The solution is contained in the tarball submit.tar.gz. In it will be requirements.txt, Makefile, and src/.
The quickest way to run the server on port 5000 is to run make install server.
Included is a Makefile with a few convenient targets for running the service:
install- create the venv and installs the dependencies from requirements.txtserver- runs the server on port 5000tests- runs testsclean- removes the venvclean-pyc- removes all pyc files
To run the server on a different port, run python main.py <port number> or
update the Makefile to do this.
The service was built with a REST interface. At a high level, it exposes the following endpoints:
GET /<algorithm>_status
Returns 200 with the JSON body {"status": "OK"} if the internal data
structures are healthy, otherwise it returns a 500 with JSON body {"status": "BAD", "message": <message>} with some sort of message describing the problem.
GET /<algorithm>/median
Returns 200 with the JSON body {"median": <median>}. It could also return a 500
if some internal state is messed up.
POST /<algorithm>[?x=<float>]
Can be called with a url arg x specifying one number to insert into our stream.
It also accepts a JSON body with {"x": [floats]} which is a list of floats to
be inserted into our stream. Returns the JSON body:
{
"inserted": [floats that were inserted],
"buffer_size": <number of things inserted>
}
Each algorithm adds some more metadata to this response (see the algorithms section for more details on the implementation):
Alg1 and Alg2
"max_buffer_size": <maximum number of elements that can be inserted>
Alg3
"upper_bound": <largest value that can be inserted to the buffer; any larger value gets treated as this value>"bucket_size": <size of buckets used in the frequency map>
DELETE /<algorithm>
Will have the same response as the POST except instead of an "inserted" key
there will be a "n_deleted" key which is the number of elements deleted from
the buffer.
There were 3 main approaches I took to solving this problem summarized below:
| URL Path | Description | Single Write | Bulk Write | Median | Memory |
|---|---|---|---|---|---|
| /alg1 | Unsorted buffer with median of medians. | O(1) | O(k) | O(n) (O(log n) in parallel) | O(n) |
| /alg2 | Two heaps | O(log n) | O(k log n) | O(1) | O(n) |
| /alg3 | Frequency map approximation | O(1) | O(k) | O(1) | O(1) |
This approach utilized the divide and conquer median of medians algorithm to find the median of a list of unsorted floats. This algorithm performed the worst and for good reason. It relies on a heavy recursive stack to compute the median and uses a bunch of temporary storage as well to copy parts of the input list. However, given a very high write throughput compared to reads, this method might work okay. We could also trigger this to run in parallel on some worker machine (e.g. celery, hadoop, etc) to get O(log n) runtime with some callback to write the median back to.
Technically, this is an approximation because if there are an even number of elements in the list, it returns the n/2nd element (even though technically it should return the average of the n/2nd and (n/2+1)th element. If there are an odd number, this will return the correct median.
This algorithm requires a static limit to be set on the max size of the buffer. If there are already that many elements in the buffer, we reject post requests with a 507. We could instead implement an LRU eviction policy and treat the buffer as a circular buffer; in the case of spill over, we just start overwriting elements towards the front. We could also persist this buffer to disk if we needed to.
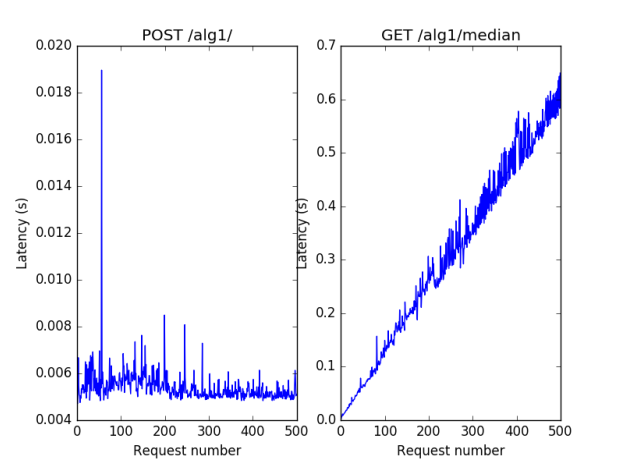
Figure 1 - The benchmark for alg1, demonstrating that insertion is constant (modulo one spike and some noise) and getting the median is linear with respect to the input size.
In this approach we store the numbers in the stream in two heaps - one max heap with the smaller half of the numbers (call it the left heap) and one min heap with the larger half of the numbers (call it the right heap). We maintain the invariant that abs(len(left) - len(right)) <= 1. When computing the median, if len(left) == len(right), we return the average of the roots. Else, we return the root from the heap with the additional element. This gives us an exact median calculation in O(1) time.
We insert to the left heap if the element is smaller than the left root, else the right heap. If the heaps have the same size, or the heap to insert into is smaller by 1, then we insert into it. Else we move the root element from the larger heap to the smaller heap and then insert. This is an O(log(n)) operation. We begin by inserting the first two elements into different heaps and swapping left and right if need be.
This solution also has a max size, divided between the two heaps. Once this quota filled, subsequent post requests will 507. Again, we could implement an eviction policy if the heaps fill up. For example, we could alternatively evict the rightmost leaf from the left and right heaps.
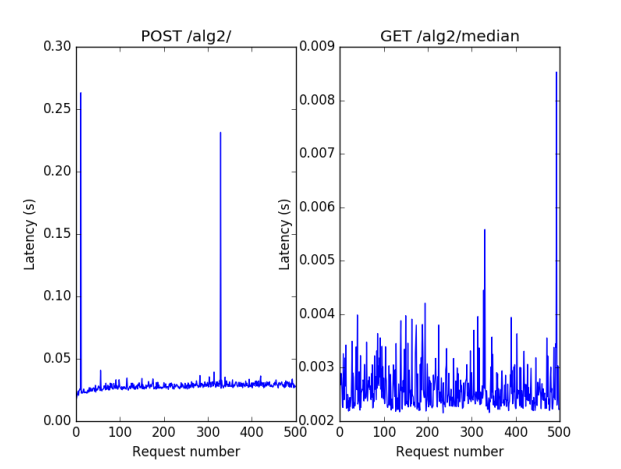
Figure 2 - The benchmark for alg2, demonstrating that insertion time is constant (technically it is log, but at this small scale log(n) tends to be small and relatively constant; also due to the two spikes, the log curve looks almost flat) and getting the median is constant.
This is an approximation approach which relies keeping a frequency map. The index into the frequency map represents all floats which floor to that integer (note that the width of a bucket is configurable via a constant). This buffer has a max size. The last bucket will be all numbers greater than or equal to this max size. Insertion simply floors the float and increments the count in the bucket, an O(1) operation.
The median is computed by walking down the frequency map till we hit a bucket in which the n/2nd element would lie. We assume a uniform distribution within this bucket. So if the 4th element in the bucket is the n/2nd element in our stream, and there are 7 elements in the bucket, we return the median to be 0.5
- the bucket index.
The size of the buffer does not change based on the number of inputs, so it’s constant (albeit very large). Insertion is constant. Finding the median is also constant with respect to n (number of streamed elements) because it is bounded by the range of elements we have inserted (e.g. if the smallest number that’s been streamed is 3 and the largest is 15, we will at worst do (15 - 3) / 2 = 6 operations). Thus, this is the fastest overall method. There is also no limit to how many numbers you can insert (technically there is since Python has infinite precision numbers so at some point your list will oom, but it will require a lot of numbers to be inserted in the stream).
If we knew about what types of numbers we were streaming, we may be able to more intelligently assign buckets. Right now buckets are the floor of the float (or some constant number of such buckets). But we could imagine an optimization where our buckets are more specific for smaller numbers, but more granular for larger numbers (e.g. you can use int(sqrt(input)) to determine the bucket it belongs to.
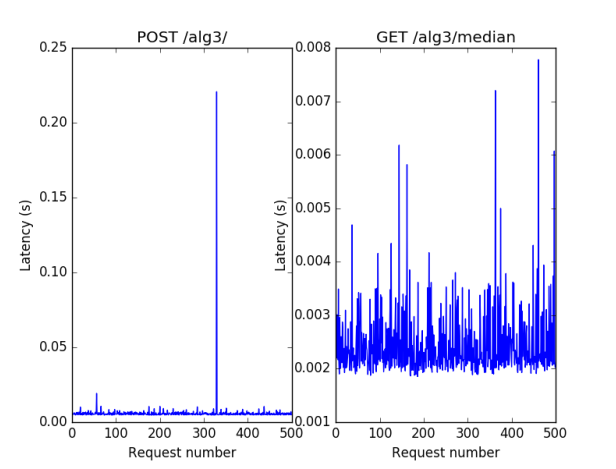
Figure 3 - The benchmark for alg3, demonstrating that insertion time is constant and getting the median is constant.
This code was implemented using Flask, a Python library for creating HTTP
services. The tests were run using nosetests and written with Python’s built in
unittest library. I used reflections to dynamically create routes based on the
Python files in controllers/maas. To implement a new algorithm, just create a
file foo.py with a class Maas which inherits from controllers.maas._MaaS
and you will get a route /foo which executes with that algorithm.
All the source code lives in src/. The main script is main.py which runs
the server on an optionally specified port (e.g. python main.py 6543 would
run the server on port 6543). No specified port defaults to port 5000. The
flask routes are implemented in app.py. The base health_check and core routes
are implemented in controllers/health_check.py and controllers/base.py. There
are some utility methods and classes in utils/ including a heap implementation,
a flask API wrapper, http exceptions, and other auxiliary utilities.
A valid MaaS algorithm must implement the following class methods:
get_median(cls)- return the current median based on the streaminsert(cls, element)- insert the floating point into the data structurereset(cls)- reset the internal state (clear the stream)remaining_space(cls)- return the number of elements that can be added to the streamhealth_check(cls)- return the internal status of the data structures. Returns ‘OK’ if the state is good otherwise raises InternalServerError (status code 500).
When designing the solution, I made the assumption that there will be at most one operation (get, post, or delete) at any given time for each algorithm. Therefore, I did not make my MaaS implementation or the data structures associated with them thread safe. If we wanted to scale this to support concurrent requests, we would probably need to use locks to perform a certain series of operations in a transaction and make the underlying data structures thread safe.