This work is from Jeju Machine Learning Camp 2017
- Co-author: Mark Kwon (hjkwon0609@gmail.com)
- Final work will be done in Jeju ML Camp. Please check here.
- Take a look at the demo!
Recently, deep neural networks have been used in numerous fields and improved quality of many tasks in the fields. Applying deep neural nets to MIR(Music Information Retrieval) tasks also provided us quantum performance improvement. Music source separation is a kind of task for separating voice from music such as pop music. In this project, I implement a deep neural network model for music source separation in Tensorflow.
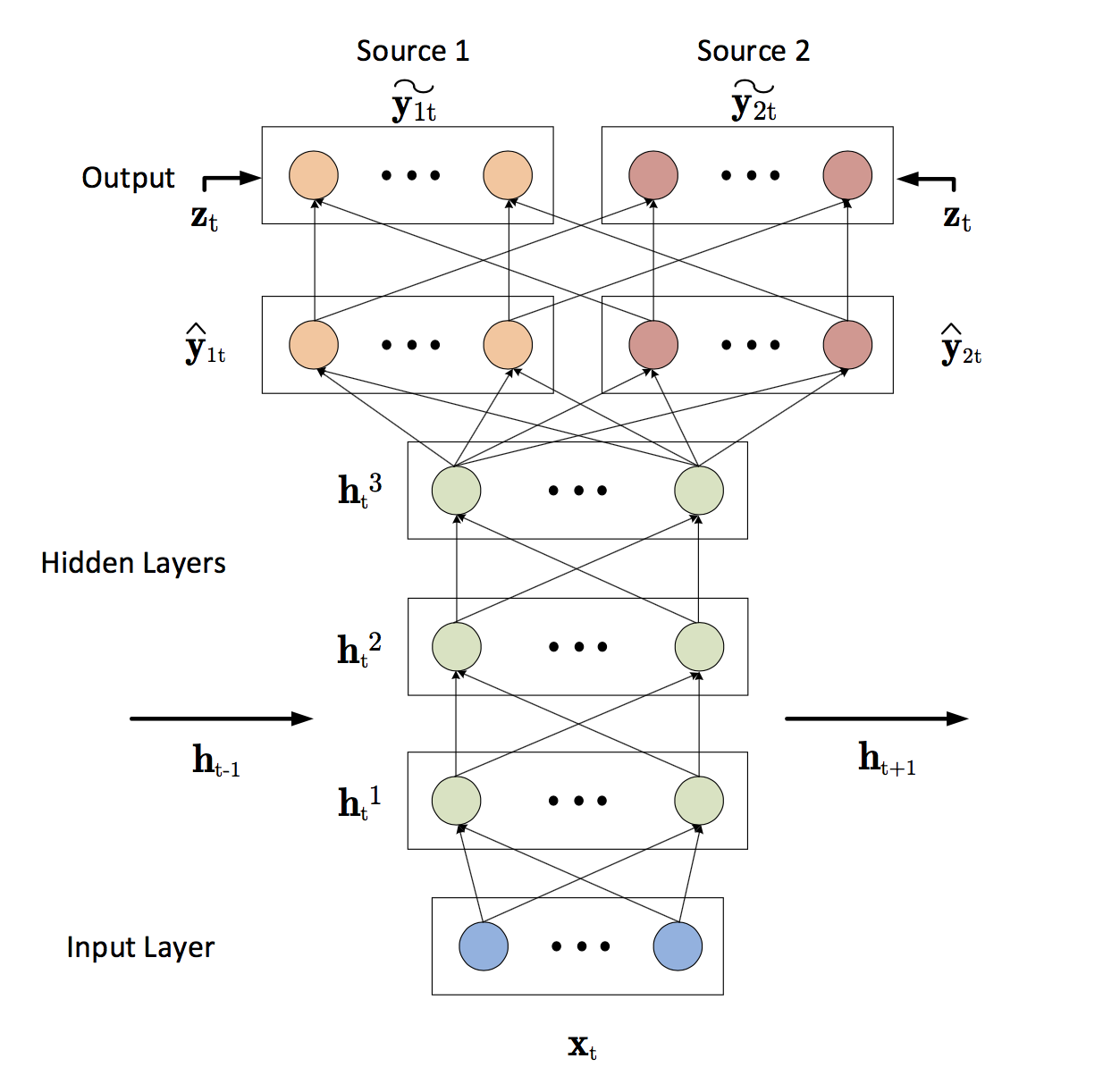
- I used Posen's deep recurrent neural network(RNN) model [2, 3].
- 3 RNN layers + 2 dense layer + 2 time-frequency masking layer
- I used iKala dataset introduced by [1] and MIR-1K dataset which is public together when training.
- Numpy >= 1.3.0
- TensorFlow == 1.2
- librosa == 0.5.1
- Configuration
- config.py: set dataset path appropriately.
- Training
python train.py- check the loss graph in Tensorboard.
- Evaluation
python eval.py- check the result in Tensorboard (audio tab).
[Related Paper] Singing-Voice Separation From Monaural Recordings Using Deep Recurrent Neural Networks (2014) [3]
- Waveform of a music(the mixture of voice and background music) is transformed to magnitude and phase spectra by Short-Time Fourier Transformation(STFT).
- Only magnitude spectra are processed as input of the RNN layer.
- Estimated magnitude spectra of each sources and phase spectra of the mixture are transformed to waveform of each sources by ISTFT(inverse STFT).
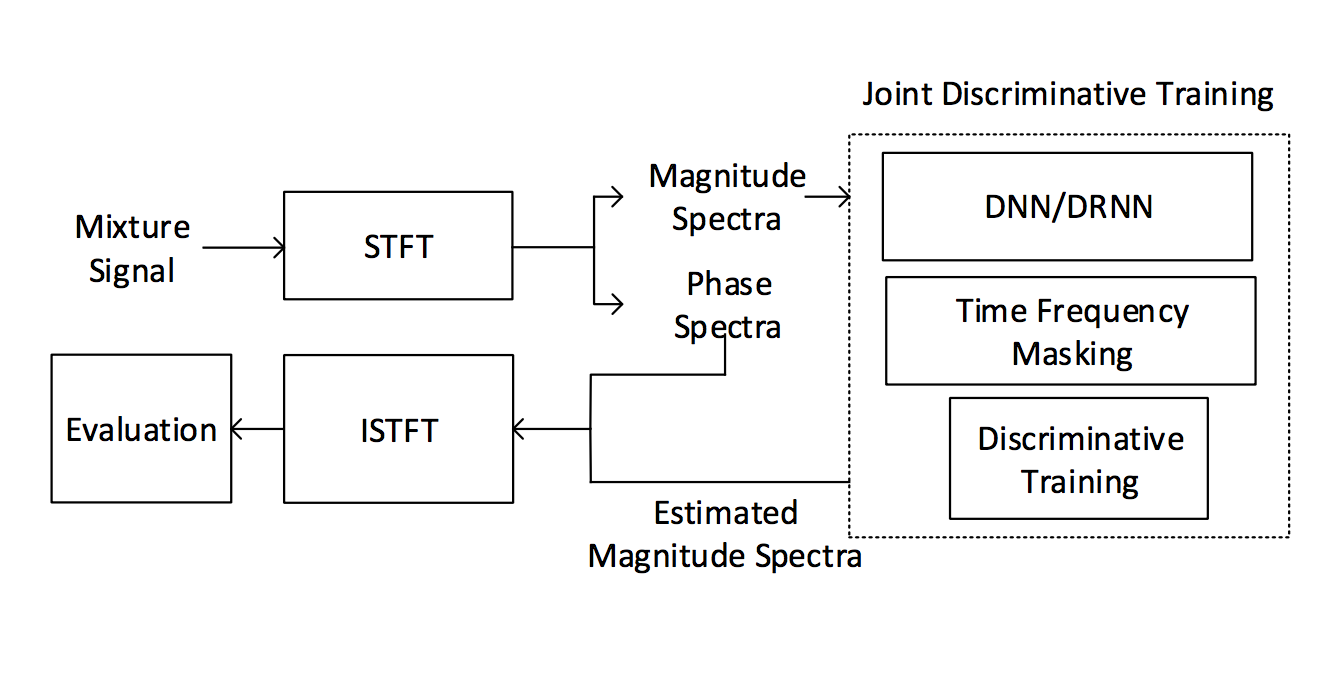
- RNN layers (3 layers)
- Dense layer
- 1 for each source
- Time-frequency masking layer (normalization)
- 1 for each source
- no non-linearity
- src1's magnitude + src2's magnitude = input's magnitude
- Mean squared error(MSE) or KL divergence between estimated magnitude and ground true are used as the loss function.
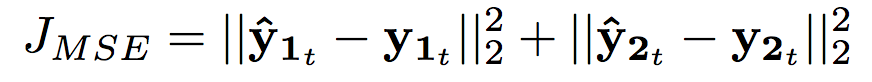
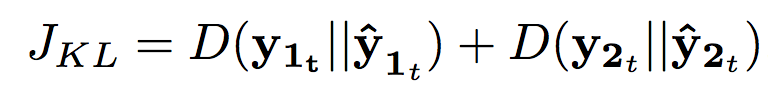
- Further, to prevent different sources to get similar each other, 'discrimination' term is considered additionally.
- The discrimination weight(r) should be carefully chosen because it causes ignoring the first term when training(large r (e.g. r >= 1) makes the result bad)
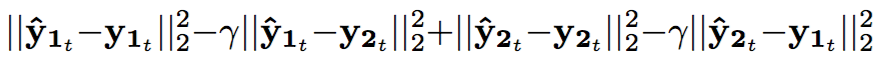
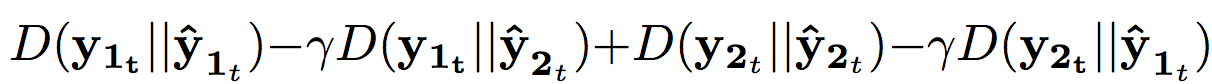
- MIR-1K dataset is used.
- 1000 song clip with a sample rate of 16KHz, with duration from 4 to 13 secs.
- extracted from 110 Karaoke songs performed by both male and female amateurs.
- singing voice and background music in different channels.
- Data augmentation
- circularly shift the singing voice and mix them with the background music.
- 1024 points STFT with 50% overlap (hop size=512 points)
- L-BFGS optimizer rather than gradient decent optimizers
- Concatenating neighboring 1 frame
- To enrich context, previous and next frames are concatenated to current frame.
- BSS-EVAL 3.0 metrics are used.
- (v' = estimated voice, v = ground truth voice, m = ground truth music, x = the mixture)
- Source to Distortion Ratio (SDR) or GSDR(length weighted)
- SDR(v) = how similar v' with v?
- Source to Interferences Ratio (SIR) or GSIR(length weighted)
- SIR(v) = how discriminative v' with m?
- Sources to Artifacts Ratio (SAR) or GSAR(length weighted)
- NSDR(Normalized SDR) or GNSDR(length weighted)
- SDR improvement between the estimated voice and the mixture.
- SDR(v', v) - SDR(x, v)
- Source to Distortion Ratio (SDR) or GSDR(length weighted)
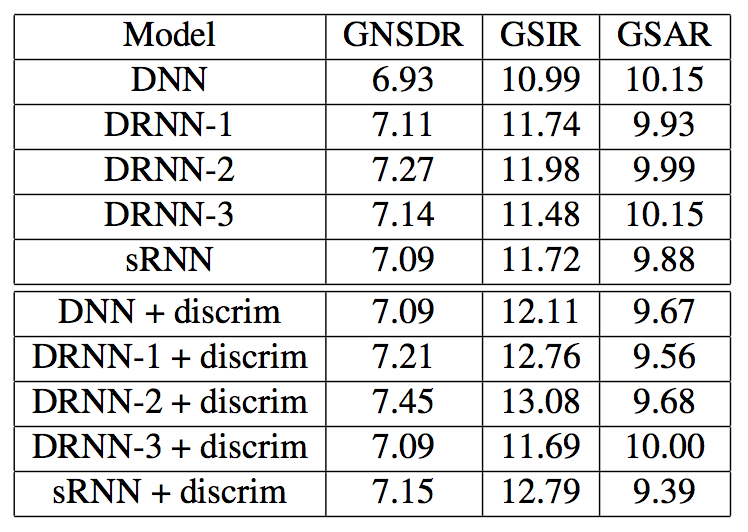
- The proposed neural network models achieve 2.30-2.48 dB GNSDR gain, 4.32-5.42 dB GSIR gain with similar GSAR performance, compared with conventional approaches. (quantum jump!!!)
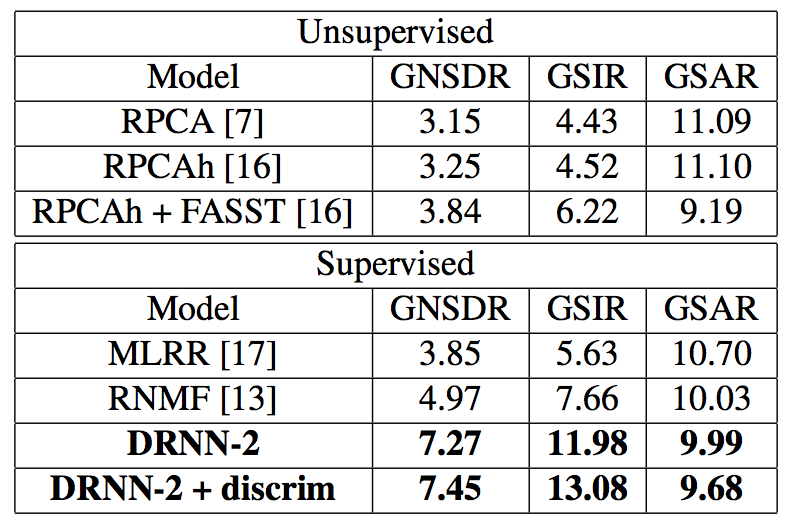
- Concatenating neighboring 1 frame provides better results. We can make a assumption that more sufficient information than single frame provides more hint to the neural net.
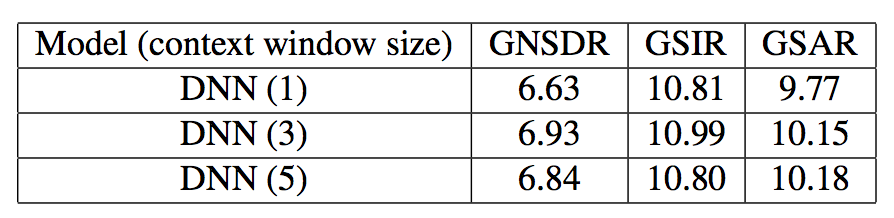
- The RNN-based models, in fact, do not make any plausible improvement comparing with DNN. But discriminative training with carefully chosen weight(r) provides a bit better performance in the experiments.
- A visualization of magnitude spectrogram (in log scale) for the mixture, voice, and background music.

- Some transformation methods are applied to enrich the information for each frame
- Instead of Posen's approach(simply concatenate previous-k and subsequent-k frames)
- Vector Product Neural Network(VPNN) proposed by [4] is used.
- In VPNN, the input data, weights, and biases are all three-dimensional vectors
- each elements(vectors) are operated by cross product of vectors.
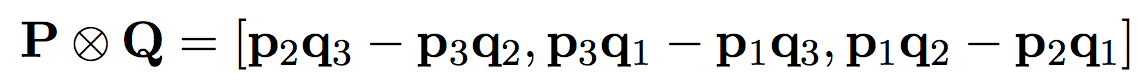
- previous, current, and subsequent frame as 3-dimensional vector
- take only second value(current frame) as output in 3-dimensional output vector
- Transformation the magnitude to RGB colored value (3-dimensional vector)
- x is the magnitude of each t-f unit,
- n a scalar to bias the generation of RGB values.
- empirically set n to 0.0938 in this work.
![]()
- MSE loss is used like Posen's work.
- iKala dataset is used.
- 252 30-second excerpts sampled from 206 iKala songs
- 63 training clips and 189 testing clips.
- All clips are downsampled to 16000 Hz.
- 1024-point window and a 256-point hop size.
- VPNN of 3-layers and 512 units each layer.
- time frequency masking applied.
GNSDR, GSIR, GSAR are used.
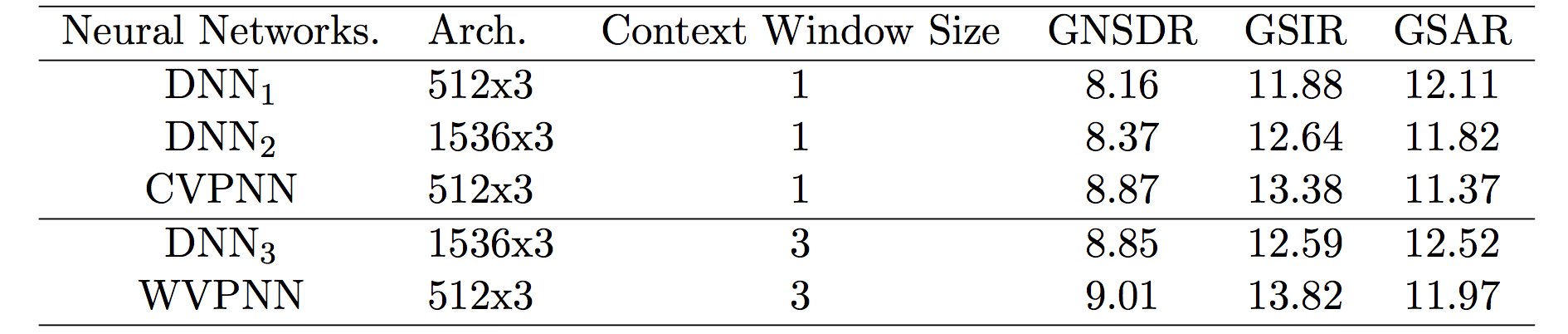
- CVPNN and WVPNN performs better than DNNs which have same size of weights.
- Zhe-Cheng Fan, Tak-Shing T. Chan, Yi-Hsuan Yang, and Jyh-Shing R. Jang, "Music Signal Processing Using Vector Product Neural Networks", Proc. of the First Int. Workshop on Deep Learning and Music joint with IJCNN, May, 2017
- P.-S. Huang, M. Kim, M. Hasegawa-Johnson, P. Smaragdis, "Joint Optimization of Masks and Deep Recurrent Neural Networks for Monaural Source Separation", IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23, no. 12, pp. 2136–2147, Dec. 2015
- P.-S. Huang, M. Kim, M. Hasegawa-Johnson, P. Smaragdis, "Singing-Voice Separation From Monaural Recordings Using Deep Recurrent Neural Networks" in International Society for Music Information Retrieval Conference (ISMIR) 2014.
- Tohru Nitta, "A backpropagation algorithm for neural networks based an 3D vector product. In Proc. IJCNN", Proc. of IJCAI, 2007.