Deep Learning for Natural Language Processing
This repo contains code for my experiments in Deep Learning for NLP. Where possible, I'll try to provide a direct link to a Colab Notebook. I'll be using PyTorch.
For feedback, feel free to reach me on: '{}@{}.com'.format('abhimanyu.talwar1', 'gmail')
List of Experiments
-
Simple LSTM based Language Model with Beam Search (Colab Notebook)
-
Visualization of Layer Activation Distribution with & without BatchNorm (Colab Notebook)
Experiment Details
Simple LSTM based Language Model with Beam Search
-
My implementation of a simple LSTM based language model with Beam Search (for sentence generation), trained on the WikiText-2 dataset.
-
I used this language model to see if there is any bias in the underlying dataset. I started with the seed words 'he' and 'she' and sampled random sentences starting with these seedwords (see below). I observer that sentences beginning with 'he' were more or less about sports, and those beginning with 'she' were about music.


Visualization of Layer Activation Distribution with and without BatchNorm
-
Inspired by the paper How Does Batch Normalization Help Optimization?, this notebook trains a VGG-11 architecture on CIFAR-10 and compares layer activation distributions with and without BatchNorm. I observe activations of Layer 10 of the original VGG11 network (the one which does not use BatchNorm).
-
Distributional stability of activations is similar across epochs, BN or no BN: The plots below show disitribution of activations of Layer 10, with and without using BatchNorm (see notebook for code). I do observe a slight shift in the distribution (without BatchNorm) between epochs 0-10, however it does not seem severe (sorry for not being precise!).
Santurkar et. al do note in the paper that the "difference in disitributional stability [...] seems to be marginal."
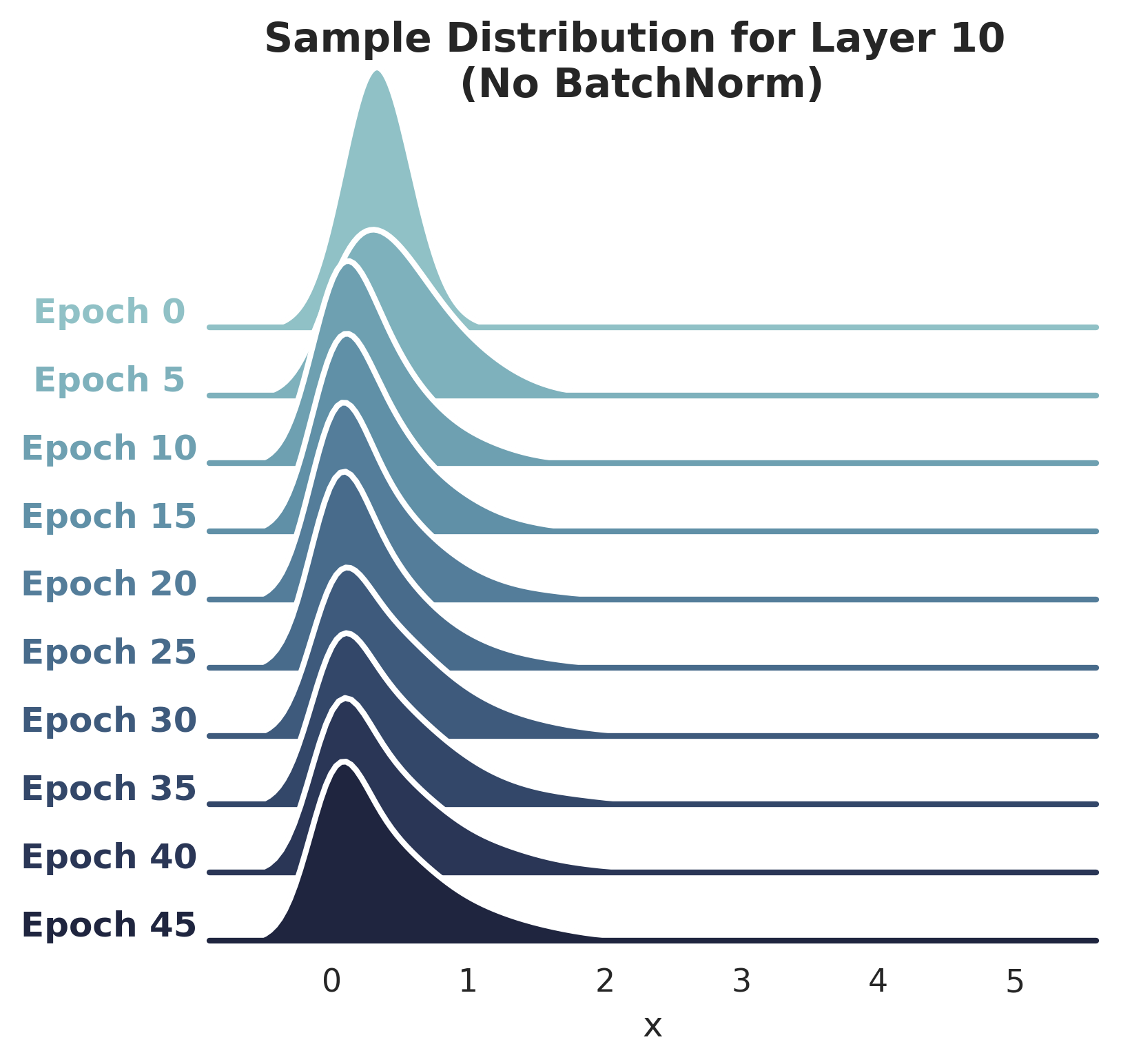
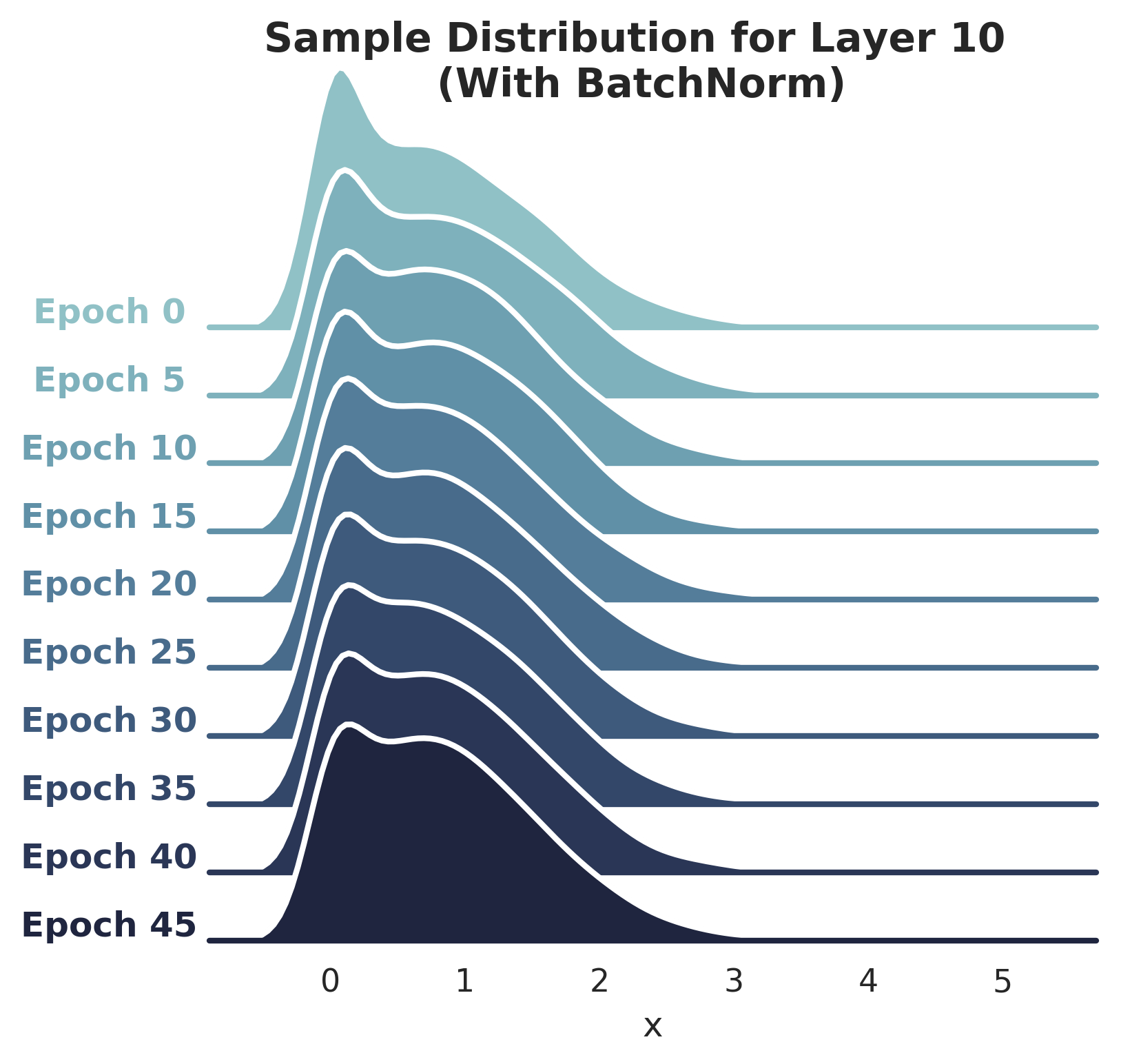
-
BN speeds up training even if distribution stabilization effect is suppressed: Borrowing from the authors' experiments, I injected random Gaussian noise after the first BatchNorm layer which precedes Layer 10, with the intent of destabilizing the activation distribution again. The plots below show the impact of this noise on distribution of Layer 10 activations (for networks with and without BatchNorm).
The plot below shows training performance (loss and accuracy for train/validation sets). If the hypothesis is that BatchNorm improves training by stabilizing activation distributions, then that seems somewhat dispelled by this plot. The blue lines plot the regime where I introduced noise *after* the BatchNorm layer, to destabilize activations. We can observe that even after introducing noise, training accuracy improved at a faster pace, than in the case of the black line, which plots the vanilla regime (no noise and no BatchNorm), at least for the first 15 epochs or so.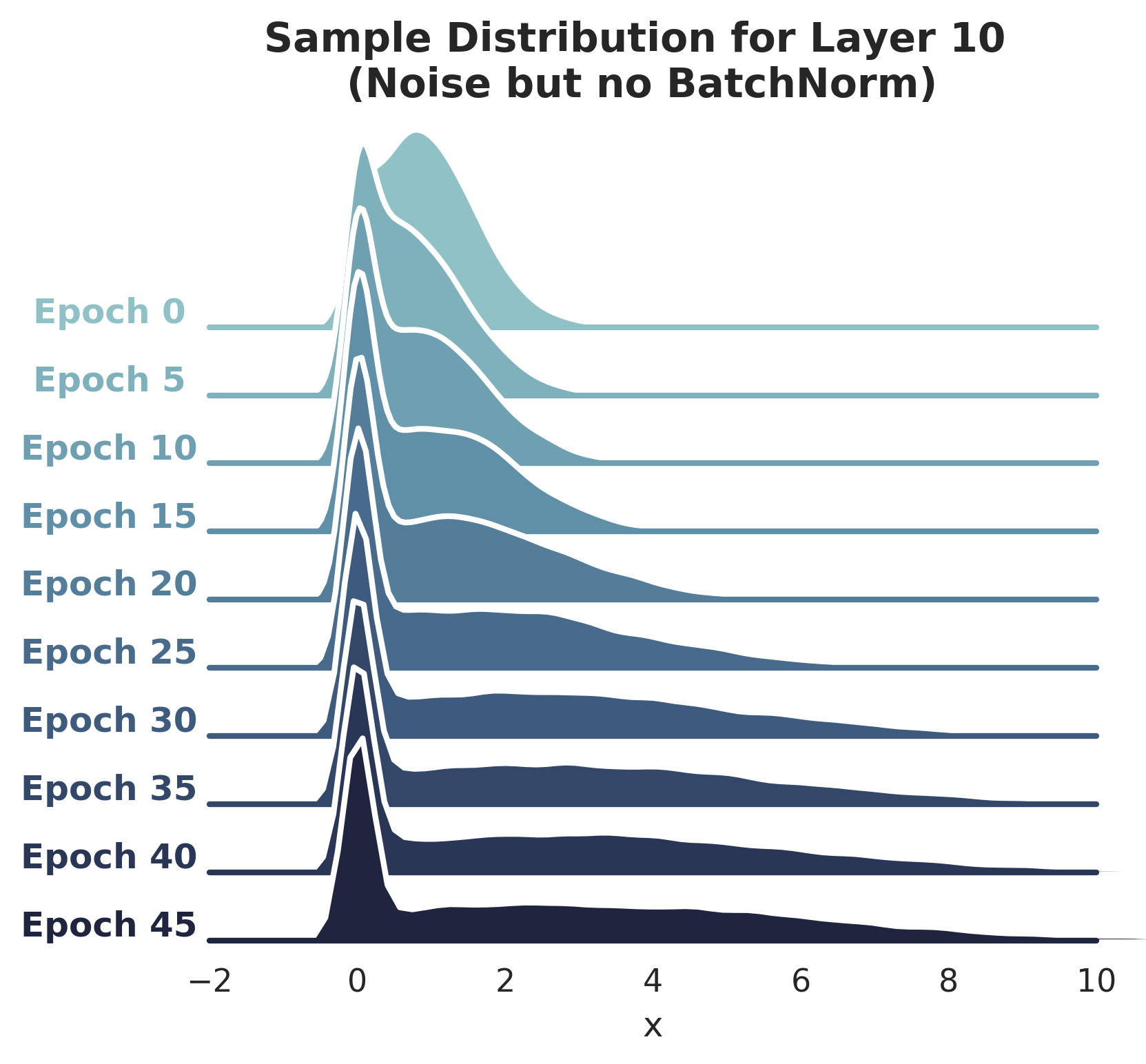
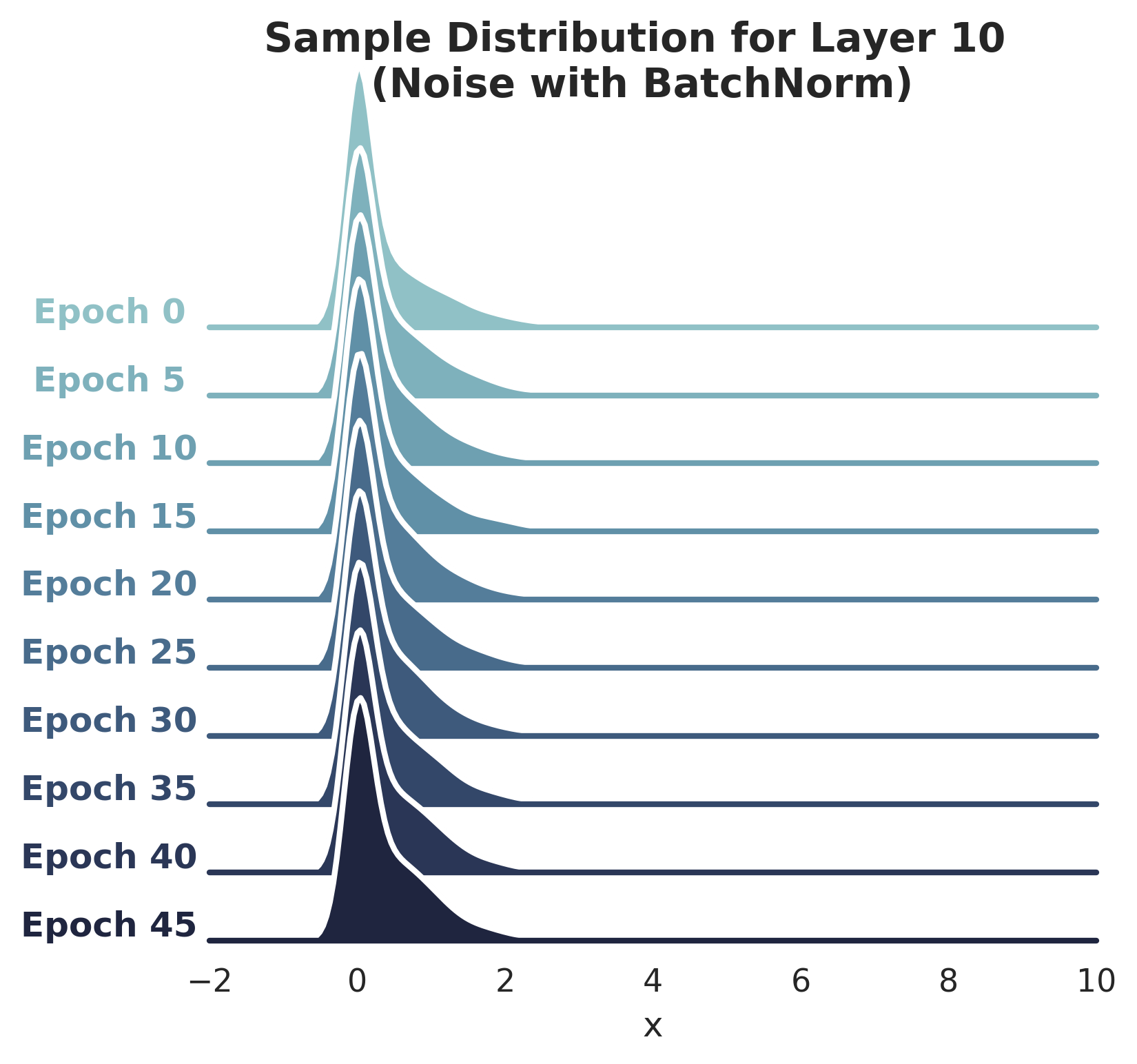
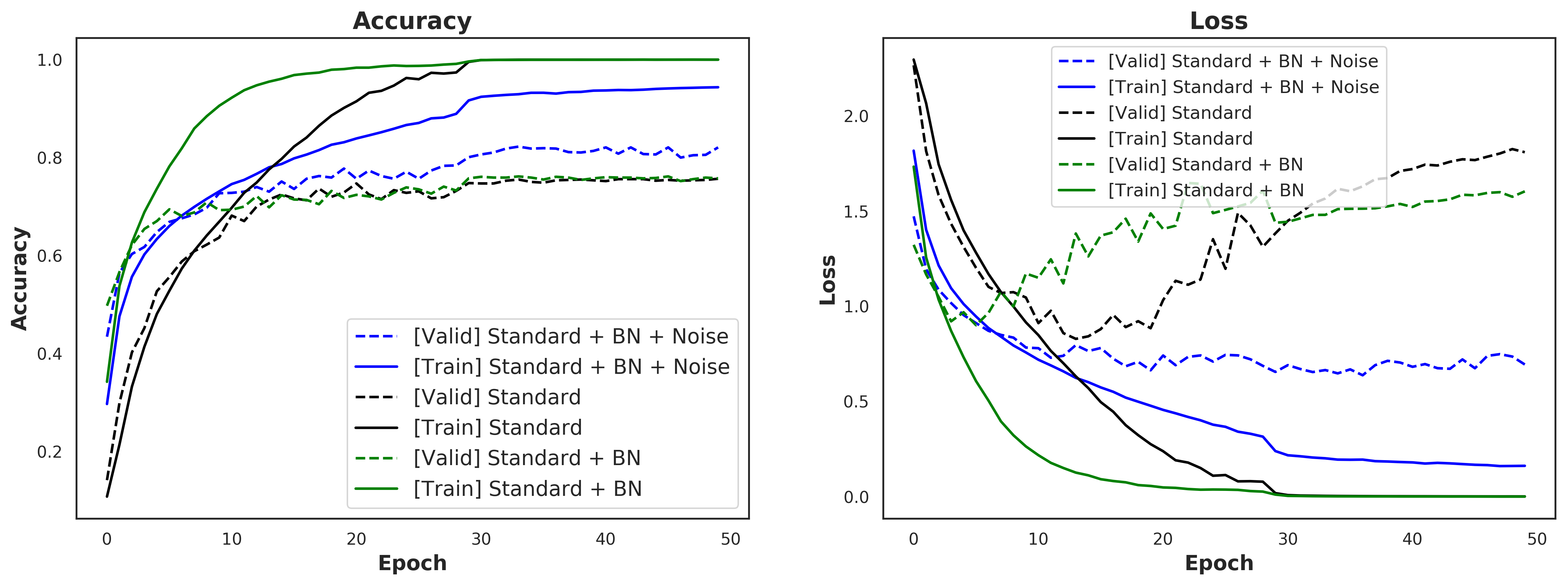
-
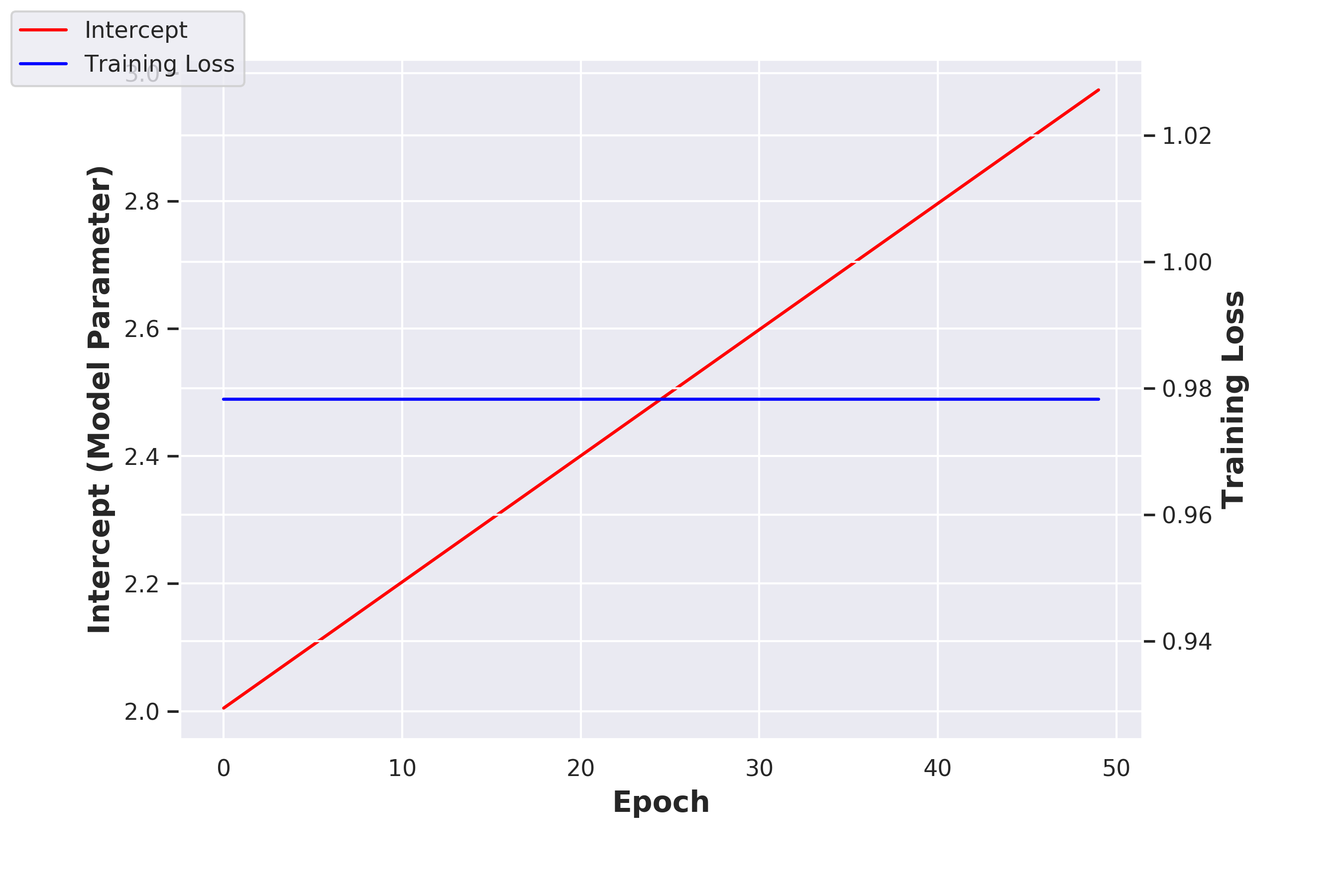
Does mere whitening of a layer's outputs suffice for stabilizing activation distribution? Authors Ioffee and Szegedy note in their original BatchNorm paper that mere whitening of a layer's activations does not work. They describe a toy example in which a single layer adds an intercept (which is learned) to its inputs, and then normalizes the output by subtracting the mean over the outputs. They explain that if the gradient calculation does not take this normalization into account, then the layer's output and correspondingly the loss would never change even as the intercept value continues to increase. I have reproduced that toy example in my Colab Notebook. The plot below shows the result and confirms that the loss doesn't change even as the intercept continues to increase.






Visualizing BERT Attention for SQuAD
- Visualize BERT's attention of a Question over Question+Context from the SQuAD 2.0 dataset. An example Context and Question pair from the Validation set: Context:
The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse ("Norman" comes from "Norseman") raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries.
Question:
In what country is Normandy located?
BERT has multiple parallel attention heads. The figure below shows the attenion visualization for Layer 10. The darker the color, the closer the attention weight is to 1.0. The answer to this Question is "France". The interpretation of attention is not entirely clear and needs more work. One can observe that the token immediately after "France" in the Context text gets a very high attention weight in this Attention Head. The token "France" also gets a higher weight than rest of the tokens.

- Credits: A big shoutout to Hugging Face. I used their BERT implementation and associated training code. My contribution was finetuning BERT on SQuAD 2.0, and writing the code for extracting/visualizing attention.