This workshop material uses Discover, a Code discovery service using TF-IDF (term frequency - inverse document frequency) estimator.
We aim to index code (content) from *.yaml and *.py files. User queries are then used to compared against the indexed code.
- Process Python files - process-python-modules.ipynb
- Python utility - py_utils.py
This notebook explains
- how to index content from
*.pyfiles, specifically all functions in each python file. - use the index to search keywords and show results (functions)
- Search YAML content - search-yaml.ipynb
This notebook uses existing code indexes saved on disk, loads them, and performs search against it.
- YAML and Python files are fetched from remote repositories to local disk.
- Tokenization
- YAML
- We tokenize YAML values under
urlsection (usinggramex.yamlas an example, this can be replaced with your specific format). - Each YAML file forms a document (row) in the matrix.
- We tokenize YAML values under
- Python
- We tokenize all functions. In each function, we identify its name, docstring, function and method calls.
- Each Python file forms a document (row) in the matrix.
- These matrices are then stored on disk for lookups.
- For a given user query, first we create a query vector then we determine the cosine similarity between that and the document vector (matrix).
- Only the relevant columns (words) are highlighted. The files are then identified (using the key from cosine similarity result and a key mapping). This isn't complete yet.
- We want to identify the relevant code snippet for a given user query. We repeat the step 4 for the query vector and against a new document vector (specific to the file identified).
- We now will have the relevant code snippet.
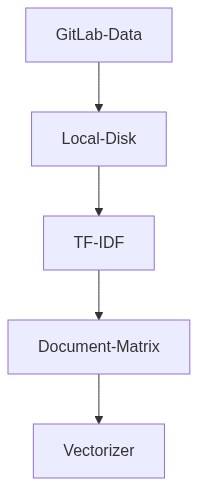
TF-IDF => term frequency - inverse document frequency
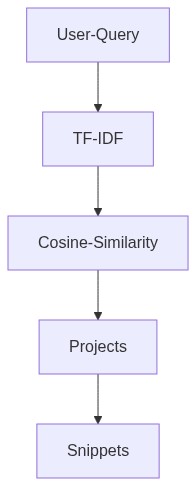
- Cosine Similarity is performed on the input vector (user query) and document matrix.
- The results are ordered in descending order (highest cosine similarity values first) for suggesting code snippets.
- Retrieval on source code: A neural code search, PDF
- TfidfVectorizer, scikit-learn