🌾 9th Place Solution of Global Wheat Detection

- Our team: Miras Amir, Or Katz, Shlomo Kashani
- Kaggle post
- Submission kernel: pseudo ensemble: detectors (3 st)+universenet r10
Our solution is based on the excellent MMDetection framework. We trained an ensemble of the following models:
To increase the score a single round of pseudo labelling was applied to each model. Additionally, for a much better generalization of our models, we used heavy augmentations.
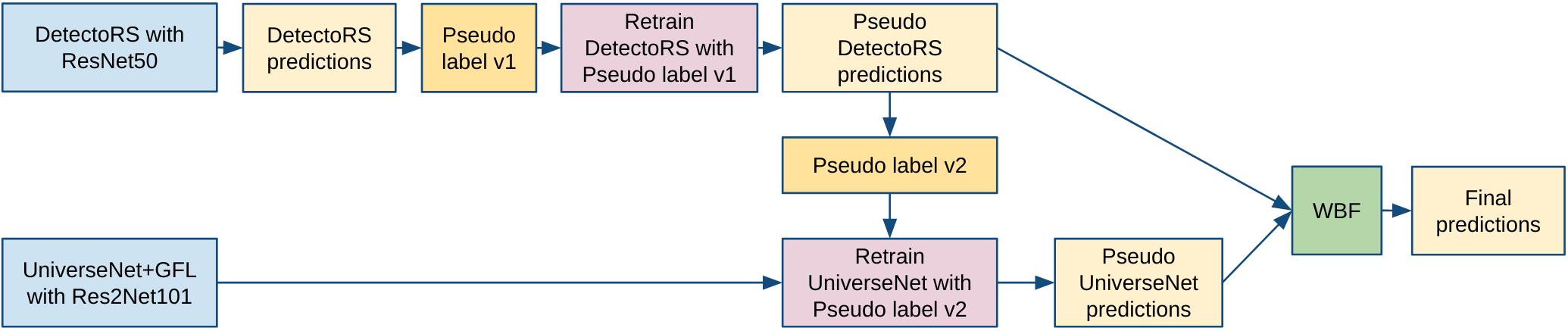
In the original corpus provided by the organizers, the training images were cropped from an original set of larger images. Therefore, we collected and assembled the original puzzles resulting in a corpus of 1330 puzzle images. The puzzle collection algorithm we adopted was based on this code. But we were unsuccessful in collecting the bounding boxes for puzzles. Mainly because of the existence of bounding boxes that are located on or in the vicinity the border of the image. For this reason, we generated crops for the puzzles offline in addition to training images and generated boxes for them using pseudo labelling.
We used MultilabelStratifiedKFold with 5 folds of iterative stratification stratified by the number of boxes, a median of box areas and source of images. We guaranteed that there isn’t any leak between the sub-folds, so that the images of one puzzle were used only in that one particular fold.
Referring to the paper, one can see wheat heads from different sources. We assumed that the wheat heads of usask_1, ethz_1 sources are very different from the test sources (UTokyo_1, UTokyo_2, UQ_1, NAU_1). Therefore, we did not use these sources for validation.
However, our validation scores did not correlate well with the Kaggle LB. We only noticed global improvements (for example, DetectoRS is better than UniverseNet). Local improvements such as augmentation parameters, WBF parameters etc. did not correlate. We, therefore, shifted our attention to the LB scores mainly.
We trained our models only on the first fold.
Due to the relatively small size of our training set, and another test set distribution, our approach relied heavily on data augmentation. During training, we utilized an extensive data augmentation protocol:
- Various augmentations from albumentations:
- HorizontalFlip, ShiftScaleRotate, RandomRotate90
- RandomBrightnessContrast, HueSaturationValue, RGBShift
- RandomGamma
- CLAHE
- Blur, MotionBlur
- GaussNoise
- ImageCompression
- CoarseDropout
- RandomBBoxesSafeCrop. Randomly select N boxes in the image and find their union. Then we cropped the image keeping this unified.
- Image colorization
- Style transfer. A random image from a small test (10 images) was used as a style.
- Mosaic augmentation.
a, b, c, d-- randomly selected images. Then we just do the following:


top = np.concatenate([a, b], axis=1)
bottom = np.concatenate([c, d], axis=1)
result = np.concatenate([top, bottom], axis=0)
- Mixup augmentation.
a, b-- randomly selected images. Then:result = (a + b) / 2 - Multi-scale Training. In each iteration, the scale of image is randomly sampled from
[(768 + 32 * i, 768 + 32 * i) for i in range(25)]. - All augmentations except colorization and style transfer were applied online. Examples of augmented images:
 |
 |
|---|---|
 |
 |
We used DetectoRS with ResNet50 and UniverseNet+GFL with Res2Net101 as main models. DetectoRS was a little bit more accurate and however much slower to train than UniverseNet:
- Single DetectoRS Public LB score without pseudo labeling: 0.7592
- Single UniverseNet Public LB score without pseudo labeling: 0.7567
For DetectoRS we used:
- LabelSmoothCrossEntropyLoss with parameter
0.1 - Empirical Attention
In general, we used a multi-stage training pipeline:

We used TTA6 (Test Time Augmentation) for all our models:
- Multi-scale Testing with scales
[(1408, 1408), (1536, 1536)] - Flips:
[original, horizontal, vertical]
For TTA was used a standard MMDet algorithm with NMS that looks like this for two-stage detectors (DetectoRS):
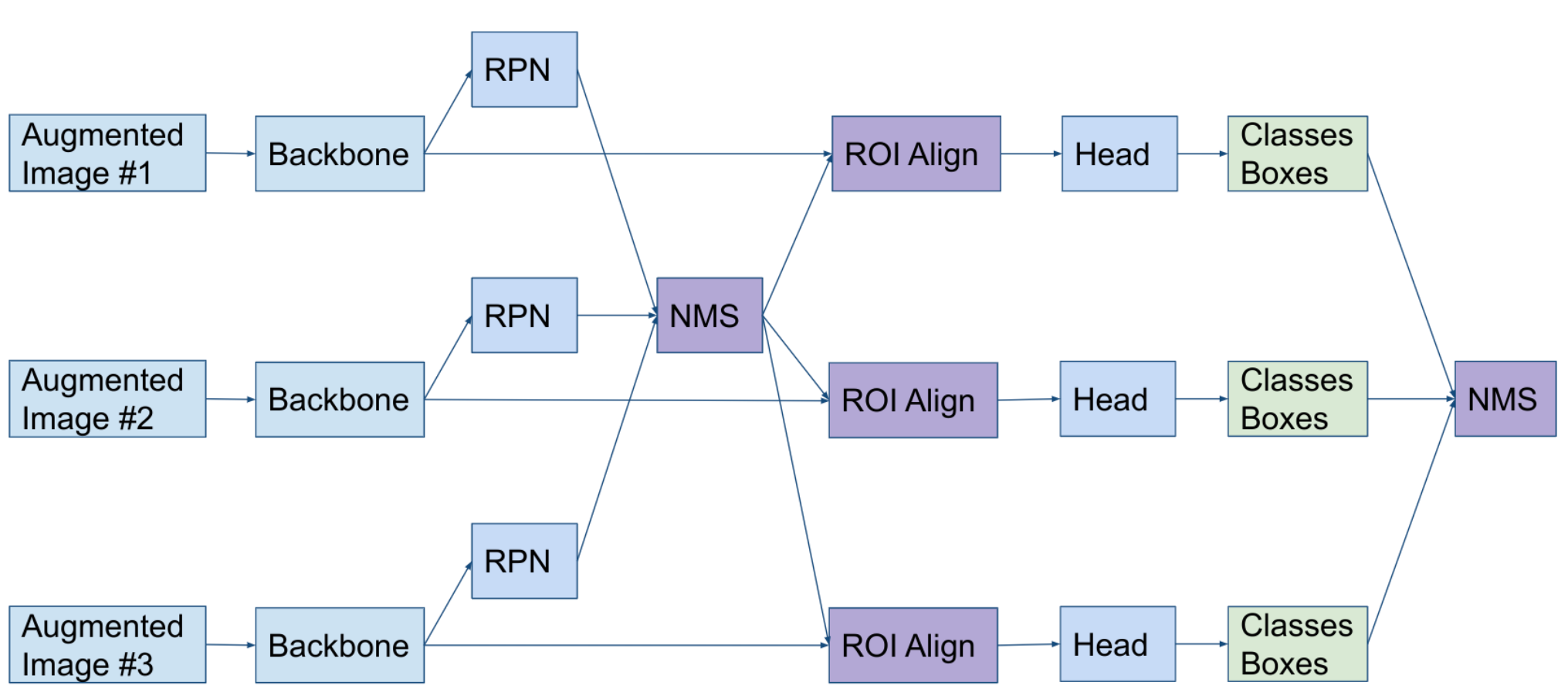
For one-stage detectors (UniverseNet), the algorithm is similar, only without the part with RoiAlign, Head, etc.
- Sampling positive examples. We predicted the test image and received its scores and the bounding boxes. Then we calculated
confidence = np.mean(scores > 0.75). If the confidence was greater than 0.6 we accepted this image and used for pseudo labelling. - Sources
[usask_1, ethz_1]and augmentations like mosaic, mixup, colorization, style transfer weren’t used for pseudo labelling. - 1 epoch, 1 round, 1 stage.
- Data: original data + pseudo test data ✖️ 3
We used WBF for the ensemble. The distribution of DetectoRS and UniverseNet scores is different. So we applied scaling using rankdata:
scaled_scores = 0.5 * (rankdata(scores) / len(scores)) + 0.5.
WBF parameters:
weights=[0.65, 0.35]respectively for models[DetectoRS, UniverseNet]iou_thr=0.55score_thr=0.45
- Final submission: 0.6741 on Private LB and 0.7725 on Public LB
- Pseudo crops from jigsaw puzzles (DetectoRS R50): 0.7513 -> 0.7582
- Tuning of pseudo labeling parameters for sampling positive examples (ensemble): 0.7709 -> 0.7729
- Pseudo labeling (DetectoRS R50): 0.7582 -> 0.7691
- Pseudo labeling (UniverseNet Res2Net50): 0.7494 -> 0.7627
- SPIKE dataset (DetectoRS R50): 0.7582 -> 0.7592
- Deleting [usask1, ethz1] from pseudo labeling (DetectoRS R50): 0.7678 -> 0.7691
/data/
├── train/
│ ├── d47799d91.jpg
│ ├── b57bb71b6.jpg
│ └── ...
├── train.csv
/dumps/
├── decoder.pth # checkpoint for style transfer (https://yadi.sk/d/begkgtQHxLo6kA)
├── vgg_normalised.pth # checkpoint for style transfer (https://yadi.sk/d/4BkKpSZ-4PUHqQ)
├── pix2pix_gen.pth # checkpoint for image colorization (https://yadi.sk/d/E5vAckDoFbuWYA)
└── PL_detectors_r50.pth # checkpoint of DetectoRS, which was trained without pseudo crops from jigsaw puzzles (https://yadi.sk/d/vpy2oXHFKGuMOg).
python gwd/jigsaw/calculate_distance.py
python gwd/jigsaw/collect_images.py
python gwd/jigsaw/collect_bboxes.py
python gwd/split_folds.py
bash scripts/kaggle2coco.sh
python gwd/jigsaw/crop.py
bash scripts/test_crops.sh
python gwd/prepare_pseudo.py
python gwd/converters/spike2kaggle.py
bash scripts/colorization.sh
bash scripts/stylize.sh
bash scripts/train_detectors.sh
bash scripts/train_universenet.sh
It is based on lopuhin/kaggle-script-template.
You must upload the best checkpoints of trained models to the kaggle dataset. Further change the variables in script_template.py:
MODELS_ROOT(name of your kaggle dataset)CHECKPOINT_DETECTORS(the best checkpoint of DetectoRS)CHECKPOINT_UNIVERSE(the best checkpoint of UniverseNet)
bash build.sh # create a submission file ./build/script.py
Link to the kaggle dataset with:
- pretrained weights: gwd_models
- external libraries: mmdetection_wheels
- https://github.com/open-mmlab/mmdetection
- https://github.com/shinya7y/UniverseNet
- https://github.com/lopuhin/kaggle-script-template
- https://github.com/trent-b/iterative-stratification
- https://github.com/albumentations-team/albumentations
- https://github.com/dereyly/mmdet_sota
- https://github.com/eriklindernoren/PyTorch-GAN
- https://github.com/bethgelab/stylize-datasets