![]()
![]()


This SageMaker JumpStart Industry solution provides a template for a text-enhanced credit rating model. It shows how to take a model based on numeric features (in this case, Altman's famous 5 financial ratios) combined with texts from SEC filings so as to achieve an improvement in the prediction of credit ratings. You are not restricted to the 5 Altman ratios; you can add more variables as needed or completely change the variables. The main objective of this solution notebook is to show how SageMaker JumpStart Industry can help process NLP scoring of SEC filings text and use the Altman's Z-score to compute the Altman's 5 financial ratios to enhance features, train a model using the enhanced features to achieve a best-in-class model, deploy the model to a SageMaker endpoint for production, and receive improved predictions in real time.
This solution does not use Altman's Z-score directly. Instead, it shows how the features (financial ratios from the income statement and balance sheet) that are used to produce Altman's Z-score model may be used to predict credit ratings. This credit prediction model is enhanced by adding text from SEC filings: specifically, the Management Discussion and Analysis (MDnA) section of the 10-K/10-Q filings. We prepared a synthetic dataset for the financials of companies and merged these synthetic variables with actual text from SEC filings. We note here that the credit ratings (labels) are also generated synthetically as well, and are not the true credit rating of the companies in the SEC filings.
The main goal of this exemplar solution is to showcase how hitherto tabular data credit rating models may be enhanced with long text to improve the model's performance in terms of accuracy and other metrics. Since this solution is based on Altman's Z-score features, it is useful to offer some background on Altman's famous model.
The Altman's Z-score is based on a well-known bankruptcy prediction approach, from the original paper by Ed Altman (1968).
Reference: Altman, Edward. (September 1968). Financial Ratios, Discriminant Analysis and the Prediction of Corporate Bankruptcy, Journal of Finance, v23(4): 189–209. doi:10.1111/j.1540-6261.1968.tb00843.x
The Altman's Z-score uses Management Discussion and Analysis (MDNA) text data from SEC 10-K/Q filings, SIC code (industry_code), and 8 financial variables from a company's financial statement, such as balance sheet tables and income statements. The 8 financial features are as follows:
- Current assets
- Current liabilities
- Total liabilities
- EBIT (earnings before interest and tax)
- Total assets
- Net sales
- Retained earnings
- Market value of equity
The true label is the Rating column.
The following snapshot shows an example of the input data:

These 8 input features translate into the 5 financial ratios that are used for the Altman Z-score:
- A: EBIT / total assets
- B: Net sales / total assets
- C: Market value of equity / total liabilities
- D: Working capital / total assets
- E: Retained earnings / total assets
In this example, these ratios are used to fit multi-category classification using a cross-section of financial data of companies. Altman fitted the model using linear discriminant analysis (LDA) to a binary classification problem (defaulted vs non-defaulted companies), possibly the earliest use of machine learning in finance. The linear discriminant function is as follows:
Z-score (Z) = 3.3 A + 0.99 B + 0.6 C + 1.2 D + 1.4 E
These translate into company credit quality ranges, which also correlate with ratings:
- Z > 3.0: safe
- 2.7 < Z < 2.99: caution
- 1.8 < Z < 2.7: bankruptcy possible in 2 years
- Z < 1.8: high chance of bankruptcy
Reference: Slides from The Use of Credit Scoring Models and the Importance of a Credit Culture by Dr. Edward I. Altman at Stern School of BusinessNew York University
To learn how to prepare your data, run the example solution notebook (corporate-credit-rating.ipynb) with the provided synthetic dataset. After you complete exploring the solution notebook, you can replace the input CSV file and the dataframe with your own multimodal (TabText) dataset.
NOTE: The solution notebook is for demonstrative purposes only. It is not financial advice and should not be relied on as financial or investment advice.
NOTE: The dataset we provide through the solution notebook is synthetic. The text is from real SEC filings, but the financial variables and labels are synthetically generated. The steps for generating the synthetic data is described in the Solution Details section; it walks you through how the synthetic data and labels are aligned to make sure that the example dataset can be meaningful for training an ML model.
The outputs include:
- A trained multimodal model
- A SageMaker endpoint that can predict the future (multi-variate) values given an input multimodal data
In this example, we can predict the credit rating for certain companies. But by changing the labels, you can predict many other credit outcomes such as whether a company will change from investment grade to below investment grade, the credit spread for a company, or the default of a company.
We use the AWS AutoGluon Tabular model, which is a state-of-the-art machine learning model, to deal with cumbersome issues like data cleaning, feature engineering, hyperparameter optimization, and model selection.
You can estimate the cost for running the SageMaker JumpStart Industry solution notebooks using the lookup table in the Amazon SageMaker Pricing Calculator section of the Amazon SageMaker Pricing page and the actual duration of use for training jobs, processing jobs, and real-time inferences.
To avoid unexpected incurring charges, make sure you check the Clean up section to delete endpoints and resources that are created or used while running the solution notebook.
For more information about cleaning up resources, see Clean Up in the Amazon SageMaker Developer Guide.
We created a synthetic dataset that combines texts from randomly selected SEC filings (MDNA), the industrial classification codes (industry_code), and simulated tabular data with 8 financial variables that are essential to calculate the Altman's Z-score. We created the synthetic dataset using the following procedure:
- Extract the Management Discussion and Analysis (MDNA) section of the 10-K/Q SEC filings from a random sample of 3286 firms.
- Run an NLP-scoring processing job to score the MDNA texts for 5 positive attributes (positivity, sentiment, polarity, safety, certainty) and 5 negative attributes (negativity, litigiousness, fraud, risk, uncertainty). To rank the firms based on the 10 NLP score attributes, add the values of the positive 5 attributes and subtract the values of the negative 5 attributes; the net values are called the NLP score rank hereafter.
- Add a column for the category of the firms (industry_code). This feature is categorical and might be useful given that firms within the same industry code are likely to be impacted by the same factors.
- Simulate financials for all 3286 firms using the official government websites to get U.S. balance sheet tables, income statements, and market statistics. The financials are normalized so that the Total Assets variable is 100 and the other financial variables are scaled accordingly. The 8 financial variables are examined for consistency so that, for example, the simulated Current Liabilities do not exceed the simulated Total Liabilities; in cases where the simulated Current Liabilities exceed the simulated Total Liabilities, the simulated financials are discarded and regenerated until they meet the consistency criteria. The referenced statistics are from the following resources: (i) Balance Sheet Tables for U.S. Corporations in Manufacturing Industry, Quarterly, Not Seasonally Adjusted; (ii) Income Statements for U.S. Corporations in Manufacturing Industry, Quarterly, Not Seasonally Adjusted; (iii)Price and Value to Book Ratio by Sector (US); and (iv) The Use of Credit Scoring Models and the Importance of a Credit Culture.
- Convert the 8 financial features into the 5 financial ratios to calculate the Altman Z-scores.
- Compute the Z-scores for each firm.
- To add synthetic labels, assign the Rating values (AAA, AA, A, BBB, BB, B, and CCC) to the firms based on their Z-scores.
- Finally, concatenate the MDNA texts from the step 2 and the simulated financials from the step 8. Those firms with the financial feature values that return high (low) Z-scores are concatenated to the MDNA texts with high (low) NLP score ranks. This way, we can obtain a consolidated multimodal (text, categorical, and numerical) dataset.
- The Z-scores and NLP scores are then discarded and not included in the synthetic data.
The notebook trains an ML model using the SageMaker MXNet estimator on the synthetic corporate credit rating data. Finally, we deploy an endpoint for corporate credit rating prediction.
The following diagram shows the architecture for an end-to-end training and deployment process.
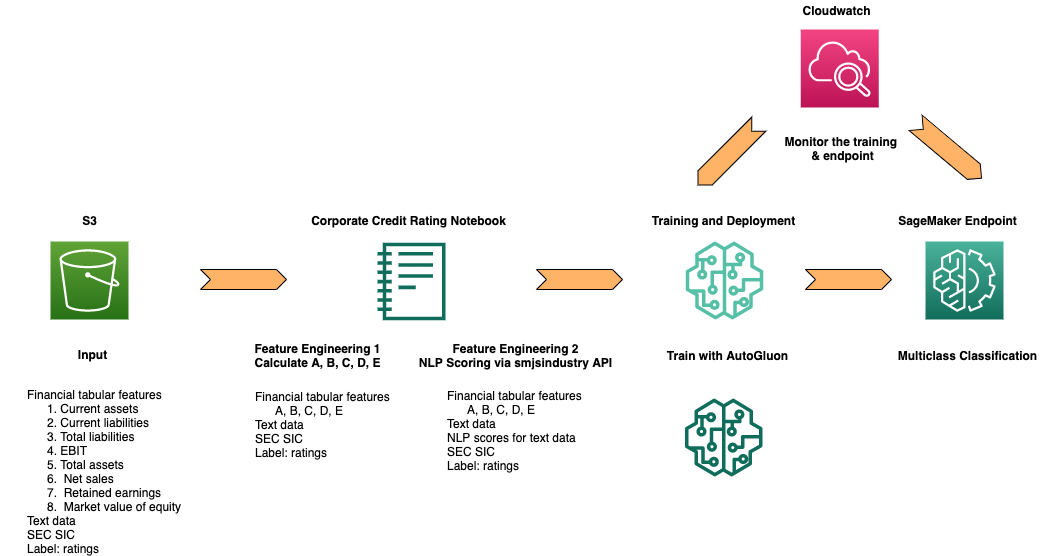
- The synthetic data and dependencies are located in an Amazon S3 bucket.
- The provided SageMaker JumpStart Industry solution notebook (
corporate-credit-rating.ipynb) downloads the synthetic data for training. - Feature engineering steps include converting 8 financial properties into 5 financial ratios and calculating NLP scores via the SageMaker JumpStart Python SDK.
- Training an MXNet AutoGluon model uses the previous preprocessed step and evaluating its results using Amazon SageMaker. If desired, one can deploy the trained model and create a SageMaker endpoint.
- A SageMaker endpoint is created using the model artifact from the previous step. The endpoint is an HTTPS endpoint and is capable of producing predictions.
- Monitor the training job and the deployed model via Amazon CloudWatch.
The following diagram shows the architecture for model inference.
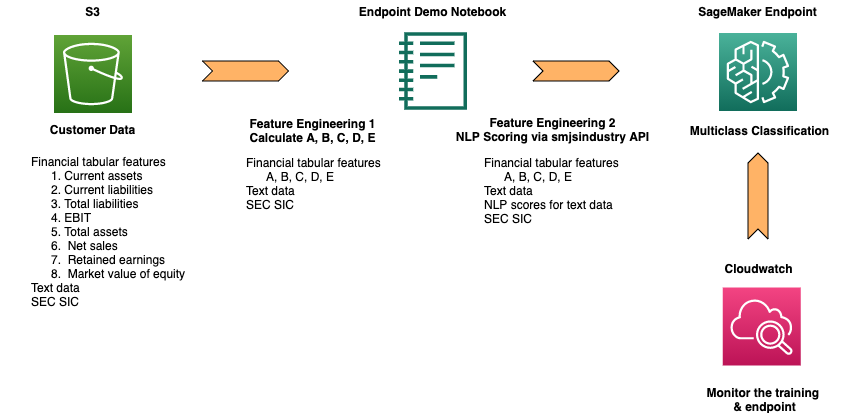
- Upload new input data to an Amazon S3 bucket.
- From the SageMaker notebook, perform the feature engineering steps.
- Send the requests to the SageMaker endpoint.
After you are done using the solution notebook, make sure to delete all AWS resources that you don’t need to keep running. You can use AWS CloudFormation to automatically delete all standard resources that the solution and the notebook created. Go to the AWS CloudFormation console and delete the parent stack. Deleting the parent stack will automatically delete the nested stacks.
Caution: You need to manually delete any other resources that you may have created while running the notebook, such as Amazon S3 buckets to the solution's default bucket, Amazon SageMaker endpoints using custom names, and Amazon ECR repositories.
For more information about cleaning up resources, see Clean Up in the Amazon SageMaker Developer Guide.
Q. Who can use this notebook?
Any users that wish to enhance their credit rating models with text can use this notebook. There is a wide range of possible users:
- Firms that trade corporate bonds who wish to predict improvements or deterioration in the credit quality of a firm. Examples are bond funds, corporate bond trading desks, lenders to corporations, and hedge funds.
- Firms that model credit risk, such as traders in credit default swaps, pricing tool providers like Markit, and risk managers.
- Rating agencies who may use this template to enhance their tabular-only ML models with texts.
The model is widely used by a range of users and is therefore taught as part of required coursework by the Corporate Finance Institute (CFI). Altman himself offered a 50-year retrospective on the model in parts 1, 2, and 3, including its wide use and misuse. Watch him on video and read this article. For a critique and improvement on the model, see this article by Seeking Alpha, a well-known investor community. The Z-score Plus model is even available as an app on mobile devices. Therefore, think of this notebook as a well-established starting point for the use of ML for credit scoring and rating prediction.
Q. How do I use this notebook?
To begin with, run the endpoint demo notebook (endpoint-demo.ipynb) to gain an understanding of how simple this solution is to use. This jumpstarts your modification of this notebook (corporate-credit-rating.ipynb) for your own model. The modification entails the following steps:
- Bring in your tabular data, with one row for each firm's financial data. This may be the same as that in the notebook (i.e., Altman's variables) or any others you work with for credit modeling. There is no restriction on the number of variables.
- Bring in your text data. The demo notebook uses the SEC 10-K/Q filings (tickers have been masked): specifically, the Management Discussion and Analysis section of the filings. If you want to download the latest filings and use them, please see our JumpStart notebook for doing this in a single API call on SageMaker, titled Create a TabText Dataset of SEC filings with a Single API Call. This not only downloads the text you may want, but also allows you to enhance the data with NLP scores, summaries, and other elements as additional columns in the dataframe so that you can use several features of the text such as readability, positivity, risk, litigiousness, and sentiment.
- Join the data from steps 1 and 2.
- Reuse the notebook (
corporate-credit-rating.ipynb) with this dataset with minimal changes required in thetrain.pyandinference.py. AutoML with our AutoGluon package does the rest in a few lines of code as shown in the training and inference scripts.
- Amazon SageMaker Getting Started
- Amazon SageMaker Developer Guide
- Amazon SageMaker Python SDK Documentation
- AWS CloudFormation User Guide
This project is licensed under the Apache-2.0 License.
- The SageMaker JumpStart Industry solution is for demonstrative purposes only. It is not financial advice and should not be relied on as financial or investment advice. The associated notebooks, including the trained model, use synthetic data, and are not intended for production.
- The SageMaker JumpStart Industry solution notebooks use data obtained from the SEC EDGAR database. You are responsible for complying with EDGAR's access terms and conditions located in the Accessing EDGAR Data page.
See CONTRIBUTING for more information.