Detailed explanation of this POC is provided in this blog
This comprehensive guide provides step-by-step instructions for configuring and running Llama2 on a MacBook. While tailored for macOS, the instructions are adaptable for Windows machines as well. The following is the sysem specification that I used for building this project, I do believe a lower configuration will work just fine.
System Specifications:
- Device: MacBook Pro
- Processor: 2.6 GHz 6-Core Intel Core i7
- RAM: 32 GB 2667 MHz DDR4
Follow the outlined steps to seamlessly set up Llama2 on your local environment. You may be able to follow the instruction for both Mac or Windows machine.
- Install Python if it is not already installed. You need Python version 3.8 or higher. I am currently running version 3.11.6
brew install python
- upgrade pip3 to the latest version (pip3 enables the installation and management of third party software packages that are used in this project)
python3 -m pip install --upgrade pip
- Download this code repository (install git if it is not already setup, You can also downlod the zip file directly from the main page under code option as an alternate)
brew install git
git clone https://github.com/AhilanPonnusamy/LLM-and-AppModernization.git
- Move to LLM-and-AppModernization folder
cd LLM-and-AppModernization
- Install all required packages from requirements.txt file
If you run into issues (eg you might run a real O/S (Linux) or have conflicting dependencies which lead to errors) you can try the following:
- Remove all version locks in the requirements.txt
- Create a virtual python environment (
pip install virtualenv) and start again as per above frompython3 -m pip install --upgrade pip - Check if your build tools like C++ and cmake are installed. If not install it via
dnf install g++ cmake
python3 -m pip install -r requirements.txt
-
Create a new folder named 'models'
-
From the 'models' folder download 'llama-2-7b-chat.Q5_K_M.gguf.bin' file from https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/tree/main. Please add .bin as file extension to make sure that the model is properly loaded by the application.
-
Move back to LLM-and-AppModernization folder
-
Start the backend business services
python3 restservice.py
- Open a new terminal window and from the LLM-and-AppModernization folder start the LLM application. It will open the UI in a new browser tab.
streamlit run app.py
Note
During startup, you may face random errors sometime about llm not loaded or broken chain etc. Restart the app in such case which will fix the problem. You may also get light theme for UI as default, you can change in under setting in the top right corner.

Now, that the application and the backend services are up and running, it is now time to take it for a spin
-
With Use RAG option unselected, submit the following question can you transfer $50 to joseph?. Once submitted, you will see some activity in streamlit console and in about 45 seconds a generic LLM response is dislayed in the UI as shown below.

-
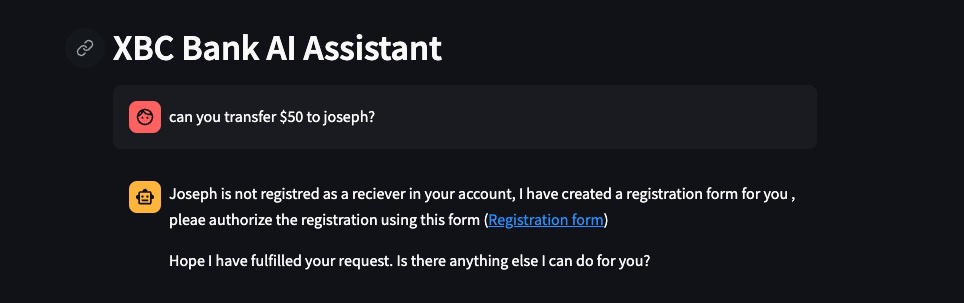
With Use RAG option selected, submit the same question can you transfer $50 to joseph? you will now see a more context aware message as shown below


Warning
You may periodically face the following context window size error. Clik on the clear conversation button on the left side to flush the data and try again.
- you can try the following prompts to try with Use RAG option selected
- can you transfer $50 to ram?
- can you transfer $580 to john?
- can you transfer $100 to peter?
- can you add joseph to my account?
- can you add allan to my account?
- can you remove john from my account?
- can you remove mark from my account?
Have fun!!!!!