



![]() RLA is a tool for managing your RL experiments automatically (e.g., your hyper-parameters, logs, checkpoints, figures, code, etc.).
RLA has decoupled from the training code and only some additional configurations are needed. Before using RLA, we recommend you to read the section "Design Principles of RLA", which will be helpful for you to understand the basic logic of the repo.
RLA is a tool for managing your RL experiments automatically (e.g., your hyper-parameters, logs, checkpoints, figures, code, etc.).
RLA has decoupled from the training code and only some additional configurations are needed. Before using RLA, we recommend you to read the section "Design Principles of RLA", which will be helpful for you to understand the basic logic of the repo.
The project is still in development. Welcome to join us. :)

The core design principle of RLA is regarding all related information of each Experiment As A complex item in a Database (EaaD). We design RLA to manage the experiments dataset by
- formulating, standardizing, and structuring the data items and tables of the "RL experiment database";
- provide tools for adding, deleting, modifying, and querying the items in the database.
The followings are the detailed designs of EaaD and the implementation of RLA.
After integrating RLA into your project, we create a "database" implicitly configured by rla_config.yaml.
Each experiment we run will be indexed and stored as an item into a "table". In particular, RLA includes the following elements to construct an "RL experiment database".
-
Database: A database is configured by a YAML file
rla_config.yaml. In our practice, we only create one database for one research subject. -
Table: We map the concept of Table in standard database systems into the concept of "task" in our research process. There are many similarities between the two concepts. For example, we will create another table/task often when:
- the structures of tables are different, e.g., they have different keys. In the research process, different tasks often have totally different types of logs to record. For example, in offline model-based RL, the first task might pretrain a dynamics model the second task might be policy learning with the learned model. In model learning, we are concerned with the MSE of the model; In policy learning, we are concerned with the rewards of policy.
- The content of a table is too large which might hurt the speed of querying. Table partition is a common solution. In the research process, we need large memory to load a Tensorboard if the logdir has many runs. We can solve the problem by splitting the runs into different sub-directories.
In RLA, we need to assign a "task" for each experiment to run.
-
Data Item: We map the concept of the data item to the complex generated data in an experiment. For each data item, we need to define the index and the value for each item.
- Index: We need a unique index to define the item in a table for item adding, deleting, modifying, and querying. In RLA, we define the index of each experiment as:
datetime of the experiment (for uniqueness) + ip address (for keeping uniqueness in distributed training) + tracked hyper-parameters (easy to identify and easy to search). - Value: when running an experiment, we generate many data with different structures. Based on our research practice, currently, we formulate the following data for each experiment
- Codes and hyper-parameters: Every line of the code and select hyper-parameters to run the experiment. This is a backup for experiment reproducibility.
- Recorded variables: We often record many intermediate variables in the process of the experiment, e.g., the rewards, some losses, or learning rates. We record the variables in the key-value formulation and store them in a tensorboard event and a CSV file.
- Model checkpoints: We support weight saving of neural networks and related custom variables in Tensorflow and Pytorch framework. We can use the checkpoints to resume experiments or use the results of the experiment to complete downstream tasks.
- Other data like figures or videos: We might plot the frame-to-frame video of your agent behavior or some curves to check the process of training. We give some common tools in the RL scenario to generate the related variables and store them in the directory.
- Temporary data: For some training paradigms, we might need to store some data to the disks, e.g., large-scale replay buffers, which need to be independently maintained for each experiment.
- Index: We need a unique index to define the item in a table for item adding, deleting, modifying, and querying. In RLA, we define the index of each experiment as:
Currently, we store the data items in standard file systems and manage the relationships among data items, tables, and databases via a predefined directory structure.
After running some experiments, the database will be something like this:

Here we construct a database in "example/sb_ppo_example/". We hold different types of the Value in different folder:
- The directory "archive_tester" is to store hyper-parameters and related variables for experiment resuming.
- The directory "results" is to store other data like figures or videos.
- The directory "log" is to store recorded variables.
- The directory "code" is a backup of the code and hyper-parameters for experiment reproducibility.
- The directory "checkpoint" save weights of neural networks.
- The directory "tmp_data" is to store other temporary data.
The experiment data are stored in the above folders
with the same "structured names" based on the formulation of {$task_table_name}${%Y}/${%m}/${%d}/${%H-%M-%S-%f}_${ip address}_${tracked hyper-parameters},
where {$task_table_name} is a customized string to explain the purpose of the experiments in this "task table", which is the root of the experiments (demo_task in the figure),
${%Y}/${%m}/${%d}/${%H-%M-%S-%f} records the timestamp of the created experiment, ${ip address} records the machine that creates the experiment, and ${tracked hyper-parameters} are some auto-generated hyper-parameters to explain the features of the experiments.
In standard database systems, the commonly used operations to manage a database are adding, deleting modifying, and querying. We also give similar tools to manage the RLA database.
Adding:
- RLA.exp_manager is a global object to create experiments and manger the data in the process of experiments.
- RLA.logger is a module to add recorded variables.
- RLA.MatplotlibRecorder and RLA.ImgRecorder are modules to construct other data like figures.
Deleting:
- rla_scripts.delete_exp.py: a tool to delete experiment data by regex;
Modifying:
- resume: RLA.ExperimentLoader: a class to resume an experiment with different flexible settings.
Querying:
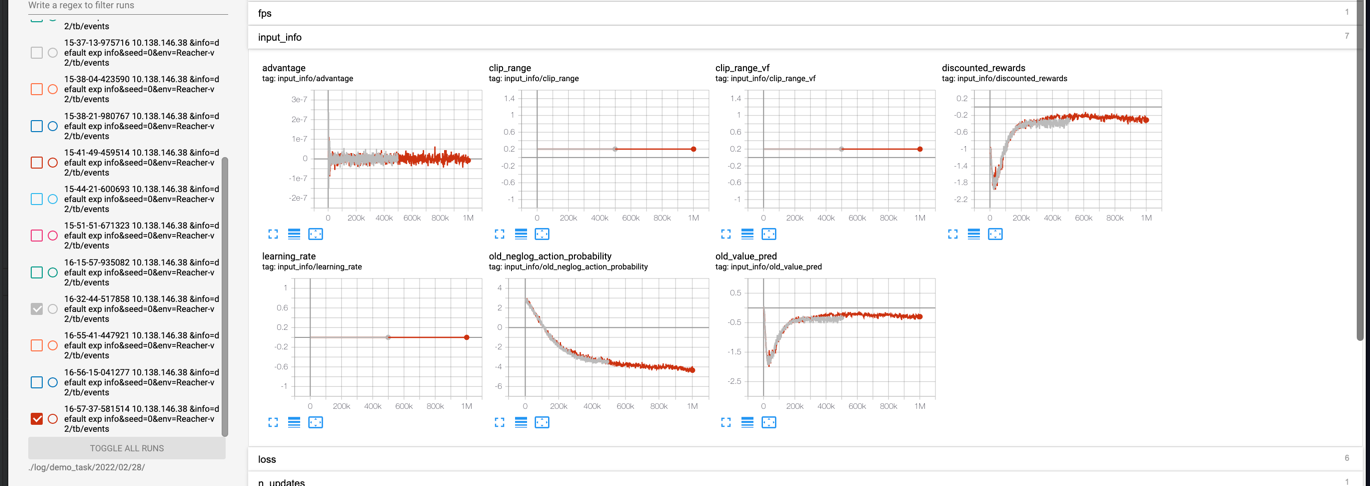
- tensorboard: the recorded variables are added to tensorboard events and can be loaded via standard tensorboard tools.
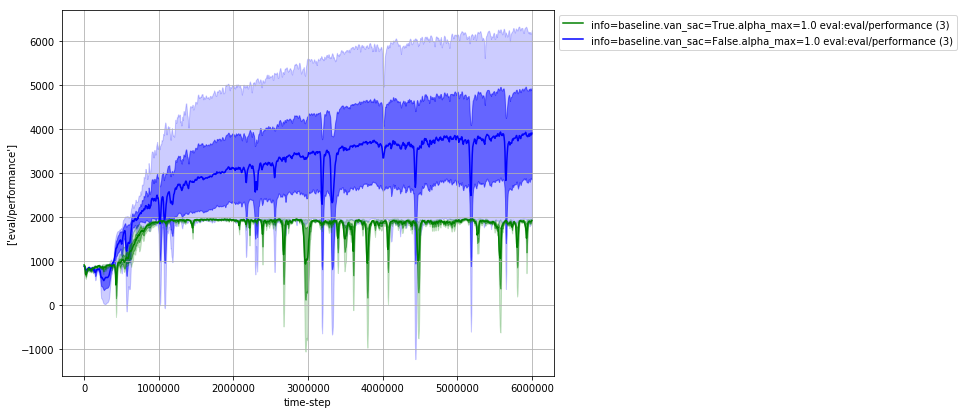
- easy_plot: We give some APIs to load and visualize the data in CSV files. The results will be something like this:
from RLA.easy_plot.plot_func_v2 import plot_func data_root='your_project' task = 'sac_test' regs = [ '2022/03/01/21-[12]*' ] _ = plot_func(data_root=data_root, task_table_name=task, regs=regs , split_keys=['info', 'van_sac', 'alpha_max'], metrics=['perf/rewards'])


Backup:
- rla_scripts.archive_expt.py: a tool to archive experiment data by regex;
- rla_scripts.migrate_expt.py: a tool to move experiment data by regex.
The second design principle is easy to integrate. We give several example projects integrating with RLA in the directory example.
- PPO with RLA based on the stable_baselines (tensorflow): example/sb_ppo_example
- PPO with RL based on the stable_baselines3 (pytorch): example/sb3_ppo_example
We also list the RL research projects using RLA as follows:
git clone https://github.com/polixir/RLAssistant.git
cd RLAssistant
pip install -e .
We build an example project to include most of the features of RLA, which can be seen in ./example/simplest_code. Now we summarize the steps to use it.
-
To configure the experiment "database", you need to create a YAML file rla_config.yaml. You can use the template provided in ./example/simplest_code/rla_config.yaml as a starting point.
-
Before starting your experiment, you should configure the RLA.exp_manager object. Here's an example:
from RLA import exp_manager import os kwargs = {'env_id': 'Hopper-v2', 'lr': 1e-3} debug = False # Set hyperparameters for your experiment exp_manager.set_hyper_param(**kwargs) # Add parts of hyperparameters to name the index of data items for better readability exp_manager.add_record_param(["env_id"]) # To keep the conciseness of your experiment "database", we recommend creating an additional task table for debugging. # When debugging a new feature, set the `debug` value to True, then the recorded experiments will be stored in a temporary location (`demo_task_debug` in this example), instead of mixing into your formal experiment "database". if debug: task_table_name = 'demo_task_debug' # Define a task for debug else: task_table_name = 'demo_task_v1' # Define a task for training def get_package_path(): return os.path.dirname(os.path.abspath(__file__)) rla_data_root = get_package_path() # Set the place to store the data items rla_config = os.path.join(get_package_path(), 'rla_config.yaml') ignore_file_path = os.path.join(get_package_path(), '.gitignore') # Configure the exp_manager object with the specified settings exp_manager.configure(task_table_name=task_table_name, ignore_file_path=ignore_file_path, rla_config=rla_config, data_root=rla_data_root) exp_manager.log_files_gen() # Initialize the data items exp_manager.print_args()
Note that ignore_file_path is a gitignore-style file used to ignore files when backing up your project into the code folder. It is an optional parameter, and you can use your project's .gitignore file directly.
-
Add the generated data items to your .gitignore file to avoid pushing them into your Git repository:
**/tmp_data/** **/archive_tester/** **/checkpoint/** **/code/** **/results/** **/log/** **/arc/**
Record intermediate scalars
We record scalars by RLA.logger:
# Import the RLA logger to record scalars
from RLA import logger
# Import TensorFlow for creating summary data to log
import tensorflow as tf
# Import the time step holder, holding a global instance that tracks the current time step
from RLA import time_step_holder
# Iterate for 1000 time steps (or any number of time steps/epochs)
for i in range(1000):
# Update the time step holder with the current time step (iteration/epoch/whatever you need) value.
# You just need to set the value once when it is changed.
time_step_holder.set_time(i)
# Set the scalar value to record
value = 1
# Record the scalar value using the RLA logger, with "k" as the key and the global time step instance in time_step_holder as the step value.
# This allows you to track the value of the scalar over time (e.g. during training).
logger.record_tabular("k", value)
# Optionally, create a TensorFlow summary for the scalar value (this can be used for additional analysis or visualization).
summary = tf.Summary()
# Log the summary data to the RLA logger.
# This adds the scalar value to the log, along with any additional summary data (if present).
logger.log_from_tf_summary(summary)
# Dump the tabular data to the logger for storage and display.
# This saves the logged data to disk (or other storage location) and displays it in the console (if desired).
logger.dump_tabular()
Record checkpoints
In order to save checkpoints of neural networks in your experiment, you can use the exp_manager.save_checkpoint method. Here's an example code snippet:
from RLA import exp_manager
exp_manager.new_saver()
for i in range(1000):
if i % 10 == 0:
exp_manager.save_checkpoint()This code creates a new saver object and saves a checkpoint every 10 iterations of the loop.
Record other types of data
Apart from recording checkpoints, RLA also provides support for recording other types of data. Currently, you can record complex-structured data using tensorboard. Here's an example code snippet:
import tensorflow as tf
from RLA import logger
# Record data from tensorflow summary
summary = tf.Summary()
logger.log_from_tf_summary(summary)
# Record data using tensorboardX writer
kwargs = {'tag': 'aa'}
logger.get_tbx_writer().add_audio(**kwargs)In the future, RLA plans to develop APIs to record commonly-used complex-structured data in RLA.easy_log.complex_data_recorder.
In addition, RLA also provides the MatplotlibRecorder tool to manage your figures generated by Matplotlib. Here's an example code snippet:
from RLA import MatplotlibRecorder as mpr
def plot_func():
import matplotlib.pyplot as plt
plt.plot([1,1,1], [2,2,2])
mpr.pretty_plot_wrapper('func', plot_func, xlabel='x', ylabel='y', title='react test', )This code plots a figure using Matplotlib and saves it in the "results" directory.
The methods to handle the experiments can be split into the following modules:
Currently, we develop the query tools based on two common scenarios: result visualization and experiment review.
Result visualization:
- Tensorboard: We can use tensorboard/tensorboardX to view the recorded logs. The event of tensorboard will be saved in
${data_root}/log/${task_name}/${index_name}/tb/events. We can view the results in tensorboard by:tensorboard --logdir ${data_root}/log/${task_name}. For example, lanuch tensorboard bytensorboard --logdir ./example/simplest_code/log/demo_task/2022/03. The resulting visualization will look like this: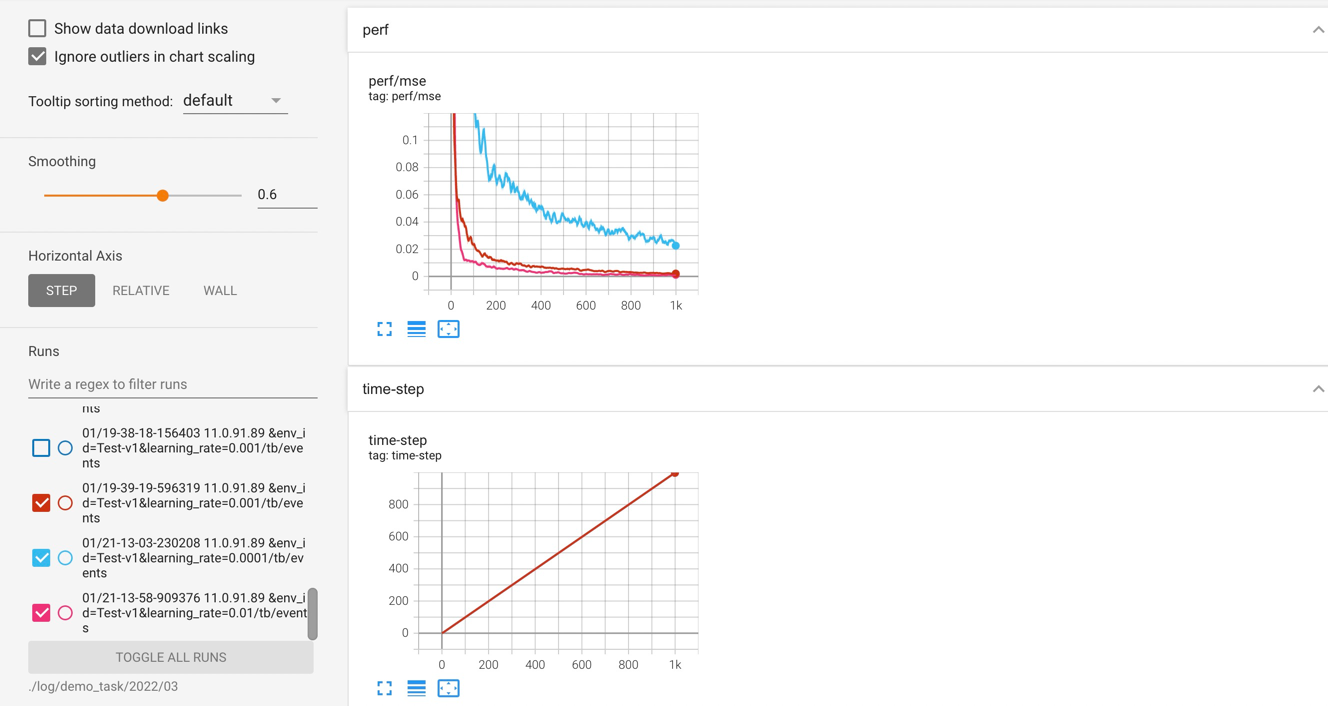
- Easy_plot toolkit: We recommend using Jupyter notebooks to maintain your research projects, where you can record your ideas, surmises, related empirical evidence, and benchmark results together. We provide high-level APIs to load the CSV files of the experiments (stored in ${data_root}/log/${task_name}/${index_name}/progress.csv) and group the curves by custom keys. We have provided common use cases of the plotter in https://github.com/xionghuichen/RLAssistant/blob/main/test/test_plot.ipynb .
The resulting visualization will look like this:
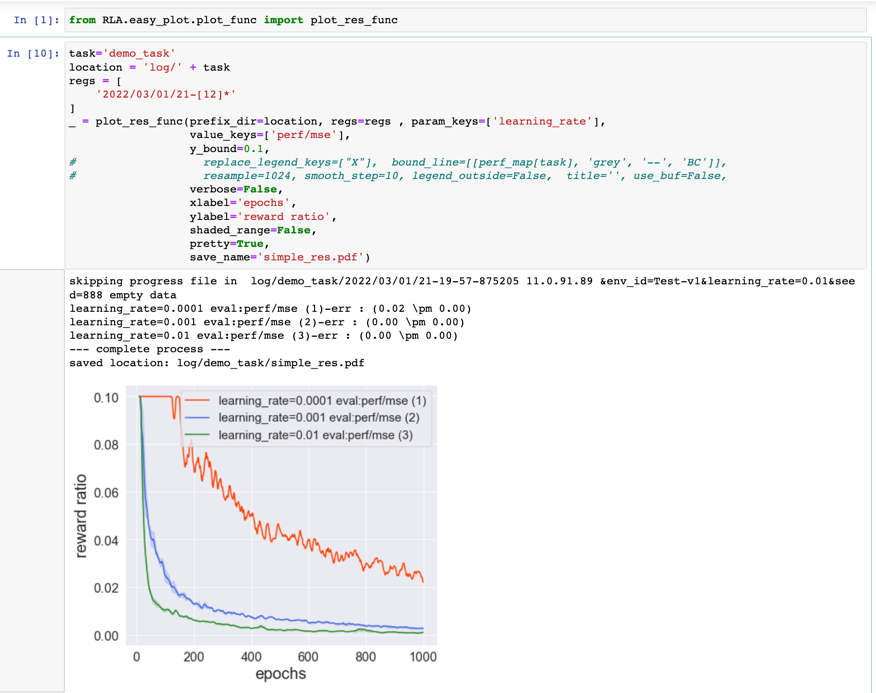
- View data in "results" directory directly: other types of data are stored in
${data_root}/results/${task_name}/${index_name}



Experiment review:
Given any experiment named as ${task_name}/${index_name}, we can find the line-by-line code in ${data_root}/code/${task_name}/${index_name} and corresponding hyperparameters in ${data_root}/code/${task_name}/${index_name}/parameter.json. We can configure the files to be stored in BACKUP_CONFIG in rla_config.yaml.
You can use the Compare with... method in Pycharm or any folder comparison extension in vscode, e.g., Compare Folders, to compare the whole differences between any two experiments.
Modify
In general, it is unnecessary to change the contents of experiment logs. In our practice, a common scenario is to load historical experiments/modules to resume training or for downstream tasks. In RLA, we provide a tool for different requirements of experiment loading, which is located in RLA.exp_loader. This tool can be used easily to:
- Load a pretrained model for another task (e.g., validation).
- Resume an experiment.
- Resume an experiment with different settings.
Batch Management
We manage the items in the database via toolkits in rla_scripts. Currently, the rla_scripts includes
- Archive: archive important experiments into an archived database, which will be saved in DATA_ROOT/arc.
- Delete: delete all useless experiments at once.
- Send to remote [TODO]
- Download from remote [TODO]
We can use the above tools after copying the rla_scripts to our research project and modifying the DATA_ROOT in config.py to locate the root of the RLA database. We give several user cases in https://github.com/xionghuichen/RLAssistant/blob/main/test/test_scripts.py. We will also introduce our practices of using RLA to manage our projects .
In practice, we might conduct our experiments in multiple physical machines for the same project.
Different physical machines separate the experiment data in the database.
We develop a simple log-sending tool based on ftplib/pysftp.
We split the physical machines into a main node and slave nodes.
For each slave node, we should extra configure the following setting in rla_config.yaml:
SEND_LOG_FILE: True
REMOTE_SETTING:
ftp_server: '114.114.114.114'
username: 'agent'
password: '123'
remote_data_root: 'remote_project/data_root/'
file_transfer_protocol: 'sftp'
port: 22
where SEND_LOG_FILE is set to True, ftp_server, username and password are the ip address, username and passward of the master node respectively, and file_transfer_protocol is the protocol to send data. remote_data_root defines the data_root of the database in the main node.
For the main node, configure the exp_manger by exp_manager.configure(..., is_master_node=True).
In our experiment code, we should call the function RLA.exp_manager.sync_log_file periodically, for example,
for i in range(1000):
# your trianing code.
exp_manager.sync_log_file()
then the data items will be sent to the remote_data_root of the main node. Since is_master_node is set to True in the main node, the exp_manager.sync_log_file() will be skipped in the main node.
PS:
-
You might meet "socket.error: [Errno 111] Connection refused" problem in this process. The solution can be found here.
-
An alternative way is to build the NFS for your physical machines and locate data_root to the NFS.
We write the usage of RLA as unit tests. You can check the scripts in test folder for more details (include test_plot.py, test_scripts.py, and test_proj/proj/test_manger.py).
- support custom data structure saving and loading.
- support video visualization.
- add comments and documents to the functions.
- add an auto-integration script.
- download/upload experiment logs through timestamp.
- allow sync LOG only or ALL TYPE LOGS.
- add unit_test to ckp loader.