This project Orchid-Fst implements a fast text string dictionary search data structure: Finite state transducer , which is short for FST in C++ language. Orchid-FST requires C++11 support (It is best to compile with GCC 7 or higher) and currently supports compilation and running on UNIX-like systems.
Fst data structure has been widely used in open source search engine: Elasticsearch and Lucene core source. It is so fast for search text string, it can be understand as a key-value map or set data structure. The query time complexity on the FST data structure is O(n), where n is the length of the actual text string with the query, independent of the size of the massive text data set. This is a very important and huge advantage.
This FST C++ open source project Orchid-Fst has the following significant advantages:
-
The FST construction process in this project can realize dump to output stream (such as external file) for FST data which has just been constructed while building FST to reduce the memory occupation. This point is especially important for dictionary data with large regularity. Because dict cannot be loaded into memory all at once to construct FST. The FST data file is then used as a memory map. Many current open source FST implementations do not have this feature. This is one of the important highlights of the project.
-
It is implements in C++ language and may be so useful if your project is just C++ development environment. There are some versions of fst open source implements, but it is much rarely implemented well in C/C++ language as a high quality code,so You can easily integrate it into your C++ development projects. As we know it has been implemented in Rust and Java.
-
It has successfully resolved UTF8-code text string,and resolve more sever bugs when text string is not english characters, such as Chinese characters and so on. It used a much more clever approach to resolves UTF8-coding text string.
-
This project presents a large number of examples of automata implementations, from which you can learn more about automata implementations for many different purposes, whether they are performed on FST data structures or used in other scenarios. The many automata data structures in this project Demo include, but are not limited to: GreaterThan,LessThan,Prefix,Str,StartsWith,Intersection,Union,Not,Levenshtein Automaton, Damerau Levenshtein Automation and so on.
-
Not only does it implement a code interface, but it also carefully implements an easy-to-use command-line tool,that is orchid-fst: ofst, with detailed instructions on how to use parameters. The ofst command-line tool has these following functions.
ofst map/set can construct a fst file from your input dictionary file,which obtained key and value from every line separated by comma when map sub-command, and it only read the first item before first comma as key when set sub-command; ofst dot can generate a dot file from fst file, which can be generate picture file,such as png file to see the fst structure by dot command,such as:
'dot -Tpng < xx.dot > xx.png' .
Another importance point is: you can see details in fst for every Chinese character! This is exhilarating.
match/prefix/range/fuzzy sub-commands executes different search in fst. You can obtain more details usage instructions by use 'ofst --help' or 'ofst map --help' or 'ofst fuzzy --help', You can try it!
,10000 **,100 **人,50 **人民,40 **心,10 北七,3 北七家,10 北京,5 北平,2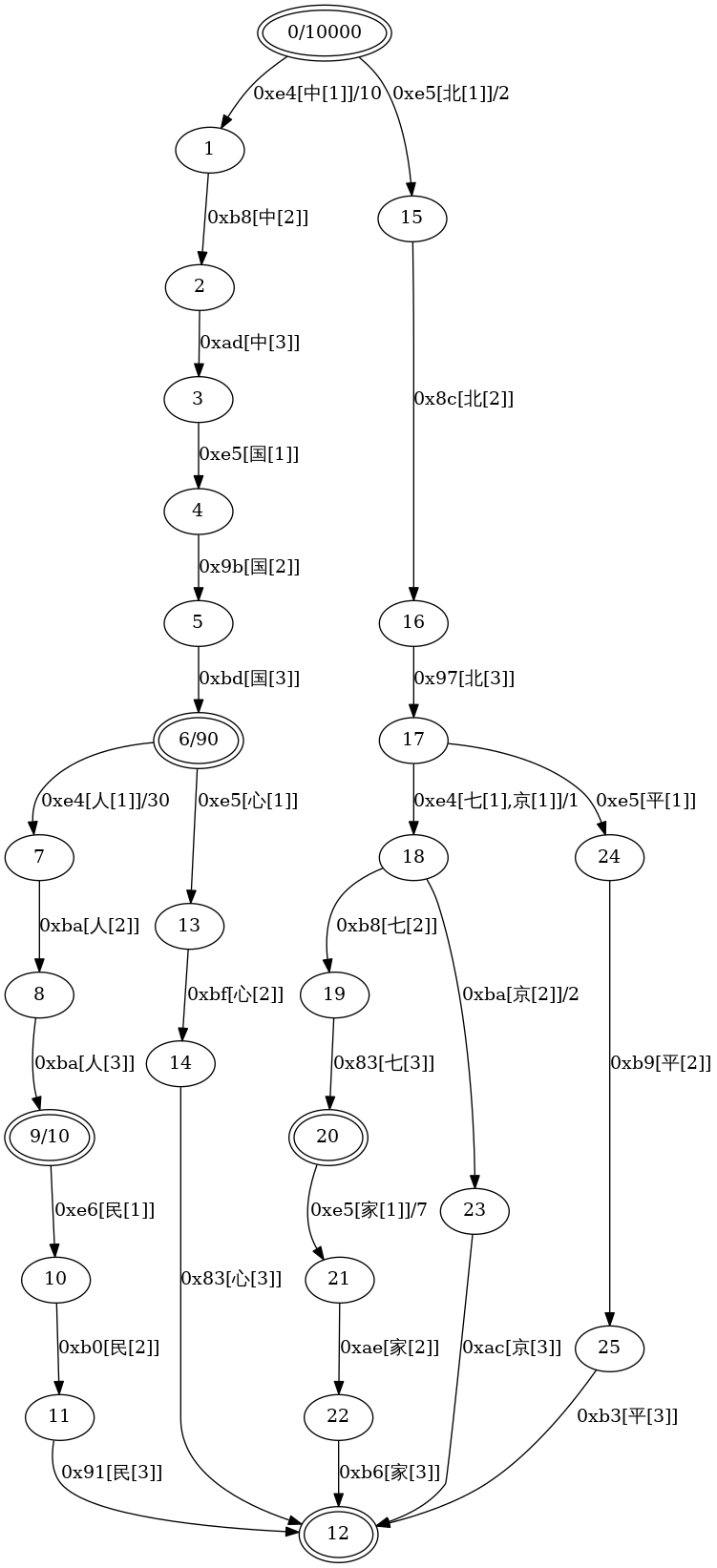
The image above shows a simple PNG image effect generated by the ofst dot subcommand of the project's command-line tool ofst with the simple dictionary text data shown above. It can clearly display the structure of multi-byte encoded characters such as Chinese characters. One important thing to note is that node 17 in the figure represents the first common byte of both '京' and '七'. This is one of the common bugs in many other open source FST implementations, and this project perfectly addresses the problem.
-
This fst project implements LRUcache and LFUcache, which used in constructing fst data structure. In order to prevent excessive memory usage, lruCache plays a good trade-off role in the process of constructing FST.
LruCache can build an approximate minimum FST tree for you, to achieve the approximate minimum space effect. If the memory space is sufficient, it is recommended that the available cache capacity of the lruCache be set as large as possible when building the FST. In this way, the FST is built as small as possible because space is saved as much as possible.
-
Considering that the dictionary file construction of FST always requires the input to be lexicographically ordered, this project implements a good module of large file external sorting function, and also implements an easy-to-use command-line tool, lfsort,to sort the large text file separately. Of course, the FST command-line tool already has large file sorting integrated into it, and by default it inputs large text files that are unsorted. Large file sorting is also time-consuming. If your input dictionary files are already sorted, you can display the specified '-s' or '--sorted' arguments to avoid sorting large files before constructing FST. You can enter 'lfsort --help' to see detailed instructions for large file sort command-line tool lfsort.
ofst: Orchid-Fst is a smart Fst command line tool
Usage: ofst [OPTIONS] SUBCOMMAND
Options:
-h,--help Print this help message and exit
Subcommands:
map construct fst data file from a key-value(separated with comma
every line) dictionary file.
set construct fst data file from a only key(no value) dictionary
file.
dot generate dot file from fst data file, which can be converted
to png file using dot command like: dot -Tpng < a.dot > a.png,
then you can view the picture generated.
match execute accurate match query for a term text in the fst.
prefix execute prefix query starts with a term text in the fst.
range execute range query in the fst.
fuzzy execute fuzzy query in the fst,it works by building a Levenshtein
or Damerau-Levenshtein automaton within a edit distance.
Please contact dingbinthu@163.com for related questions and other matters not covered. Enjoy it!
lfsort: A smart large file sort command line tool
Usage: lfsort [OPTIONS]
Options:
-h,--help Print this help message and exit
-f,--input-file TEXT:FILE REQUIRED input file which is often a huge large file to sort
-o,--output-file TEXT:PATH(non-existing) REQUIRED
output file which store result sorted from input file
-w,--work-directory TEXT:DIR=/tmp work directory specified for total processing,default /tmp if not set
-t,--thread-count UINT:INT in [1 - 32]=4
threads count used for sort large file,default 4 if not set
-s,--split-file-count UINT:INT in [1 - 1000]=6
count number of large file split,default 8 if not set
-p,--parallel-task-count UINT:INT in [2 - 20]=3
paralleled running task count for merge sorted intermediate files, default 3 if not set
-i,--ignore-empty-line whether ignore all empty lines to result file,default false if not set
Please contact dingbinthu@163.com for related questions and other matters not covered. Enjoy it!
About this project use to log in to print component tulip - log can be found in the author's open source release of another project: https://github.com/apollo008/tulip-log. One of the basic premises involved in using the project's command-line tools, ofst and lfsort, is the need to configure a definition file for the tuliop log in the current directory. It is commonly named logger.conf. Also included in this project is the rich C++ use of unit testing CppUnit module to ensure the quality of the code function. misc/config/logger.conf is a configuration file example for Tulip Log: logger.conf.
Levenshtein automata and Damerau Levenshtein automata implementation process details are actually quite complex, on this topic is not the focus of this project, although the source code of this project completely contains the clever and efficient implementation of Levenshtein and Dameau Levenshtein fuzzy query. I believe it will be helpful for you to understand the fuzzy query algorithm of Levenshtein and Damerau Leveshtein's edit distance measure. On the topic of using Levenshtein or Damerau Levenshtein automata to quickly query similar strings in search engines, readers who are interested can read another article by the author:<搜索引擎中相似字符串查找那些事儿> https://mp.weixin.qq.com/s/0ODgrWSVdRnYZxGRGmEdsA.
At last,the algorithm efficiency of this implementation is theoretically very efficient,including the process of building FST and querying FST. More detailed performance test data will be added in the following versions.
This project Orchid-Fst currently supports compilation and installation in a UNIX-like environment. It relies on the following third-party libraries:
- cppunit
- tulip-log
Before compiling and installing the Orchid-Fst project, you should first install the above two dependent libraries, one self-research log library Tulip-Log, one unit test library CppUnit, which are in the share directory and can be compiled in advance.
Note: In Ubuntu Linux, You may should install zlib by command: 'sudo apt install zlib1g-dev' before install this project. Both in Ubuntu and Centos Linux, you'd better use gcc7/g++7 version or above.
git clone https://github.com/apollo008/orchid-fst.git orchid-fst.git
cd orchid-fst.git
vim src/CMakeLists.txt
#change line 11 from 'set(${TOP_PROJECT_NAME_UPPER}_DEPEND_PREFIX_DIR $ENV{HOME}/local) #need set' to 'set(${TOP_PROJECT_NAME_UPPER}_DEPEND_PREFIX_DIR /home/xx/local) #need set'
make build-dir
cd build-dir
cmake -DENABLE_BUILD_SHARE=ON ../src #firstly compile share,denpdenc libs:cppunit and tulip
rm -rf * #clear build-dir,then begin to compile orchid-fst project
cmake -DCMAKE_INSTALL_PREFIX=/path/to/install ../src
make -j4
make install
make test #run unittest
xxxxxx@cent7ay:~/work/projects/orchid-fst.git/build-dir$ make test
Running tests...
Test project ~/work/projects/orchid-fst.git/build-dir
Start 1: common_util_unittest
1/4 Test #1: common_util_unittest ............. Passed 0.01 sec
Start 2: cache_unittest
2/4 Test #2: cache_unittest ................... Passed 280.42 sec
Start 3: fst_unittest
3/4 Test #3: fst_unittest ..................... Passed 21.83 sec
Start 4: large_file_sorter_unittest
4/4 Test #4: large_file_sorter_unittest ....... Passed 0.01 sec
100% tests passed, 0 tests failed out of 4
Total Test time (real) = 302.27 sec
Now lfsort and ofst executable will be generated in < /path/to/install >/bin; and corresponding .so file will be under the lib directory. run command 'ofst --help' or 'lfsort --help' will make you be familiar for their usage.
Note: Before running the command line tool, you need to place the logger.conf log configuration file in the current directory. An example of this configuration is above or you can obtain the example logger.conf file from misc/config/logger.conf of the project. Also, don't forget to create logs at the current path of the program as configured in logger.conf. Otherwise, the program will run an error and exit. Alternatively, controlling the third line of logger.conf log level INFO or DEBUG, ERROR, or WARN will give you log output information for different verbates.
Please contact dingbinthu@163.com for related questions and other matters not covered. Enjoy it.