




A language translator is extensively utilized by the mute people for converting and giving shape to their thoughts. A system is in urgent need of recognizing and translating sign language.
Lack of efficient gesture detection system designed specifically for the differently abled, motivates us as a team to do something great in this field. The proposed work aims at converting such sign gestures into speech that can be understood by normal people. The entire model pipeline is developed by CNN architecture for the classification of 26 alphabets and one extra alphabet for null character. The proposed work has achieved an efficiency of 99.88% .

The dataset used can be downloaded here - Click to Download
This dataset consists of 17113 images belonging to 27 classes:
- Training Set: 12845 images

Train Data Statistics
- Test Set: 4368 images

Test Data Statistics
Our model is capable of predicting gestures from American sign language in real-time with high efficiency. These predicted alphabets are converted to form words and hence forms sentences. These sentences are converted into voice modules by incorporating Google Text to Speech(gTTS API).
The model is efficient, since we used a compact CNN-based architecture, it’s also computationally efficient and thus making it easier to deploy the model to embedded systems (Raspberry Pi, Google Coral, etc.). This system can therefore be used in real-time applications which aims at bridging the the gap in the process of communication between the Deaf and Dumb people with rest of the world.
- Gaussian filter is used as a pre-processing technique to make the image smooth and eliminate all the irrelevat noise.
- Intensity is analyzed and Non-Maximum suppression is implemented to remove false edges.
- For a better pre-processed image data, double thresholding is implemented to consider only the strong edges in the images.
- All the weak edges are finally removed and only the strong edges are consdered for the further phases.
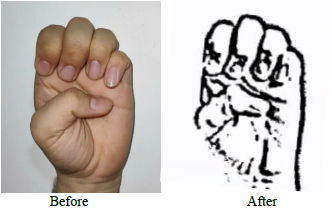
The above figure shows pre-processed image with extracted features which is sent to the model for classification.


All the dependencies and required libraries are included in the file requirements.txt See here
-
Start and fork the repository.
-
Clone the repo
$ git clone https://github.com/beingaryan/Sign-To-Speech-Conversion.git
- Change your directory to the cloned repo and create a Python virtual environment named 'test'
$ mkvirtualenv test
- Now, run the following command in your Terminal/Command Prompt to install the libraries required
$ pip3 install -r requirements.txt
- Open terminal. Go into the cloned project directory and type the following command:
$ python3 jupyter
-
To train the model, open the ASL_train file in jupyter notebook and run all the cells
-
To detect ASL Gestures in real-time video streams run the ASL_Real-Time.ipynb file.
- 'NOTE': You can directly use asl_classifier.h5 file trained by me for real-time predictions in Real-Time file.

- The model has been trained on a python based environment on Jupyter platform.
- The model is iterated for a total epoch of 20.
- The model has attained an accuracy of 99.88 % accuracy on the Validation set.
- The prescribed model has been evaluated on Test set where it has attained an accuracy of 99.85% with loss of 0.60 %.



Feel free to mail me for any doubts/query :email: aryan.gupta18@vit.edu
Feel free to file a new issue with a respective title and description on the the Sign-Language-Detection repository. If you already found a solution to your problem, I would love to review your pull request!
Made with ❤️ by Aryan Gupta
- https://www.pyimagesearch.com/
- https://opencv.org/
- Efthimiou, Eleni & Fotinea, Stavroula-Evita & Vogler, Christian & Hanke, Thomas & Glauert, John & Bowden, Richard & Braffort, Annelies & Collet, Christophe & Maragos, Petros & Segouat, Jérémie. (2009).
- Sign Language Recognition, Generation, and Modelling: A Research Effort with Applications in Deaf Communication. 21-30. 10.1007/978-3-642-02707-9_3.
- Pramada, Sawant & Vaidya, Archana. (2013). Intelligent Sign Language Recognition Using Image Processing. IOSR Journal of Engineering. 03. 45-51. 10.9790/3021-03224551.
You can find our Code of Conduct here.
MIT © Aryan Gupta