Discover, a code discovery service. This is a minimal alternative to sourcegraph.
Ideal for individuals and small teams.
add relevant python files and ipython notebooks.
- YAML and Python files are fetched from remote repositories to local disk.
- Tokenization
- YAML
- We tokenize YAML values under
urlsection (usinggramex.yamlas an example, this can be replaced with your specific format). - Each YAML file forms a document (row) in the matrix.
- We tokenize YAML values under
- Python
- We tokenize all functions. In each function, we identify its name, docstring, function and method calls.
- Each Python file forms a document (row) in the matrix.
- These document matrices are then stored on disk for lookups.
- For a given user query, first we create a query vector. We then determine the cosine similarity between the query vector and the document vector (matrix).
- Only the relevant columns (words) are highlighted. The files are then identified (using the key from cosine similarity result and a key mapping). This isn't complete yet.
- We want to identify the relevant code snippet for a given user query. We repeat the step 4 for the query vector and against a new document vector (specific to the file identified).
- We now will have the relevant code snippet.
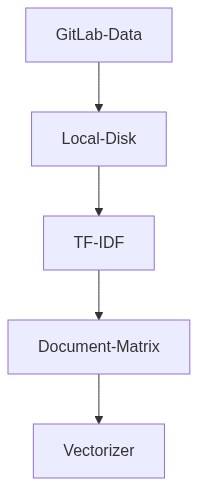
TF-IDF => term frequency - inverse document frequency
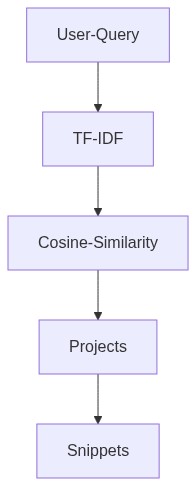
- Cosine Similarity is performed on the input vector (user query) and document matrix.
- The results are ordered in descending order (highest cosine similarity values first) for suggesting code snippets.
Below demo builds on the core discover service and adds an user interface layer to search keywords, add projects to be tracked periodically via schedulers.