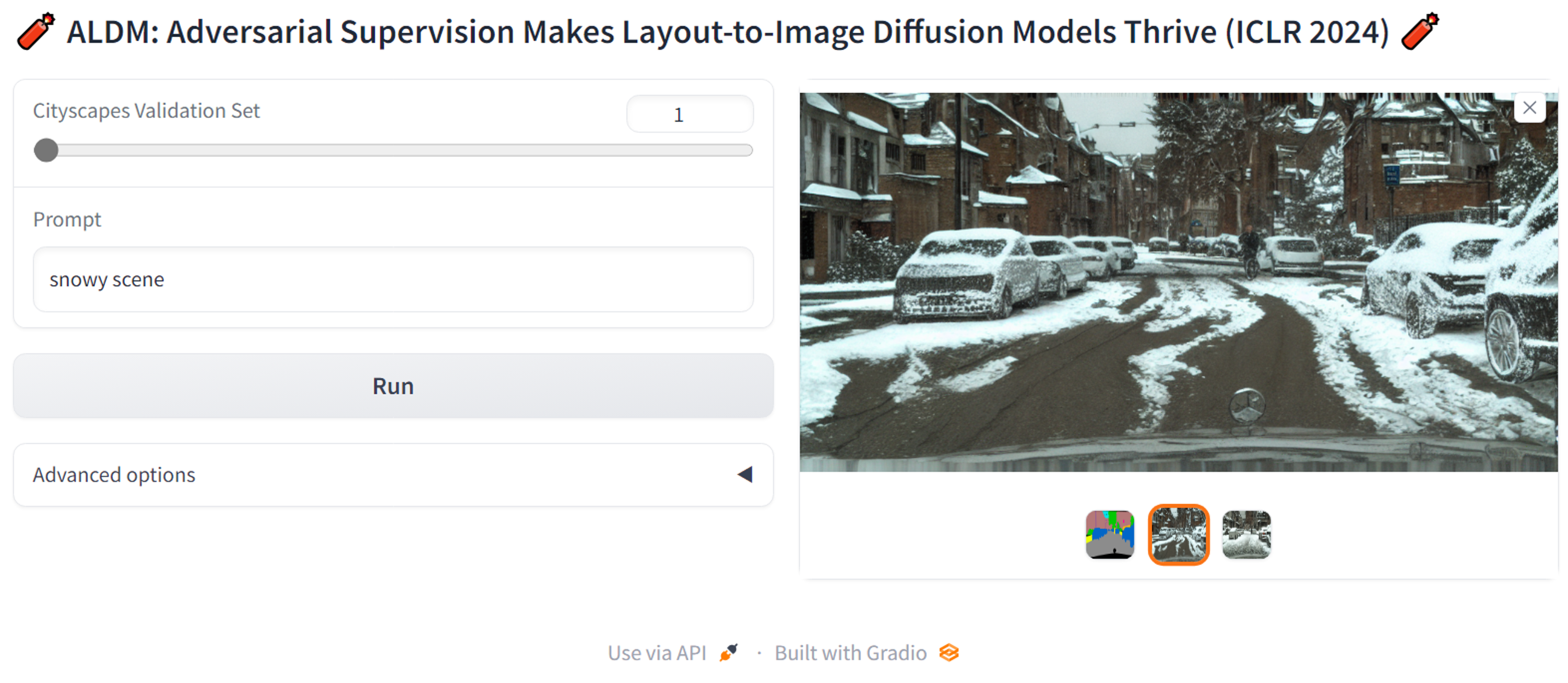

- Bash scripts: we provide some bash scripts to enable large scale generation for the whole dataset. The synthesized data can be further used for training downstream models, e.g., semantic segmentation networks.
Example training bash scripts for Cityscapes and ADE20K training can be found here: bash_script/train_cityscapes.sh, bash_script/train_ade20k.sh.
The main entry script is train_cldm_seg_pixel_multi_step.py, and YAML configuration files can be found under models folder, e.g., models/cldm_seg_cityscapes_multi_step_D.yaml.
To train on a new customized dataset, one may need to change the following places:
- Define a new dataset class and add it to the dataloader/__init__.py, cf. dataloader/cityscapes.py, where semantic classes need to be defined accordingly. The class language embedding, e.g., class_embeddings_cityscapes.pth can be generated using CLIP text encoder with a pre-defined prompt template, e.g., "A photo of {class_name}", which will produce embeddings of shape (N, 768), where N is the number semantic classes.
Note that, the class language embedding is not mandatory for the training. It doesn't impact the final performance, while we observe it can accelerate the training convergence, compared to the simple RGB-color coding.
- The captions of images, e.g., dataloader/ade20k_caption_train.json, can be obtained by vision-language models like BLIP and LLaVA.
- Adjust the segmenter-based discriminator, cf. cldm_seg/seg/ade_upernet101_20cls.yaml. Similar to the initialization in ControlNet here, one would need to manually match the semantic classes between the customized dataset and the pretrained segmenter. If there are new classes, where the pretrained segmenter wasn't trained on, one can simply initialize the weights randomly. Check out the example code snippet below, where a ADE20K pretrained UperNet is adjusted for Cityscapes.
Note that, essentially we update the generator and discriminator jointly during training, using a pretrained segmenter as initiliaztion can help to make the adversarial training more stable. So that's why the segmenter doesn't have to be trained on the same dataset.
Click to expand
### Cityscapes
try:
model = ADESegDiscriminator(segmenter_type='upernet101_20cls')
# model.load_pretrained_segmenter()
except:
pass
select_index = torch.tensor([6, 11, 1, 0, 32, 93, 136, 43, 72, 9, 2, 12, 150, 20, 83, 80, 38, 116, 128, 150]).long()
old_model = ADESegDiscriminator(segmenter_type='upernet101')
old_model.load_pretrained_segmenter()
target_dict = {}
for k, v in old_model.state_dict().items():
print(k, v.shape)
if 'conv_last.1.' in k:
new_v = torch.zeros((20,) + v.shape[1:]).to(v.device)
print(new_v.shape)
new_v = torch.index_select(v, dim=0, index=select_index)
new_v[12] = torch.randn_like(new_v[12])
target_dict[k] = new_v
else:
target_dict[k] = v
model.load_state_dict(target_dict, strict=True)
output_path = './pretrained/ade20k_semseg/upernet101/decoder_epoch_50_20cls.pth'
torch.save(model.state_dict(), output_path)If an error occured due to the segmenter, e.g., "got an unexpected keyword argument 'is_inference'", check this issue here.
The above might not be a complete list of items need to be adjusted. Please don't hesitate to open issues in case of doubts. I will update the instruction accordingly to make it clearer.
If you find our work useful, please star this repo and cite:
@inproceedings{li2024aldm,
title={Adversarial Supervision Makes Layout-to-Image Diffusion Models Thrive},
author={Li, Yumeng and Keuper, Margret and Zhang, Dan and Khoreva, Anna},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024}
}
This project is open-sourced under the AGPL-3.0 license. See the LICENSE file for details.
For a list of other open source components included in this project, see the file 3rd-party-licenses.txt.
This software is a research prototype, solely developed for and published as part of the publication cited above.
Please feel free to open an issue or contact personally if you have questions, need help, or need explanations. Don't hesitate to write an email to the following email address: liyumeng07@outlook.com