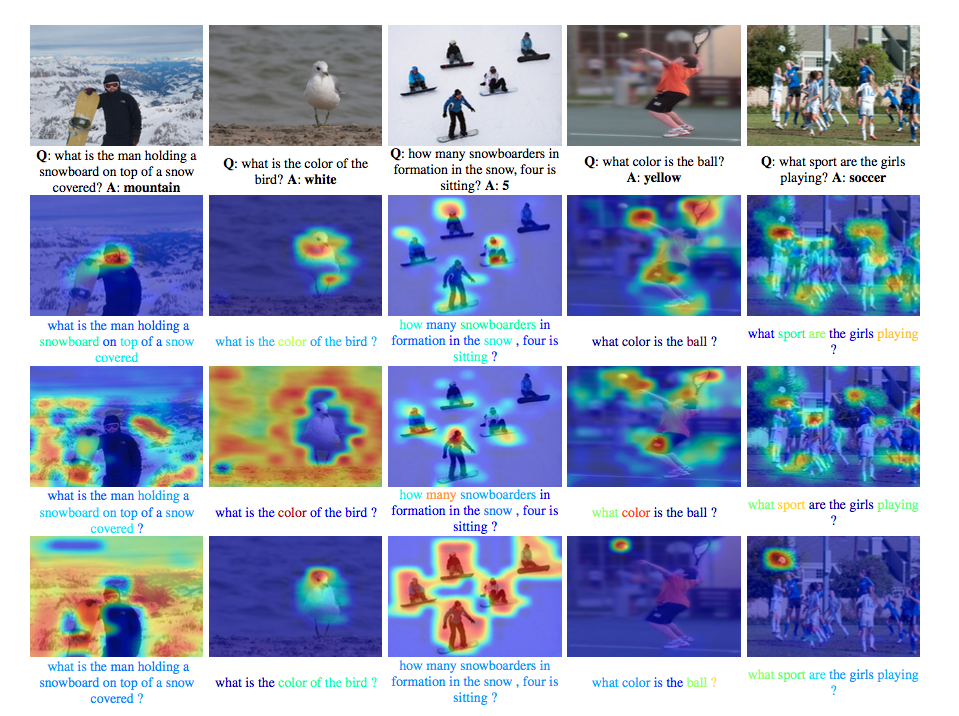
Train a Hierarchical Co-Attention model for Visual Question Answering. This current code can get 62.1 on Open-Ended and 66.1 on Multiple-Choice on test-standard split. For COCO-QA, this code can get 65.4 on Accuracy. For more information, please refer the paper https://arxiv.org/abs/1606.00061
This code is written in Lua and requires Torch. The preprocssinng code is in Python, and you need to install NLTK if you want to use NLTK to tokenize the question.
You also need to install the following package in order to sucessfully run the code.
We have prepared everything for you ;)
The first thing you need to do is to download the data and do some preprocessing. Head over to the data/ folder and run
For VQA:
$ python vqa_preprocess.py --download 1 --split 1
--download Ture means you choose to download the VQA data from the VQA website and --split 1 means you use COCO train set to train and validation set to evaluation. --split 2 means you use COCO train+val set to train and test set to evaluate. After this step, it will generate two files under the data folder. vqa_raw_train.json and vqa_raw_test.json
For COCO-QA
$ python vqa_preprocess.py --download 1
This will download the COCO-QA dataset from here and generate two files under the data folder. cocoqa_raw_train.json and cocoqa_raw_test.json
Here we use VGG_ILSVRC_19_layers model and Deep Residual network implement by Facebook model.
Head over to the image_model folder and run
$ python download_model.py --download 'VGG'
This will download the VGG_ILSVRC_19_layers model under image_model folder. To download the Deep Residual Model, you need to change the VGG to Residual.
Head over to the prepro folder and run
For VQA:
$ python prepro_vqa.py --input_train_json ../data/vqa_raw_train.json --input_test_json ../data/vqa_raw_test.json --num_ans 1000
to get the question features. --num_ans specifiy how many top answers you want to use during training. You will also see some question and answer statistics in the terminal output. This will generate two files in data/ folder, vqa_data_prepro.h5 and vqa_data_prepro.json.
For COCO-QA
$ python prepro_cocoqa.py --input_train_json ../data/cocoqa_raw_train.json --input_test_json ../data/cocoqa_raw_test.json
COCO-QA use all the answers in train, so there is no --num_ans option. This will generate two files in data/ folder, cocoqa_data_prepro.h5 and cocoqa_data_prepro.json.
Then we are ready to extract the image features.
For VGG image feature:
$ th prepro_img_vgg.lua -input_json ../data/vqa_data_prepro.json -image_root /home/jiasenlu/data/ -cnn_proto ../image_model/VGG_ILSVRC_19_layers_deploy.prototxt -cnn_model ../image_model/VGG_ILSVRC_19_layers.caffemodel
you can change the -gpuid, -backend and -batch_size based on your gpu.
For Deep Residual image feature:
We have everything ready to train the VQA and COCO-QA model. Back to the main folder
th train.lua -input_img_train_h5 data/vqa_data_img_vgg_train.h5 -input_img_test_h5 data/vqa_data_img_vgg_test.h5 -input_ques_h5 data/vqa_data_prepro.h5 -input_json data/vqa_data_prepro.json -co_atten_type Alternating -feature_type VGG
to train Alternating co-attention model on VQA using VGG image feature. You can train the Parallel co-attention by setting -co_atten_type Parallel. The prallel co-attention usually takes more time than alternating co-attention.
- Deep Residual Image Feature is 4 times larger than VGG feature, make sure you have enough RAM when you extract or load the features.
- If you didn't have large RAM, replace the
require 'misc.DataLoader'(Line 11 intrain.lua) withrequire 'misc.DataLoaderDisk. The model will read the data directly from the hard disk (SSD prefered)
The pre-trained model can be download here Note, if you use the vqa train model, you should use the corresponding json file form here
if you use the vqa train+val model, you should use the corresponding json file form here
To Evaluate VQA, you need to download the VQA evaluation tool. To evaluate COCO-QA, you can use script evaluate_cocoqa.py under metric/ folder. If you need to evaluate based on WUPS, download the evaluation script from here
We use iTorch to demo the visual question answering with pre-trained model. The script only does the basic tokenize, and please make sure the question is all lowercase, and split by "space".(it's better use NLTK to tokenize and transform the question, you can check the prepro.py for more details.)
In the root folder, open itorch notebook, then you can load any image and ask question using the itorch notebook.
Some of the data file can be download at here
If you use this code as part of any published research, please acknowledge the following paper
@misc{Lu2016Hie,
author = {Lu, Jiasen and Yang, Jianwei and Batra, Dhruv and Parikh, Devi},
title = {Hierarchical Question-Image Co-Attention for Visual Question Answering},
journal = {arXiv preprint arXiv:1606.00061v2},
year = {2016}
}