
Dream Housing Finance company deals in all home loans. They have presence across all urban, semi urban and rural areas. Customer first apply for home loan, after that company validates the customer eligibility for loan.
Company wants to automate the loan eligibility process (real time) based on customer detail provided while filling online application form. These details are Gender, Marital Status, Education, Number of Dependents,Applicant Income, Co-Applicant Income, Loan Amount, Credit History and others.
Looking at the problem statement, it is silly that one would try to automate decision based on replication of pasts decisions instead of optimizing for business result - minimizing loan default or fraud rate. Well, but the objective here is to play around with Machine Learning and practice Data munging with Python.
The problem was hosted for Data hack Contest in Analytics Vidhya. The dataset can be downloaded from the challenge page or from the direct link to the same dataset train data and test data. Evaluation Metric is accuracy i.e. percentage of loan approval that we correctly predict.

- Almost 85% of applicants are not self-employed
- The vast majority of the loans had a term of 30 years.
- Lenders Look at more than just credit score.
- The model is trained on 10 variables.
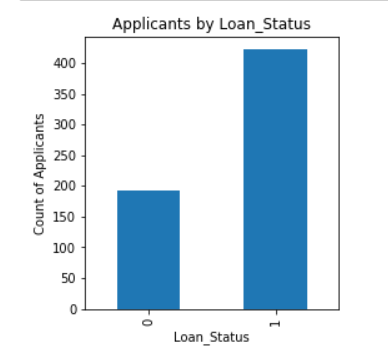
- The target variable Loan_Status(Yes/No) is Binary and hence a classification machine learning model is selected.
- Most of the loans are requested by applicants with low income, but not extremely low
- More Dependents send loan approval high.
- Loans for employed graduates with bad credit history still get approved !
The interesting problems an investigator might face with this dataset include:
- Practical and usable cross-validation strategy.
- Choosing evaluation metric for the dataset and the problem being solved.
- Handling missing data
- Imbalanced Class Distribution - This is a scenario where the number of observations belonging to one class is significantly lower than those belonging to the other classes.While trying to resolve specific business challenges with imbalanced data sets, the classifiers produced by standard machine learning algorithms might not give accurate results.

- Collect More Data
- Change the performance metric (like F1 Score, precision, recall)
- Try different algorithms
- Random Under-Sampling
cons:May lead to loss of information and the chosen sample may be a biased sample. - Random Over-Sampling
cons:Leads to overfitting the model.
https://www.analyticsvidhya.com/blog/2017/03/imbalanced-classification-problem/
This notebook uses several Python packages that come standard with the Anaconda Python distribution. The primary libraries that are used here are:
NumPy: Provides a fast numerical array structure and helper functions.Pandas: Provides a DataFrame structure to store data in memory and work with it easily and efficiently.Scikit-learn: The essential Machine Learning package in Python.Keras:A high-level neural networks API, written in Python and capable of running on top of TensorFlow, enabling fast experimentation.Matplotlib: Basic plotting library in Python; most other Python plotting libraries are built on top of it.
To make sure we have all of the packages needed, install them with conda:
conda install numpy pandas scikit-learn matplotlib keras

- Random Forest
- K-Nearest Neighbor Classifier
- Support Vector machine (SVM)
- Neural Network- Tensor Flow
