


Welcome to EDA GPT, your comprehensive solution for all your data analysis needs. Whether you're analyzing structured data in CSV, XLSX, or SQLite formats, generating insightful graphs, or conducting in-depth analysis of unstructured data such as PDFs and images, EDA GPT is here to assist you every step of the way.
EDA GPT streamlines the data analysis process, allowing users to effortlessly explore, visualize, and gain insights from their data. With a user-friendly interface and powerful features, EDA GPT empowers users to make data-driven decisions with confidence.
To get started with EDA GPT, simply navigate to the app and follow the on-screen instructions. Upload your data, specify your analysis preferences, and let EDA GPT handle the rest. With its intuitive interface and powerful features, EDA GPT makes data analysis accessible to users of all skill levels.
-
Structured Data Analysis:
- Analyze structured data by uploading files or connecting to databases like PostgreSQL. Supports csv,xlxs & sqlite
- Provide additional context about your data and elaborate on desired outcomes for more accurate analysis.
-
Graph Generation:
- Generate various types of graphs effortlessly by specifying clear instructions.
- Access the generated code for fine-tuning and customization.
-
Analysis Questions:
- Post initial EDA, ask analysis questions atop the generated report.
- Gain insights through Plotly graphs and visualization reports.
-
Comparison of Performance:
- Compare the performance of EDA GPT & pandasai based on accuracy, speed, and handling complex queries.
Loadingxychart-beta title "Comparison of EDA GPT(blue) and PandasAI Performance(green)" x-axis ["Accuracy", "Speed", "Complex Queries"] y-axis "Score (out of 100)" 0 --> 100 bar EDA_GPT [90, 92, 90] bar PandasAI [85, 90, 70]
-
LLMs (Large Language Models):
- Choose from a variety of LLMs based on dataset characteristics. Supports HuggingFace,Openai,Groq,Gemini models. Claude3 & GPT4 is available for paid members.
- Consider factors such as dataset size and analysis complexity when selecting an LLM. Models with large context length tend to work better for larger datasets.
-
Unstructured Data Analysis:
- Analyze unstructured PDF data efficiently. Table structure and Images are infered from unstructured data for better analysis.
- Provide detailed descriptions to enhance LLM decision-making.
- Has Internet Access and follows action/Observation/Thought principle for solving complex tasks.
-
Multimodal Search:
- Search answers from diverse sources including Wikipedia, Arxiv, DuckDuckGo, and web scrapers.
- Analyze images with integrated Large vision models.
-
Data Cleaning and Editing:
- Clean and edit your data using various methods provided by EDA GPT.
- Benefit from automated data cleaning processes, saving time and effort.
-
Capable of analyzing impressive volume of structured and unstructured data.
-
Unstructured data like audio files, pdfs, images can be analyzed. Youtube video can be analyzed as well for summarizing content.
-
Special class called Lang Group Chain is designed to handle complex queries. It is currently unstable but the architecture is useful and can be enhanced upon. It essentially breaks down a primary question into subquestions represented as nodes. Each node have some dependency or codependency. Special data structures called LangGroups stores these Lang Nodes. These are sorted in topological order and grouped on basis of same indegree. Each group is passed to llm with previous context to iteratively reach the answer. This kind of architecture is useful in questions like : Find M//3 + 2 where M is age difference between Donald Trump and Joe Biden plus the years taken for pluto to complete one revolution. Notice we need to form sequence of well defined steps to solve this like humans do. This costs more llm calls.
-
Advanced rag like multiquery and context filtering is used to get better results. Tables are extracted while making embeddings if any.
-
In Structured EDA GPT section you are provided with interactive visualizations, pygwalker integration, context rich analysis report.
-
You can talk to EDA GPT and ask it to generate visuals, compute complex queries on dataframe, derive insights, see relationships between features and more. ALl with natural language.
-
A wide range of llms are supported and keeping privacy in mind, one can use ollama models for offline analysis.
-
Autoclean is implemented to clean data based on various parameters like linear-regression.
-
Classificatio models are used for faster inference instead of using llms for explicit classification wherever it's needed.
NOTE : It is advised to provide context rich data manually to the llm before analysis for better results after it is done.
RECOMMENDATIONS : Gemini, OpenAI, Claude3 & LLAMA 3 models work better than most other models.
System Architecture
- Structured Data EDA
graph TB
subgraph STRUCTURED-DATA-ANALYZER
DATA(UPLOAD STRUCTURED DATA) --> analyze(ANALYZE) -- llm analyzes --> EDA(Initial EDA Report)
detail[Deals With Relational Data]
end
subgraph VStore
vstore[(VectorEmbeddings)]
includes([FAISS vstore])
end
EDA(Initial EDA Report)-->docs(DOCUMENT STORE)
subgraph CALLING-LLM-LLMCHAIN
prompttemplate(prompts)-->docschain(create-stuff-docs-chain)
llm(llm choice)-->docschain(create-stuff-docs-chain)
vstore[(VectorEmbeddings)] -- returns embeddings --> retriever(embeddings as-retriever) -->retrieverchain(retriever-chain--->retrieves vstore embeddings)
docschain(create-stuff-docs-chain)-->retrieverchain(retriever-chain--->retrieves vstore embeddings) --> Chain(chain-->chain.invoke) --> result(LLM ANSWER)
end
subgraph VSTORE-INTERNALS
coderag([coding examples for rag])-->docs(DOCUMENT STORE)
docs(DOCUMENT STORE)--preprocess-->preprocessing([splitting,chunking,infer tables, structure in text data])
preprocessing--embeddings-->embed&save(save to vstore)--save-->vstore[(VectorEmbeddings)]
end
subgraph EDAGPT-CHAT_INTERFACE
subgraph CHAT
chatinterface(Talk to EDA GPT) -- user-asks-question --> Q&A[Q&A Interface runs] --> function(pandasaichattool)
function(pandasaichattool) -- create-stuff-docs-chain-creates-request --> vstore[(VectorEmbeddings)]
end
end
subgraph CODE CORRECTOR
error&query[Combine Error And Query]--into prompt-->correctorllm(SMARTLLMCHAIN)-->method[Chain OF Thoughts]
method[Chain OF Thoughts]-->corrected(LLM CORRECTION)
end
subgraph OUTPUT_CLASSIFIER
result(LLM ANSWER)--->Clf(Classification Model)
models(Models: Random Forest, Naive Bayes)
Clf(Classification Model)--label:sentence-->sentence(display result)
Clf(Classification Model)--label:code-->code(code parser)-->codeformatter(CODE-FORMATTER)
corrected(LLM CORRECTION)-->code(code parser)
end
subgraph CODE PARSER
codeformatter(CODE-FORMATTER)--formats code-->exe(Executor)--no error-->output(returns code + output)-->display(display code
result)
exe(Executor)--error-->error(if Error)-->error&query[Combine Error And Query]
end
- Unstructured Data EDA
graph TB
subgraph UNSTRUCTURED-DATA-ANALYZER
pdf(UPLOAD PDF) --> checkpdf(pdf content check)
image(UPLOAD IMAGE) --> checkimg(image content check)
checkpdf & checkimg -- |if Valid content| --> embeddings(make-vector embeddings)
detail[Deals With Unstructured Data]
end
subgraph VectorStore
vstore[(VectorEmbeddings)]
includes([FAISS vstore])
end
subgraph CALLING-LLM-LLMCHAIN
prompttemplate(prompts)-->docschain(create-stuff-docs-chain)
llm(llm choice)-->docschain(create-stuff-docs-chain)
chat_history(chat history)-->docschain(create-stuff-docs-chain)
vstore[(VectorEmbeddings)] -- returns embeddings --> retriever(embeddings as-retriever) -->retrieverchain(retriever-chain--->retrieves vstore embeddings)
multiquery([MultiQuery Retriever--> generates diverse questions for retrieval])-->retrieverchain
docschain(create-stuff-docs-chain)-->retrieverchain(retriever-chain--->retrieves vstore embeddings) --> Chain(chain-->chain.invoke) --> result(LLM ANSWER)
end
subgraph VSTORE-INTERNALS
embeddings(make-vector embeddings)--|check for structured data|-->infer-structure([INFER TABLE STRUCTURE if present])--save_too-->docs(DOCUMENT STORE)
docs(DOCUMENT STORE)--preprocess-->preprocessing([splitting,chunking,infer tables, structure in text data])
preprocessing--embeddings-->embed&save(save to vstore)--save-->vstore[(VectorEmbeddings)]
end
subgraph EDAGPT-CHAT_INTERFACE
subgraph CHAT
chatinterface(Talk to DATA) -- user-asks-question --> Q&A[Q&A Interface runs] --> clf(Classification Model)--|user-question|-->models
subgraph MultiClassModels
models(Models: Random Forest, Naive Bayes)--class-->analysis[Analysis]
models(Models: Random Forest, Naive Bayes)--class-->vision[Vision]
models(Models: Random Forest, Naive Bayes)--class-->search[Search]
end
end
subgraph Analysis
analysis[Analysis]-->datanalyst([ANSWERS QUESTION FROM DOCS])
datanalyst--requests-->vstore-->docschain(create-stuff-docs-chain)
end
subgraph Vision
vision[Vision]-->multimodal-LLM(MultiModal-LLM)-->result
end
subgraph SearchAgent
search[Search]-->multimodalsearch[Multimodal-Search Agent]-->agents
end
end
subgraph Agents
agents-->funcs{Capabilities}
subgraph features
funcs-->internet([Search Internet])-->services([Duckduckgo, Tavily, Google])
funcs-->scrape([scraper])
funcs-->findocs([Utilize Docs])-->datanalyst
funcs-->visioncapabilities([Utilize Vision])-->vision
end
subgraph Combine
internet & scrape & findocs & visioncapabilities --> combine([Combine Results])
combine([Combine Results])-->working[Utilizes various Permutation And Combination Of Tools based on Though/Action/Observation]-->result
end
end
-
FAISS Uses Inverted File Based indexing strategy to index the embeddings which is suitable for datasets ranging from 10MB to around 2GB. For higher memory demanding datasets, graph based indexing , hybrid indexing or disk indexing can be used. For most day-to-day purposes FAISS is a good choice.
-
Chroma database is used for comparatively larger files with more text corpus (example : pdf of 130 pages). It uses Hierarchical Navigable Samll World algorithm for indexing which is good for knn algorithm while performing similarity search.
-
EDA GPT is optimized for maximal parallel processing. It embeds a huge list of documents and adds them to chroma parallelly.
-
It is heavily optimized for searching internet, documents and creating analysis reports from structured and unstructured data.
-
Advanced retrieval techniques like multiquery retrieval, emsemble retrieval combined with similarity search with a high threshold is used to get useful documents.
-
A large language model with high context window like gemini-pro-1.5 works best for large volumes of data. Since llms have a limit for context, it is not recommended to feed humungous amount of data in one go. We recommend to divide a huge pdf into smaller pdfs if possible and process independent data in one session. For example a pdf of 1000 pages with over 5 * 10^6 words should be divided for efficiency.
-
data is cached at every point for faster inference.
- link to notebook: https://colab.research.google.com/drive/1vqMTPWeSlF7iYG06PFkrYw9lxcnrrmaE?usp=sharing#scrollTo=9dzFcTeY53eG
For Indepth Understanding Of The Application Check Out Check out the Low Level Design documentation as markdown and High Level Design pdf
To use this app, follow these steps:
-
Clone the repository:
git clone https://github.com/shaunthecomputerscientist/EDA-GPT.git cd EDA-GPT -
Make a virtual environment and install dependencies:
pip install -r requirements.txt
-
Set Up secrets.toml inside .streamlit folder:
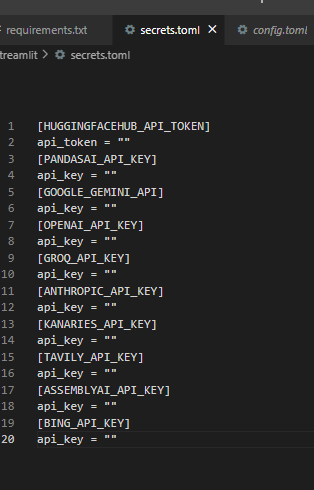
-
Start the app:
streamlit run Home.py

We value your feedback and are constantly working to improve EDA GPT. If you encounter any issues or have suggestions for improvement, please don't hesitate to reach out to our support team. developer contact : mrpolymathematica@gmail.com