- Clone the repository:
git clone --filter=blob:none --quiet https://github.com/anuzzolese/machine-reading - Move inside the folder machine-reading by command line and run the installation:
pip install .
The machine reading suite is meant to query multiple machine readers for generating RDF from textual documents.
RDF are produced by using the N-Quad syntax.
The suite comes along two default machine readers, i.e. (i) FRED and (ii) Text2AMR2Fred.
The processing can be executed with the script mr.py that can be found inside the root folder of the project.
The mr.py script accepts a CSV file as input and it can be used in the following way
usage: mr.py [-h] [-o NQuad out file] [-d CSV delimiter] [-n Base namespace] [-m Modality] input
positional arguments:
input The input RML mapping file for enabling RDF conversion.
optional arguments:
-h, --help show this help message and exit
-o NQuad out file, --output NQuad out file
Output file. If no choice is provided then standard output is assumed as default.
-d CSV delimiter, --delimiter CSV delimiter
The delimiter used in the CSV for separating columns, e.g. ',', ';', ' ', etc. If no choice
is provided then ',' is used as default.
-n Base namespace, --namespace Base namespace
The base namespace used for generating URIs. If no choice is provided then
'https://w3id.org/stlab/mr_data/' is used as default.
-m Modality, --mode Modality
The modality adopted for running the script. Possible values for this argument: (i) fred;
(ii) amr2fredbase; (iii) all. In case 'fred' or 'amr2fred' are used then only Fred or
AMR2FRED are used for generating graphs, respectively. If 'all' is provided all machine
readers are used. If no value is provided for this argument the 'all' is used as default.
The input CSV processed by mr.py is composed of 4 columns, i.e.:
- corpus_id, which is an identifier for a corpus;
- document_id, which is an identifier of a document within a corpus;
- sentence_id, which is an identifier of document sentence within a corpus;
- content, which is the content of sentence to process.
The following is an example:
| corpus_id | document_id | sentence_id | content |
|---|---|---|---|
| MusicBO | 3 | 140 | That meant to throw yourself into the work body and soul, to sacrifice body and soul, to press and exert every fibre of the body, every faculty of the soul, towards the one aim of not only producing your friend's work, but of producing it splendidly and to his advantage. |
| MusicBO | 2 | 3763 | These meetings were full of agreeable impressions, to which frequent walks in the beautiful park of Biebrich Castle contributed. |
The following is a usage example that:
- accepts as input CSV named
MusicBO_ID_sent_test.csvcontaining tabular data separated by ';'; - produces RDF as output by using
https://w3id.org/stlab/mr_data/as a base namespace for generating URIs; - uses Text2AMR2FRED only as machine reader;
- saves the N-Quad output in a file named
out.nq
python mr.py -m amr2fred -d ';' -n 'https://w3id.org/stlab/mr_data/' -o out.nq MusicBO_ID_sent_test.csv
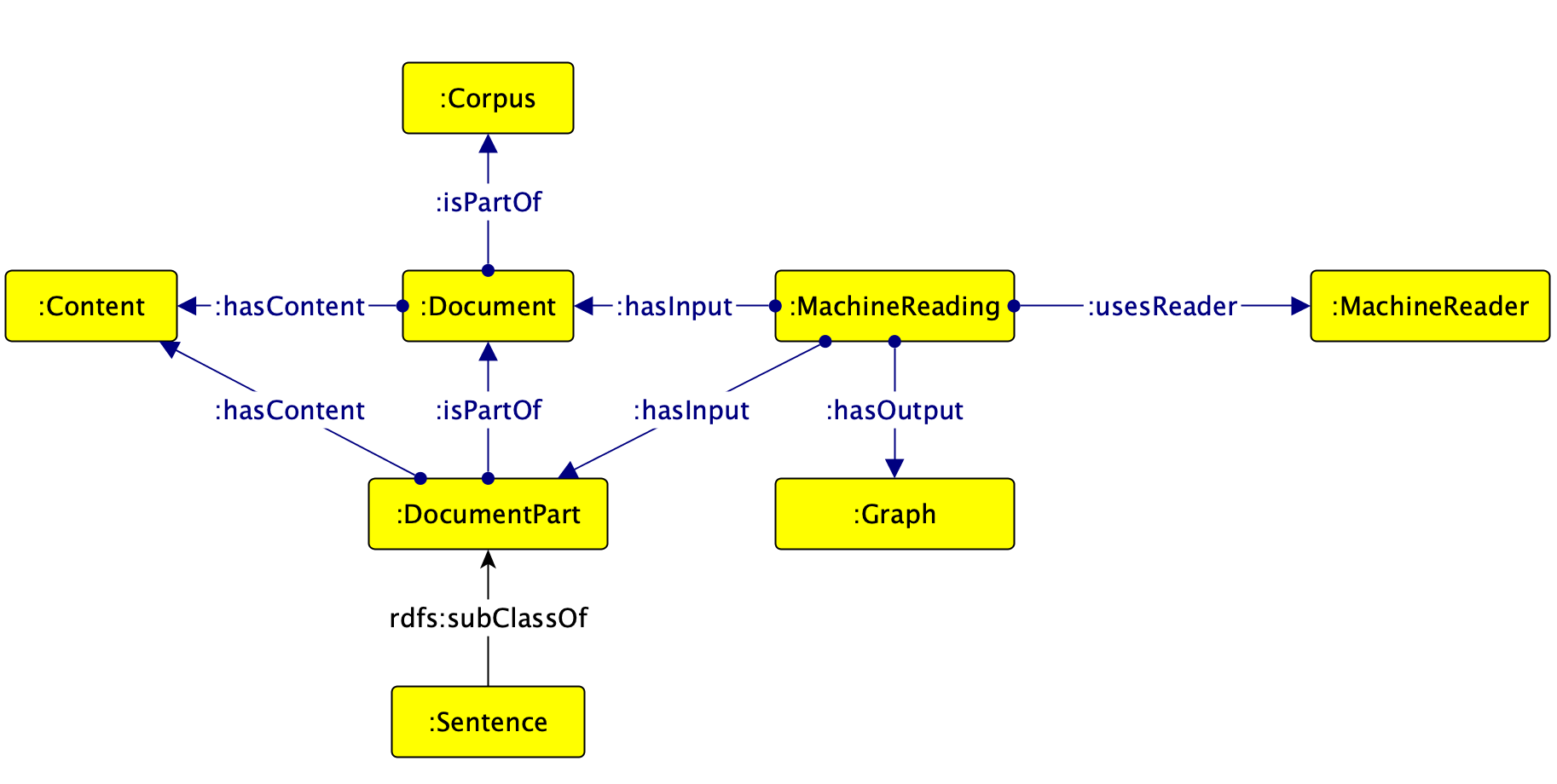
The resulting graph is then modelled with the following ontology represted with a Graffoo notation.