Double Trouble: How to not explain a text classifier's decisions using counterfactuals synthesized by masked language models?
Thang Pham, Trung Bui, Long Mai, Anh Nguyen (2022). Oral presentation at AACL-IJCNLP 2022
Table of Contents
The project provides a rigorous evaluation using 5 metrics and 3 human-annotated datasets to better assess the attribution method Input Marginalization and compare with Leave-one-out - a simple yet strong baseline which remove a feature (i.e., token) by simply replacing it with an empty string. The source code was released for the following publication:
This repository contains source code necessary to reproduce some of the main results in our paper.
If you use this software, please consider citing:
@inproceedings{pham2022double,
title={Double Trouble: How to not explain a text classifier's decisions using counterfactuals synthesized by masked language models?},
author={Pham, Thang M and Bui, Trung and Mai, Long and Nguyen, Anh},
year={2022},
booktile="Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing",
publisher = "Association for Computational Linguistics",
}
- Anaconda 4.10 or higher
- Python 3.7 or higher
- pip version 21 or higher
-
Clone the repo
git clone https://github.com/anguyen8/im.git
-
Create and activate a Conda environment
conda create -n im python=3.9 conda activate im
-
Install required libraries
pip install -r requirements.txt
-
Change the working directory to
srcand exportPYTHONPATHbefore running any script.cd src/ export PYTHONPATH=/path/to/your/im:/path/to/your/im/src:/path/to/your/im/src/transformers # For example export PYTHONPATH=/home/thang/Projects/im:/home/thang/Projects/im/src:/home/thang/Projects/im/src/transformers # Optional: Single or multiple GPUs # Single GPU export CUDA_VISIBLE_DEVICES=0 # or whatever GPU you prefer # Multiple GPUs export CUDA_VISIBLE_DEVICES=0,1,2,3... # list of GPUs separated by a comma
-
Download the pre-computed pickle files of masked examples used for attribution methods and human highlights used for evaluation by running the following script
python auto_download.py
Summary of the features provided (out-of-the-box):
- BERT-based classifiers pre-trained on SST-2, e-SNLI, and MultiRC were uploaded to HuggingFace and will be loaded directly in the code for the corresponding task.
- Generate intermediate masked text (i.e. with MASK) for
LOOandIM(which needs another step to replace the MASK with BERT suggestions in order to generate counterfactuals).- We also provide a pre-computed pickle file of these intermediate masked examples here.
- Run attribution methods
- (
LOOEmpty,LOOUnkLOOZero,IM) onSST-2,SST,ESNLI,MultiRCdatasets. - (
LIME,LIME-BERT) onSSTdataset.
- (
- Evaluate the generated attribution maps (by one of the above methods) using one of the following quantitative metrics:
auc,auc_bert,roar,roar_bert,human_highlights.- We provide the pre-processed and quality-controlled human highlights used in the paper (download here).
Run the following turn-key script to generate quantitative results
bash ../scripts/run_analyzers.sh ATTRIBUTION_METHOD METRIC TASK_NAME-
Replace
ATTRIBUTION_METHODwith on of the following methods:LOOEmpty,LOOUnk,LOOZero,IM,LIME,LIME-BERT. -
Replace
METRICwith one of the following metrics:auc,auc_bert,roar,roar_bert,human_highlights. -
Replace
TASK_NAMEwith one of the following tasks:SST-2,SST,ESNLI,MultiRC.
If the selected metric is roar or roar_bert, after generating attribution maps for LOO and IM, we need to run the following script to re-train and evaluate new models.
# Change the directory to /src/transformers before running the script run_glue.sh
cd transformers/ # Assume you are now under src/
bash run_glue.shWe also provide an interactive demo to compare the qualitative results between LOOEmpty and IM.
# Make sure your working directory is src/ before running this script
# The positional arguments are: task_name text_a text_b theta which is the threshold used to binarize attribution maps (default value is 0.05)
# For SST
bash ../scripts/run_demo.sh "SST" "Mr. Tsai is a very original artist in his medium , and What Time Is It There ?" "" 0.05
# For ESNLI
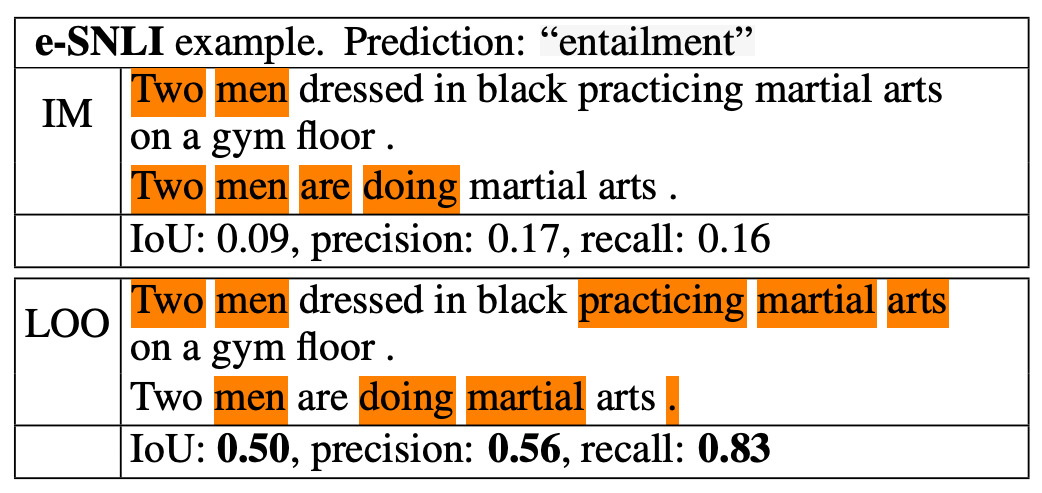
bash ../scripts/run_demo.sh "ESNLI" "Two men dressed in black practicing martial arts on a gym floor ." "Two men are doing martial arts ." 0.05For example, when running the above script for ESNLI, we will get this output:

which is similar to one of our figures (i.e. Fig. 3) shown in the paper.
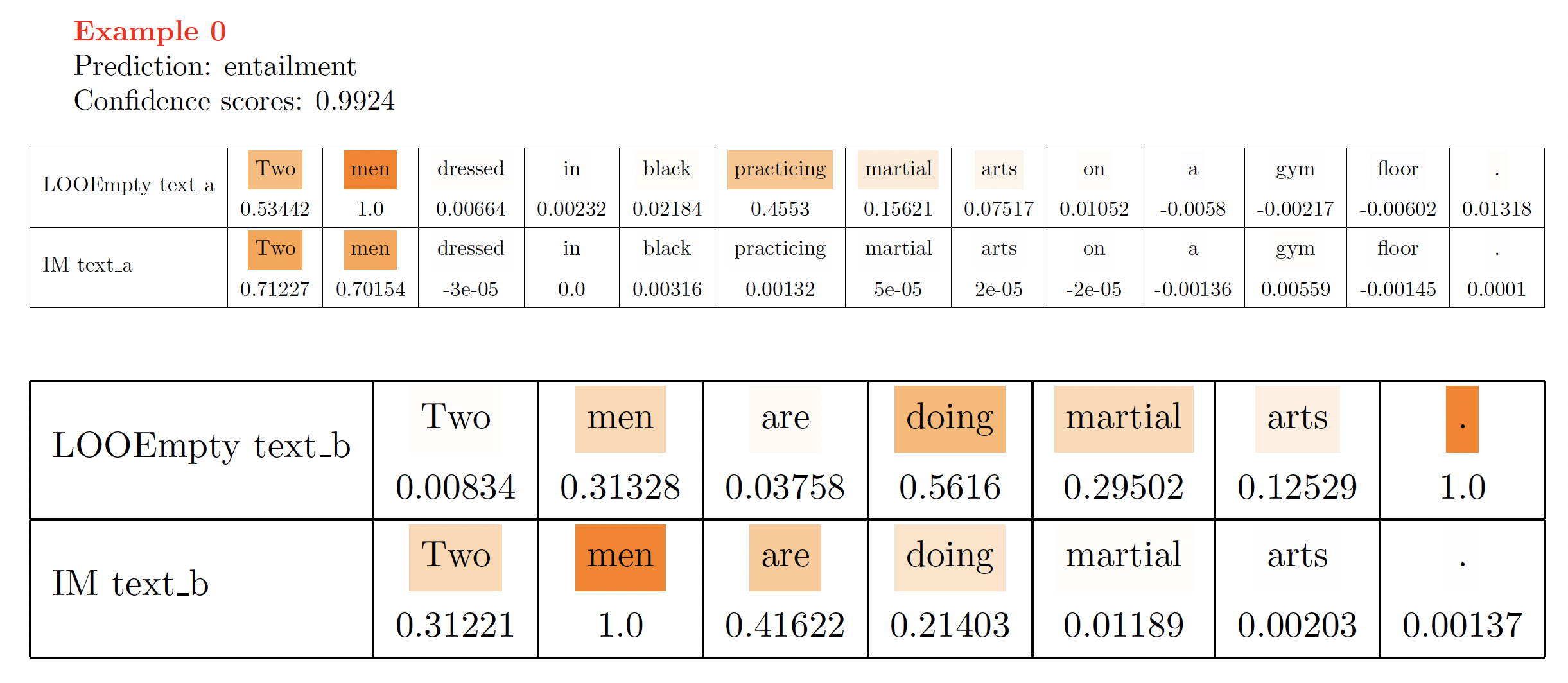
For the comparison between LOOEmpty and IM in terms of real-valued attribution maps, the above script will generate a tex file under the directory data/attribution_maps/.
We just need to simply convert this file to PDF format for viewing.
See the open issues for a full list of proposed features (and known issues).
Distributed under the MIT License. See LICENSE.txt for more information.
The entire code was done and maintained by Thang Pham, @pmthangxai - tmp0038@auburn.edu. Contact us via email or create github issues if you have any questions/requests. Thanks!
Project Link: https://github.com/anguyen8/im