- Es una pieza de software que hace de intermediaro entre el hardware y el software.
- Su función más importante es administrar los recursos.
- Su segunda función más importante es abstraer el hardware.
Programas que son parte del sistema operativo y manejan los detalles de bajo nivel relacionados con la operación de los distintos dispositivos.
Es el SO propiamente dicho; su parte central. Se encarga de las tareas fundamentales y contiene diversos subsistemas.
Un programa más, que muchas veces es ejecutado automáticamente cuando comienza el SO, que le permite al usuario interactuar con el SO. Puede ser gráfico o de línea de comandos.
Ejemplos en Unix: sh, bash, zsh, csh, ksh, etc.
Un programa en ejecución más su espacio de memoria asociado y otros atributos.
Secuencia de bits con un nombre y una serie de atributos que indican permisos, etc.
Colección de archivos y directorios que contiene un nombre y se organiza jerárquicamente.
Una abstracción de un dispositivo físico bajo la forma, en general, de un archivo, de manera tal que se pueda abrir, leer, escribir, etc.
Es la forma de organizar los datos en el disco para gestionar su acceso, permisos, etc.
Son directorios donde el propio SO guarda archivos que necesita para su funcionamiento.
Ejemplos en Unix: /boot, /dev, etc
Ejemplo en Windows: C:\Windows\system32
Son archivos que viven en los directorios del sistema. Si bien no forman parte del kernel, suelen llevar a cabo tareas muy importantes o proveer las utilidades básicas del sistema.
Ejemplos en Unix:
/usr/sbin/syslogd: es el encargado de guardar los eventos del sistema en un archivo./bin/sh: el Bourne Shell./usr/bin/who: indica qué usuarios están sesionados en el sistema.
Es un archivo más, excepto porque el sistema operativo saca de allí información que necesita para funcionar.
Ejemplo en Unix: /etc/passwd
Ejemplo en Windows: C:\Windows\system32\user.dat
La representación, dentro del propio SO, de las personas o entidades que pueden usarlo. Sirve principalmente como una forma de aislar información entre si y de establecer limitaciones.
Una colección de usuarios.
- Un proceso es un programa que se está ejecutando en un SO.
- A cada proceso se le asigna un identificador numérico único, el
pidoprocess id. - Un proceso está compuesto por:
- El área de texto, que es el código de máquina del programa.
- El área de datos, que es donde se almacena el heap.
- El stack del proceso.
- Un proceso puede:
- Terminar.
- Lanzar un proceso hijo (
system(),fork(),exec()). - Ejecutar en la CPU.
- Hacer una
system call. - Realizar entrada/salida a los dispositivos (E/S).
- Todos los procesos están organizados jerárquicamente, como un árbol.
- Cuando el SO comienza, lanza un proceso que se suele llamar
rootoinit.
- Es una parte fundamental del kernel.
- Su función es decidir a qué proceso le corresponde ejecutar en cada momento.
- Hay varias formas de decidir esto.
- Pocas cosas tienen mayor impacto en el rendimiento de un SO que su política de scheduling.
- Para cambiar el programa que se ejecuta en la CPU, se debe hacer un context switch:
- Guardar los registros.
- Guardar el IP.
- Si se trata de un programa nuevo, cargarlo en memoria.
- Cargar los registros del nuevo.
- Poner el valor del IP del nuevo.
- El IP y los demás registros se guardan en una estructura de datos llamada PCB (Process Control Block).
- El tiempo utilizado en los context switches es tiempo muerto. No se está haciendo nada productivo.
El SO mantiene una tabla llamada Tabla de Procesos, con una entrada por cada proceso, llamada Process Control Block (PCB). Esta entrada contiene:
- Process ID.
- Program Counter y Stack pointer.
- Registros de la CPU.
- Heap y pila.
- File descriptors.
- Direcciones de memoria.
- Permisos.
- Usuarios.
- Etc.
- Los File Descriptors son índices de una tabla que indican los archivos abiertos por el proceso.
- Cada proceso UNIX viene con su propia tabla (en su PCB) al momento de ser creado.
- Los File Descriptors son usados por el Kernel para referenciar a los archivos abiertos que tiene cada proceso. Cada entrada de la tabla apunta a un archivo.

- El proceso le indica al SO que ya puede liberar todos sus recursos.
- Además, indica su status de terminación (usualmente, un código numérico).
- Este código de status le es reportado al proceso padre.
Cada proceso puede lanzar procesos hijos:
fork()es una llamada al SO que crea un proceso exactamente igual al actual.- El resultado es el
piddel proceso hijo. - El padre puede decidir suspenderse hasta que termine el hijo, llamando a
wait(). - Cuando el hijo termina, el padre obtiene el código de status del hijo.
- Por ende:
fork()+wait()=system(). - El proceso hijo puede hacer lo mismo que el padre o algo distinto. En ese caso puede reemplazar su código binario por otro (
exec()).

Cuando lanzamos un programa desde el shell, el shell hace un fork(), y el hijo hace un exec().
- Un proceso creado usando fork() comienza con sus páginas de memoria apuntando a las mismas que el padre.
- Recién cuando el padre o el hijo escriben en memoria, se hace finalmente la copia.
- Esto se llama Copy-on-Write.
- Un proceso en ejecución se dedica a:
- Hacer operaciones entre registros y direcciones de memoria.
- E/S.
- Llamadas al sistema.
- Importante: sólo un proceso a la vez puede estar en la CPU.
- Problema: cuánto tiempo lo dejamos ejecutar? Tenemos dos opciones:
- Hasta que termina: es lo mejor para el proceso, pero no para el sistema en su conjunto. Además, podría no terminar.
- Un "ratito". Ese "ratito" se llama quantum.
- Los SO modernos hacen preemption: cuando se acaba el quantum, le toca el turno al siguiente proceso.
- El scheduler es quien decide cómo y a quién le toca.
- Ejemplos:
fork(),exec(),write(), etc. - En todas ellas se debe llamar al kernel.
- A diferencia de una subrutina común y corriente, las llamadas al sistema requieren cambiar el nivel de privilegio, un cambio de contexto, a veces una interrupción, etc.
- La E/S es muy lenta.
- Problema: un proceso necesita saber cuándo una operación de E/S termina. Algunos métodos son:
- Busy waiting: El proceso no libera la CPU. Un único proceso en ejecución a la vez.
- Polling: El proceso libera la CPU, pero todavía recibe un quantum que desperdicia hasta que la E/S esté terminada.
- Interrupciones: Esto permite la multiprogramación.
- El SO no le otorga más quantums al proceso hasta que su E/S esté lista.
- El HW comunica que la E/S terminó mediante una interrupción.
- La interrupción es atendida por el SO, que en ese momento "despierta al proceso".
- Multiprocesador: un equipo con más de un procesador.
- Multiprogramación: la capacidad de un SO de tener varios procesos en ejecución.
- Multiprocesamiento: tipo de procesamiento que sucede en los multiprocesadores.
- Multitarea: forma especial de la multiprogramación, donde la conmutación entre procesos se hace de manera tan rápido que da la sensación de que varios programas están corriendo en simultáneo.
- Multithread: son procesos en los cuales hay varios "mini procesos" corriendo en paralelo (de manera real o ficticia como en la multiprogramación).

- Listo/Ready: el proceso no está bloqueado, pero no tiene CPU disponible como para correr.
- Corriendo/Running: está usando la CPU.
- Bloqueado/Esperando/Waiting: no puede correr hasta que algo externo suceda (típicamente E/S lista).
La carga del sistema es igual a la cantidad de procesos en estado Listo
- Es responsabilidad del scheduler elegir entre los procesos listos cuál es el próximo a correr.
- Cuál elegir está determinado por la política de scheduling.
- El scheduler tiene una lista de PCBs que se llama tabla de procesos, donde además se guarda la prioridad de los procesos, sus estados, y aquellos recursos por los que están esperando.
- InterProcess Communication.
- Técnicas:
- Archivos compartidos.
- Señales.
- Sockets.
- Pipes.
- Memoria compartida.
- Pasaje de mensajes.
- El emisor no termina de enviar hasta que el receptor no recibe.
- Si el mensaje se envió sin error suele significar que también se recibió sin error.
- En general involucra bloqueo del emisor.
- El emisor envía algo que el receptor va a recibir en algún otro momento.
- Requiere algún mecanismo adicional para saber si el mensaje llegó.
- Libera al emisor para realizar otras tareas. No suele haber bloqueo, aunque puede haber un poco.
- Maximizar eficiencia: tratar de que la CPU esté el mayor tiempo haciendo cosas útiles.
- Maximizar rendimiento (throughput): el throughput es la cantidad de trabajos procesados por unidad de tiempo.
- Minimizar latencia: la latencia es el tiempo entre que un proceso se se encola en el scheduler hasta que se pasa a ejecutarse por primera vez.
- Minimizar la carga del sistema: la carga del sistema es la cantidad de procesos que están en estado ready, es decir, esperando CPU.
- Evitar la inhibición (starvation): que todos los procesos puedan acceder a la CPU y eventualmente terminen.
Es imposible cumplir al 100% todos los objetivos. Los algoritmos de scheduling tratan de ser muy buenos en algún objetivo, tratando de impactar lo menos posible en el resto.
Los procesos que van llegan se encolan al final y se van ejecutando en orden hasta que terminan.
- No tiene inhibición: todos lo procesos eventualmente van a ser atendidos.
- Usa bien la CPU: tiene un sólo cambio de contexto por proceso, así que la mayoría del tiempo está usando el CPU.
- Es simple de implementar.
- No tiene en cuenta el throughput ni la latencia. Si un proceso largo entra antes que un proceso muy corto, el corto tiene que esperar a que el largo termine.
- No tiene en cuenta las necesidades de interactividad de cada proceso. Reparte nivelando para abajo.
A cada proceso se le asigna una unidad de tiempo (quantum).
- Reparte mejor la CPU.
- El throughput tiene un mejor comportamiento, así como también la latencia.
- Seguimos nivelando para abajo. No tenemos en cuenta el nivel de interactividad de cada proceso.
- El valor del quantum es dificil de determinar:
- Un quantum chico genera muchos cambios de contexto innecesarios.
- Un quantum grande hace que el algoritmo tienda a ser igual que FCFS.
A cada proceso se le asigna una prioridad. El proceso con la prioridad más alta entra primero. Si hay dos procesos con la misma prioridad, en general, se aplica Round Robin. Las prioridades para un proceso pueden ser estáticas o dinámicas.
- Tiene en cuenta las necesidades de cada proceso. El concepto de "justicia" es un poco más elaborado que en Round Robin puro.
- Las prioridades de cada proceso son dificiles de determinar.
- Puede producirse inhibición si la política de prioridades es defectuosa.
El proceso más corto tiene la prioridad más alta en la cola de procesos listos. Es un algoritmo ideal.
- Buen uso de CPU.
- Tiene en cuenta la interactividad.
- Es el que mejor maximiza la latencia relativa y el thopughput.
- Es muy dificil de implementar. Es muy dificil saber a priori cuánto tiempo de CPU va a necesitar un proceso. En la práctica, se usa una aproximación para saber cuánto va a durar la ejecución. Por ejemplo, viendo cuánto duró el proceso en ejecuciones anteriores.
Los bugs que surgen cuando dos o más procesos acceden al mismo recurso compartido y el resultado final varia según quién termina primero.
Método para asegurar que un sólo proceso a la vez tiene que acceder a un recurso compartido
Pedazo de código protegido con una exclusión mutua.
- Sólo hay un proceso a la vez en una región crítica.
- Todo proceso que está esperando entrar a la región crítica eventualmente va a entrar.
- Ningún proceso fuera de la región crítica puede bloquear otro.
Consiste en deshabilitar las interrupciones antes entrar en acción crítica y volver activarlas al salir de la misma. El problema es que si, por alguna razón, las interrupciones no se vuelven a habilitar, el sistema no podrá continuar ejecutándose. Además, elimina temporalmente la multiprogramación.
Solución por software que consiste en tener una variable compartida que está en false cuando no hay ningún proceso en su región crítica y true cuando sí lo hay. Éste método tiene el mismo problema que el anterior, ya que sin dos procesos leen el false a la vez, ambos fijarán el candado en true y entrarán en su región crítica.
Es cuando un lock hace busy waiting para ver si puede entrar a la región crítica.
Es una instrucción del hardware para crear locks atómicos.
- Cuando la variable es
false, cualquier proceso lo puede fijar entruemediante el uso de la instrucción TAS. - Cuando termina, el proceso establece el candado en
falsemediante una instrucción de asignación ordinaria. Hace busy waiting, es decir, consume muchísima CPU mientras espera a que se libere el candado.
Ejemplo:
volatile bool lock = false;
void critical() {
while (test_and_set(&lock) == true);
critical section // only one process can be in this section at a time
lock = false // release lock when finished with the critical section
}-
Es un unsigned int con dos operaciones:
wait/down/dec/Pysignal/up/inc/V. -
Ambas operaciones son atómicas, es decir, que si dos threads o procesos realizan una operación sobre el semáforo, estas no se pueden interrumpir entre ellas.
-
wait: intenta decrementar el valor del semáforo. si el valor es mayor que 0, se decrementa existosamente y continúa la ejecución. Si el valor es 0, no decrementa, y pone el proceso a dormir. Al poner el proceso a dormir, no tenemos más busy waiting, que era el problema principal de TAS!!
-
signal: incrementa el valor del semáforo y retorna.
-
-
Se lo puede inicializar en cualquier valor.


Hoy en día los lenguajes de alto nivel proveen distintas alternativas para implementar secciones críticas:
- bool atómicos.
- ints atómicos.
- colas atómicas.
private bool reg;
atomic bool get() { return reg; }
atomic void set(bool b) { reg = b; }
atomic bool getAndSet(bool b) {
bool m = reg;
reg = b;
return m;
}
atomic bool testAndSet() {
return getAndSet (true);
}- En base a bools atómicos con
testAndSetpuedo construir un mutex llamado TASLock o spin lock.
atomic <bool > reg;
void create() { reg.set(false); }
void lock() { while (reg.testAndSet()) {} }
void unlock() { reg.set(false); }Cuidado, lock() no es atómico.
Ejemplo de uso:
TASLock mtx;
int donar(int donacion) {
int res;
// Inicio de la sección crítica.
mtx.lock();
fondo += donacion;
mtx.unlock();
// Fin de la sección crítica.
// Inicio de otra sección crítica.
mtx.lock();
res = ticket; ticket++;
mtx.unlock();
// Fin de la sección crítica.
return res;
}- No hay que olvidarse de hacer
unlock(). - Produce busy waiting.
- Overhead menor que usando semáforos.
- Idea: probar antes de mandarse con el TAS().
- También llamada local spinning.
- Es más eficiente.
void create() { mtx.set(false); }
void lock() {
while(true) {
while(mtx.get()) {}
if (!mtx.testAndSet()) return;
}
}
void unlock() { mutex .set(false); }Si un proceso A se queda esperando que suceda algo que sólo B puede provocar, pero a su vez B está esperando algo de A, se produce un bloqueo llamado deadlock.
- Esto puede pasar si uso semáforos y me olvido de poner un
signalo si invierto el orden.
Un conjunto de procesos está en livelock si estos continuamente cambian su estado en respuesta a los cambios de estado de los otros.
Ejemplo: queda poco espacio en disco. Proceso A detecta la situación y notifica a proceso B (log del sistema). Proceso B registra el evento en disco, disminuyendo el espacio libre, lo que hace que A detecte la situación y ...
- El Administrador de Memoria es un componente más del SO. Se encarga de:
- Asegurar la disponibilidad de la memoria para los proceso.
- Asignar y liberar memoria.
- Organizar la memoria disponible.
- Asegurar la protección de la memoria.
- Permitir acceso a la memoria compartida.
-
Sirve para hacerle creer a un proceso que dispone de más memoria de la que realmente tiene en cada momento.
-
Esta estrategia se puede lograr con estrategias como swapping.
-
Memoria física < Memoria virtual
-
El tamaño de la memoria virtual depende de la capacidad de direccionamiento (palabra). Ejemplo: si tengo direcciones de 16 bits, cada proceso puede direccionar 2^16 bytes de memoria virtual.
-
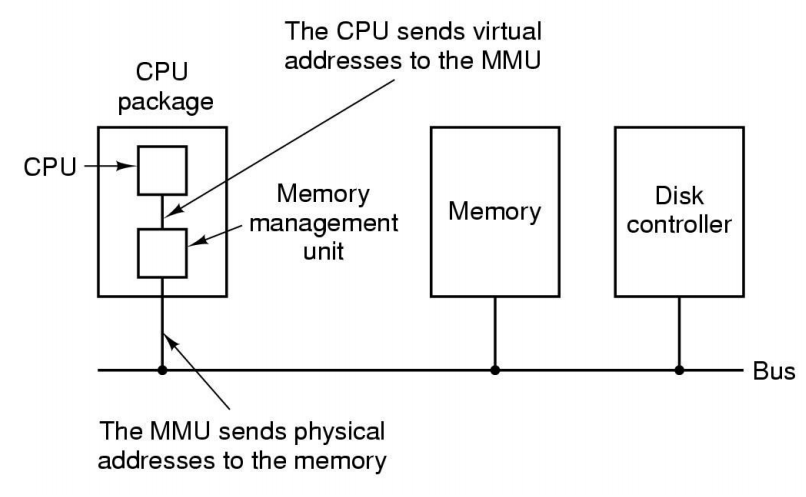
El MMU es el encargado de traducir una dirección virtual a una dirección física.
-
En realidad, traduce páginas a frames.

- Asignar:
- Es reservar una porción de la misma para un proceso.
- La porción de memoria pasa a estar ocupada por el proceso que la solicitó.
- Tenemos que saber quién es el dueño de esa opción de memoria.
- Liberar:
- La porción de memoria vuelve a estar disponible para cualquier proceso.
Pensamos en la memoria como una colección de porciones de memoria.
- Le memoria se puede agrupar en:
- Unidades de direccionamiento (bytes).
- Bloques de tamaño fijo.
- Bloques de tamaño variable.
- Mecanismos:
- Segmentación.
- Paginación.
- Segmentación + paginación.
- La memoria libre se puede organizar con:
- Un mapa de bits. Para saber qué porciones están libres.
- Una lista enlazada.
Un proceso no puede estar pisando el espacio de memoria de otro proceso, con lo cual, cada proceso debe tener un espacio que sea respetado por el resto de los procesos. Para ello:
- Cada proceso tiene su propia tabla de páginas y/o segmentos.
- Cada proceso tiene su propio espacio de direccionamiento de memoria (memoria virtual).
Queremos que dos procesos lean y escriban sobre una misma variable. Esto se puede lograr con paginación: podemos mapear dos páginas al mismo marco de página.

- El espacio de memoria virtual está dividido en bloques de tamaño fijo llamados páginas.
- El espacio de memoria físico está dividido en bloques del mismo tamaño llamados marcos o page frames.
- la MMU traduce páginas a frames. Es decir, interpreta las direcciones como página + offset. Los n bits más significativos son la página, el resto, el offset.
- Lo que se swappea son siempre páginas.
- Cuando una página no está en memoria, la MMU emite una interrupción de page fault que es atrapada por el SO.
- El SO es el encargado de sacar alguna página de memoria y subir la correspondiente al disco.

- Es básicamente lo que hay en la MMU.
- Queremos que la búsqueda sea rápida y que la tabla no ocupe mucho espacio.
- Una solución es tener una tabla de páginas multinivel:
- Los primeros bits nos llevan hacia la tabla que tenemos que consultar, y ahí usamos el resto de los bits igual que antes.
- La ventaja es que no hace falta tener toda la tabla en memoria. Se pueden swappear sus partes. Parecido as las indirecciones en los inodos.

Tabla de páginas simple

Tabla de páginas multinivel
- Page frame (el objetivo de la tabla).
- Bit de ausencia/presencia.
- Bits de protección (read/write, etc).
- Bit de dirty (con respecto al disco), para sólo guardar a disco las páginas que estén dirty.
- Bit de referenciada.
- Alguna otra información en arquitecturas particulares.
- Es una caché a nivel hardware de las tablas de página, para que acceder a ellas sea más rápido.
- Está implementada con registros muy rápidos.
- Puede buscar en paralelo.
-
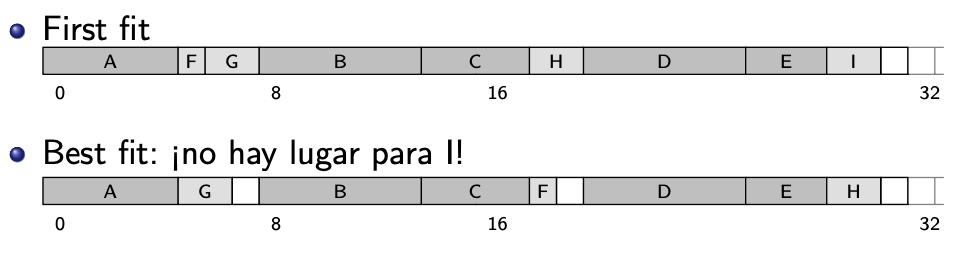
First fit: Primer bloque donde entra, asigno.
- Es rápido.
- Tiende a fragmentar la memoria.
-
Best fit: Me fijo dónde entra más justo.
-
Es más lento
-
Tampoco es mejor: llena la memoria de pequeños bloquecitos inservibles.
-
Ejemplo: secuencia de solicitudes (F, 1), (G, 2), (H, 2), (I, 2).
-
-
Worst fit: Tomo la más grande.
-
Quick fit: Se usan listas de bloques de determinados tamaño, para accederlos más rápidos.

Si la memoria está llena y necesito cargar una página nueva, aplico un algoritmo de remoción para saber qué paginas desalojar.
- FIFO: la clásica de siempre.
- Segunda Oportunidad: Como FIFO, pero si hay un HIT marco la página como Referenced, y la próxima vez que esté por bajar la página a disco le perdono la vida, la mando al final de la cola FIFO y en realidad desalojo a la siguiente página que venia en la cola (si también tiene el bit de referenced, repito el mismo procedimiento).
- LRU: Desalojo la página que hace más tiempo que no se usa. Es caro de implementar, ya que tengo que llevar cuenta de cada acceso a cada página, y además en cada desalojo tengo que recorrer la tabla buscando la página menos recientemente usada.
- Not Recently Used: La idea es establecer una prioridad para desalojar una página: las que no fueron ni referenciadas ni modificadas son las más convenientes. Le siguen las que fueron referenciadas pero no modificadas, que son “baratas” de bajar, y por último las modificadas.

- Externa: Bloques libres pero pequeños y dispersos, repartidos por el disco/memoria.
- Interna: Especio desperdiciado dentro de los propios bloques/clusters.
Cuando una página no está cargada en memoria:
- Se emite una interrupción page fault, que es atrapada por el kernel.
- Se guardan el IP y eventualmente otros registros en la pila (context switching).
- El kernel determina que la interrupción es de tipo page fault, y llama a la rutina específica.
- Hay que averiguar qué dirección virtual se estaba buscando. Usualmente queda en algún registro.
- Se chequea que sea una dirección válida y que el proceso que la pide tenga permisos para accederla. Si no es así, se mata al proceso (en Unix se envía una señal de segmentation violation, lo que la hace terminar).
- Se selecciona un page frame libre si lo hubiese, y si no, se libera mediante el algoritmo de reemplazo de páginas.
- Si la página tenía el bit dirty prendido, hay que bajarla a disco. Es decir, el proceso del kernel que maneja E/S deber ser suspendido, generándose un cambio de contexto y permitiendo que otros ejecuten. La página se marca como busy para evitar que se use.
- Cuando llega la interrupción que indica que la E/S para subir la página terminó, hay que actualizar la tabla de páginas para indicar que está cargada.
- La instrucción que causó el page fault se recomienza, tomando el IP que había quedado en el stack y los valores anteriores de los registros.
- Se devuelve el control al proceso de usuario. En algún momento el scheduler lo va a hacer correr de nuevo, y cuando reintente la instrucción la página ya va a estar en memoria.
- Es cuando no alcanza la memoria y hay mucha competencia entre los procesos por usarla.
- El SO se la pasa cambiando páginas de memoria a disco ida y vuelta.
- Es una situación altamente indeseable, porque la mayor parte del tiempo se pasa haciendo "mantenimiento" en lugar de trabajo productivo.
- Es muy común que los procesos hagan fork(). Vimos que al hacer fork, se clona la memoria al nuevo proceso.
- Mientras no se modifique, podemos ahorrarnos hacer el clonado de páginas, haciendo copy-on-write:
- Al crear un neuvo proceso se utilizan las mismas páginas.
- Hasta que alguno de los dos escribe en una de ellas.
- Ahí se duplican y cada uno queda con su copia independiente.
Los dispositivos de entrada/salida pueden ser divididos en dos categorías:
- Dispositivos por bloque (block devices): Discos duros, discos blu-ray, pendrives, etc.
- Son direccionables.
- Dispositivos por caracter (character devices): Impresoras, interfaces de red, mouses, etc.
- No son direccionables. Se lee/escribe un stream de caracteres.
Algunos dispositivos no entran en ninguna de estas dos categorías. Por ejemplo, un clock no se puede direccionar a un bloque ni tampoco generan o aceptan streams de caracteres; lo único que hacen es generar interrupciones en un intervalo definido.
Módulos de software que pueden ser añadidos al SO a modo de plugins para manejar los dispositivos de E/S.
Componente mecánico y/o electrónico que trabaja como una interfaz entre un dispositivo y el driver. Hay un controller por cada dispositivo de hardware.

- No tiene redundancia.
- Simplemente distribuye los datos entre los distintos discos duros.
- Buena velocidad de lectura si leemos bloques de distintos discos (se puede leer en paralelo).
- Más probabilidades de que uno de los discos se rompa y perdamos todos los datos.

- Redundancia pura.
- Duplica la información en todos los discos del RAID.
- Buena velocidad de lectura (se puede leer en paralelo).
- Velocidad de escritura igual o peor.


- Almacena los datos de forma distribuida en los discos a nivel de bit (RAID 2) y byte (RAID 3).
- Almacena también información de paridad.
- RAID 2 necesita 3 discos de paridad por cada 4 discos de datos.
- RAID 3 necesita 1 disco de paridad para todos los discos de datos.


- Es como RAID 3 pero a nivel de bloque en vez de bytes.
- Si se rompe un disco (sólo uno, cualquiera de ellos), se puede recuperar completamente haciendo XOR con todos los demás discos.
- Lo malo es que si quiere modificar un bloque en un disco, hay que recalcular la paridad, con lo cual hay que leer de todos los discos de nuevo.

- Junto con RAID 0, 1 y 0+1, es de los más usados en la práctica.
- La información de paridad se distribuye en los discos también, en vez de estar en un sólo disco.
- Elimina el problema que había en RAID 4.
- Si se rompe un disco, se puede recuperar, pero el proceso es complejo.

- Es como RAID 5 pero agrega un segundo bloque de paridad abajo del primero.
Los discos HDD tienen un cabezal que se mueve. Los pedidos de E/S a disco llegan constantemente, incluso antes de que terminemos con uno. Por eso, necesitamos planificar la cola de pedidos de E/S para lograr el mejor rendimiento posible.

El tiempo requerido para leer o escribir un bloque en un disco está determinado por tres factores:
- Seek time: el tiempo que lleva mover el brazo al cilindro correcto
- Delay rotacional: el tiempo que tarda el sector correcto en posicionarse debajo del cabezal de lectura.
- El tiempo de transferencia de los datos en sí.
En la mayoría de los discos, el seek time predomina sobre los otros dos, por lo tanto, reducir el seek time promedio puede mejorar la performance del sistema sustancialmente.
- Consiste en ir encolando las operaciones de lecturas al disco y ejecutarlas en el orden dado.
- Problema: Si estamos leyendo algo en el cilindro 11 y nos encolan lecturas para los cilindrdos 1, 36, 16, 34, 9 y 12 en ese orden, se van a requerir muchos movimientos del cabezal
- Consiste en realizar primero los seek que queden más cerca de la posición actual del cilindro.
- Esto acorta el seek time hasta casi la mitad comparado con FCFS.
- Tiene un problema: inanición. Si siguen llegando seeks que están más cerca, puede pasar que nunca termine leyendo los seeks que están más lejos.

- Sigue moviendo el cabezal en un mismo sentido mientras siga habiendo operaciones en ese sentido. Luego, cambia el sentido.
- Sólo necesita mantener la información del sentido actual.
- El problema:
- Los tiempos de espera no son uniformes.
- Puede llegar una solicitud para un cilindro inmediatamente anterior y hay que esperar a que se cambie de sentido.

Un archivo es una abstracción que representa un espacio de tamaño variable con acceso aleatorio de granularidad fina (a nivel de byte).
Un directorio es una lista de nombres (a directorios o a archivos)
Genera la visión de la memoria secundaria como un gran archivo de acceso aleatorio y granularidad gruesa.
- Es de más alto nivel. Genera una organización de grafo dirigido acíclico entre directios y archivos.
- Un directorio puede contener directorios y archivos.
- Los nombres de archivo son enlaces a los archivos.
- Un archivo puede contener más de un enlace (por eso es un grafo dirigido acíclico y no árbol).
Consiste en los bloques de cada archivo de manera consecutiva en el disco. Las ventajas son que es fácil de implementar, y que el rendimiento de lectura es excelente. El problema es que genera fragmentación externa. Este esquema es útil en los CD's.
Ejemplo: Borro archivo2.txt e intento insertar archivo4.txt. No se puede.


Consiste en una estructura de bloques, donde se indica cuál es el primer bloque del archivo, y cada bloque tiene un puntero al siguiente bloque. FAT implementa algo parecido a esto.
Consiste en una tabla de asignación de archivos, donde se tiene una entrada para cada bloque del disco, donde se indica:
- cuál es el bloque siguiente del archivo al cual pertenece el bloque
- si el bloque es el último de un archivo, o
- si el bloque está vacío
Una ventaja de FAT es que, para unidades pequeñas, resulta muy performante y se puede implementar con gran sencillez. Otra ventaja es que es soportado por la inmensa mayoría de sistemas operativos.
La desventaja de este método es que toda la tabla debe estar en memoria todo el tiempo.

Le asocia a cada archivo una estructura de datos llamada i-nodo (nodo índice), la cual lista los atributos y las direcciones de disco de los bloques del archivo. Una ventaja de este método con respecto a los anteriores, es que el inodo necesita estar en memoria sólo cuando está abierto el archivo correspondiente.
Se usa en UFS, ext2, ext3, ext4.


El disco se divide en grupos de bloques. Cada grupo de bloques tiene una tabla de inodos.
Los metadatos de un inodo pueden ser:
- Permisos del archivo.
- Tamaños.
- Propietario/s.
- Fechas de creación, modificación y acceso.
- Bit de archivado.
- Tipo de archivo (regultar, dispositivo virtual, pipe, etc).
- Flags.
- Conteo de referencias.
- CRC o similar.

Un soft link o symlink es básicamente un archivo que contiene el path hacia otro archivo. No se usa el número de inodo. Se implementa por software. La ventaja es que puede referenciar a archivos de otras particiones.

Los hard link son inodos que directamente apuntan al mismo archivo físico.
Es una abstracción que permite transparencia de locación respecto de las particiones. Permite montar un sistema de archivos real en cualquier directorio del sistema de archivos virtual, y el usuario tiene una visión única del sistema de archivos completo.
- Una manera de mejorar el rendimiento es mediante la introducción de un caché, es decir, una copia en memoria de bloques del disco.
- Se maneja de manera muy similar a las páginas.
- Con la introducción del caché, se introduce también el problema de la consistencia.
- Qué pasa si se corta la luz antes de que se graben a disco los cambios? Los datos se pierden.
- La solución más tradicional consiste en restaurar la consistencia del FS (en lugar de prevenirla).
- En Unix se puede restaurar con
fsck. - La idea es agregarle al FS un bit que indique "apagado normal".
- Si cuando el sistema levanta ese bit no está prendido, algo sucedió y se debe correr
fsck. - El problema es que eso tarda mucho tiempo, y mientras tanto, no se puede usar el disco.
- En Unix se puede restaurar con
- Otra solución: journaling.
-
Algunos FS, como ext3 y NTFS, llevan un log o journal, es decir, un registro de los cambios que habría que hacer.
-
Este registro se graba en un buffer circular. Cuando se baja el caché a disco, se actualzia una marca indicando qué cambios ya se reflejaron.
-
Si el buffer se llena, se baja el caché a disco. Hay un impacto en performance, pero es bajo porque:
-
Este registro se escribe en bloques consecutivos, y una escritura secuencial es mucho más rápida que una aleatorioa.
-
Los FS que no hacen journal escriben a disco inmediatamente los cambios en la metadata, para evitar daños mayores en los archivos.
-
Cuando el sistema levanta, se aplican los cambios aún no aplicados. Esto es mucho más rápido que recorrer todo el disco.
La seguridad de la información se entiende como la preservación de las siguientes características:
- Confidencialidad: que los datos privados de un usuario permanezcan privados.
- Integridad: usuarios no autorizados no deben poder modificar datos de otros usuarios sin su permiso.
- Disponibilidad: nadie debería poder perturbar el funcionamiento normal del sistema.
- Comprobación de errores.
- Dificiles de revertir.
- Se utiliza la misma clave para encriptar y para desencriptar
- Se usa una clave para encriptar (clave privada).
- Se una otra clave para descencriptar (clave pública).
- RSA.
- Calculo el hash del documento.
- Encripto el hash con mi clave. privada.
- Entrego el documento + el hash encriptado.
- El receptor lo desencripta con mi clave pública. Si lo puede desencriptar exitosamente se asegura de que yo sea el autor.
- Luego verifica que el hash obtenido se corresponda con el real del documento. Si coincide significa que nadie alteró el documento.
Matriz que contiene los permisos de un recurso.
Filas: usuarios/sujetos/grupos
Columas: Recursos que deben ser protegidos
Celda ([U, O]): Tipo de acceso del usuario U sobre el recurso O (ej. Read, Write, Read/Write, etc).
Cuando se quiere agregar un recurso nuevo a la matriz, en general se suelen definir unos recursos por defecto.
Son las columnas de la ACM. Cada recurso tiene su ACL, de la forma [(ui1, rights1), (ui2, rights2), ...].
Son las filas de la ACM. Cada usuario tiene su C-list, de la forma [(oi1, rights1), (oi2, rights2), ...].

Política de control de acceso que dice que el creador de un recurso es el dueño de ese recurso, con lo cual, el dueño es quien asigna los permisos para los otros usuarios.
Problemas:
- Flujo de la información: No podemos asegurar que los usuarios que tengan acceso a mis archivos no van a compartir los datos con otros (confianza).
- En muchas situaciones, un usuario no debería ser el responsable de decidir cómo se comparte un archivo.
Política de control de acceso que dice que el sistema.
- Tenemos distintos grados (ejemplo Top Secret < Secret < Classified, Unclassified).
- Read-down y Write up
- Cuando se hace invoca a una función en C, primero se hace un push (en el stack) de los parámetros y luego del IP para usarse como dirección de retorno de dicha función.
- Por otro lado, las variables locales se reservan también en el stack.
- Si el programa nos deja escribir arbitrariamente en una variable del stack sin hacer chequeos de tamaño, podemos pisar la dirección de retorno.
- Lo común es pisar la dirección de retorno con la dirección del payload en sí, o una dirección aproximada y rellenar con NOP, para que eventualmente al hacer retorno de la función, se ejecute el código del payload.
La idea es que el compilador inserta un valor aleatorio en el stack (el canary), justo debajo de la dirección de retorno. Al momento de retornar de la función, el compilador inserta código para chequear el valor del canary. Si el valor cambió, el programa termina. Sin embargo, hay maneras de saltearse el canary y sobreescribir el valor de retorno directamente.
- Algunos CPUs modernos tienen el bit NX para implementar DEP.
- Sirve para marcar segmentos como no-ejecutables.
- Con esto, los ataques de inyección de código dejarían de funcionar.
- Se usa cuando podemos inyectar direcciones de retorno, pero no código arbitrario (por ejemplo, porque hay DEP)
- Podemos hacer que salte a una función de la libc, como
system(). - Además, podemos también pasarle los parámetros que querramos, ya que justamente los va a sacar de la pila, la cual tenemos bajo control.
- Con esto podemos hacer
system("/bin/bash"), por ejemplo.
- En vez de saltar a funciones de librerías, se puede saltar a cualquier instrucción del segmento de texto del programa.
- Incluso, podemos saltar en la mitad de una función, en vez de saltar al principio.
- Eso haría que se ejecute ese código y, eventualmente habrá un return (el return original de la función a la cual saltamos por la mitad).
- Entre el salto original y el return, puede haber código (original de la función) que sirva para preparar algo más grande.
- Cuanto más rico sea el programa original en instrucciones usadas, más creatividad se puede tener usando Return-Oriented Programming.
- Consiste en randomizar las direcciones de las funciones y datos en cada ejecución del programa.
Los sistemas distribuidos tienen que lidiar con muchos problemas de consenso, es decir, ponerse de acuerdo.
- En entornos distribuidos no hay TestAndSet atómico.
- Cómo implementamos locks? Varias soluciones posibles.
- Un único nodo hace de coordinador.
- Problemas:
- Hay un nodo del que todo depende.
- Punto único de falla.
- Cuello de botella en procesamiento y en capacidad de red.
- Se requiere consultar al coordinador, que podría estar lejos.
- Cada interacción con el coordinador requiere de mensajes que viajan por la red, lo cual es lento.
- Solución: otro enfoque.
-
Problema: en un entorno distribuido, como se decide quién llega primero?
- El que emitió antes el mensaje?
- El que logró que sus mensajes llegaran primero al resto?
- Y si hay empate?
-
Solución: Orden parcial entre eventos (Lamport).
- Lo único importante es saber si algo ocurrió antes o después de otra cosa, sin importar exactamente cuándo.
- Lamport define un orden parcial no reflectivo entre los eventos:
- Si en un mismo proceso,
$A$ sucede antes que$B$ , entonces$A \rightarrow B$ . - Si
$E$ es el envío de un mensaje y$R$ su recepción, entonces$E \rightarrow R$ , aunque$E$ y$R$ sucedan en procesos distintos. - Si
$A \rightarrow B$ y$B \rightarrow C$ , entonces$A \rightarrow C$ . - Si no vale ni
$A \rightarrow B$ , ni$B \rightarrow A$ , entonces$A$ y$B$ son concurrentes.
- Si en un mismo proceso,
- Se implementa de la siguiente forma:
- Cada procesador tiene un clock que es monótonamente creciente en cada lectura.
- Cada mensaje lleva adosada la lectura del clock.
- Como la recepción es siempre posterior al envío, cuando se recibe un mensaje con una marca de tiempo
$t$ que es mayor al valor actual del reloj, se actualiza el reloj interno a$t+1$ .
- Si queremos además un orden total (en vez de parcial), debemos romper empates.
- Los empates se dan entre eventos concurrentes, entonces, se los puede ordenar arbitrariamente.
- Por ejemplo por el
pid(process id).
- Varios grupos de soldados comandados por generales están planeando un ataque coordinado desde distintas direcciones hacia un objetivo en común.
- Todos saben que la única forma de que el ataque salga bien es si todos los generales atacan. Si sólo algunos de ellos atacan, sus tropas van a ser destruidas.
- Los generales se pueden comunicar entre ellos vía mensajeros.
- Los mensajeros se pueden perder o ser capturados, y por lo tanto sus mensajes pueden perderse.
- Bajo estas condiciones, los generales deben ser capaces de ponerse de acuerdo si atacar o no atacar.
- Si todos los mensajeros son confiables, entonces todos los generales pueden enviar mensajeros a los demás generales, con un mensaje que diga si están dispuestos a atacar o no.
- Luego de un tiempo, todos los generales recibirán todos los mensajes de los demás generales, con lo cual, mediante una regla previamente acordada, pueden decidir si atacar o no (por ejemplo, la regla podría ser la de atacar si TODOS los demás generales quieren atacar).
- En un modelo donde los mensajeros se pueden perder (i.e. la comunicación no es confiable, los mensajes se pierden, etc), este sencillo algoritmo no funciona.
Este problema, en el mundo de las Ciencias de la Computación, es el problema de commit para bases de datos distribuidas.

En el libro de Lynch está la demostración de que no se puede llegar a un consenso en este problema.
- Hay poco que podemos hacer para resolver este problema, sin embargo, algunas variantes de este problema deben ser resueltas en sistemas reales.
- Podemos reforzar el modelo, o relajar los requerimientos del problema.
- Una opción es asumir que hay una probabilidad de pérdida de mensajes y permitir que exista la posibilidad de que el Agreement y/o la Validity se rompan.
- Otra opción es permitir que los procesos tengan aleatoriedad, de nuevo, permitiendo cierta posibilidad de que se rompa el Agreement y/o la Validity.
En el libro de Lynch está la demostración de que el algoritmo con aleatoriedad llega a un consenso. También está el algoritmo en sí.
Esta vez, consideramos el caso donde los procesos (i.e. generales en el problema Bizantino) en sí fallan, en lugar de los enlaces de comunicación (i.e. mensajeros en el problema Bizantino). Tenemos dos modelos para investigar:
-
Stopping failure: Ocurre cuando los procesos simplemente se detienen sin ninguna advertencia previa.
-
Byzantine failure: Ocurre cuando hay procesos que exhiben un comportamiento completamente arbitrario/aleatorio/inesperado/erróneo.
-
Partimos del problema del ataque coordinado que vimos antes.
-
Esta vez, los generales no se deben preocupar por los mensajeros, sino por por los posibles comportamientos traicioneros de otros generales.

Stopping failure
El teorema para el caso de Stopping failure dice que si fallan a lo sumo

Byzantine failure
El teorema para el caso de Byzantine failure dice que se puede llegar a un consenso para
- Clusters: son conjuntos de computadoras conectadas por una red, con un scheduler de trabajos común.
- Grids: con conjuntos de clusters, cada uno bajo dominio administrativo distinto.
- Clouds: clusters donde uno puede alquilar una capacidad fija o bajo demanda
El problema surge cuando una colección de procesos participa en el procesamiento de una transacción de una base de datos. Luego de este procesamiento, cada proceso llega a una "opinión" inicial sobre si la transacción debería ser committeada o abortada. Los procesos deberían comunicarse entre sí y, eventualmente, acordar si van a abortar o committear.
Dos posibles resultados:
- Terminación débil: si no hay fallas, entonces todos los procesos eventualmente deciden.
- Terminación fuerte/non-blocking: todos los procesos que no fallan eventualmente deciden.
Los algoritmos de commit que satisfacen la condición de terminación fuerte son llamados non-blocking commit algorithms, mientras que los algoritmos que satisfacen la condición de terminación débil pero no la fuerte son llamados blocking commit algorithms.
Para explicar los algoritmos, asumimos que el dominio es { 0, 1 }, donde 1 representa commit y 0 representa abort.
- Es el algoritmo de commit más conocido.
- Garantiza sólo terminación débil.
- Se llama así porque tiene dos rondas
Algoritmo:


- Es un 2PC embellecido.
- Garantiza además terminación fuerte (o sea, es un non-blocking algorithm).
Primeras tres rondas del algoritmo:

En este punto, cada proceso (fallido o no) queda clasificado en cuatro categorías excluyentes:
- dec0: procesos que decidieron 0.
- dec1: procesos que decidieron 1.
- ready: procesos que todavía no decidieron, pero están listos.
- uncertain: procesos que todavía no decidieron ni están listos.
Luego de esto el algoritmo tiene un protocolo de terminación de 3 rondas más.