A custom library to create recurrent and all kinds of whacky architectures that in theory can support multiple loss functions. The central idea is the use of a module class. Like in most Deep learning libraries a module consists of 3 things:
- trainable or non-trainable params
- a forward function
- a backward function which:
- finds gradients with respect to trainable params
- finds gradients with respect to input of the module
- passes these input gradients to parents of the module
The core idea of using 'modules' with above three properties is an old idea. But this old idea was somehow lost in the process of creating highly optimized libs. This is an experimental library. It uses pytorch as a base and torch.autograd.grad() to automatically get necessary gradients in a module. This avoids writing a custom automatic-differentiation code or manually calculating gradients in backward().
Note: Currently, the library isn't highly optimized. With time, we will keep improving it.
- In pytorch, a single loss.backward() updates all the leaf nodes. Here,each module calculates its own gradient wrt to output. This gives higher flexibility in ways of arranging modules in different shapes instead of the traditional ways of single forward and backward pass.
- Any architecture can support multiple loss functions. These errors can be backpropagated independent of each other.
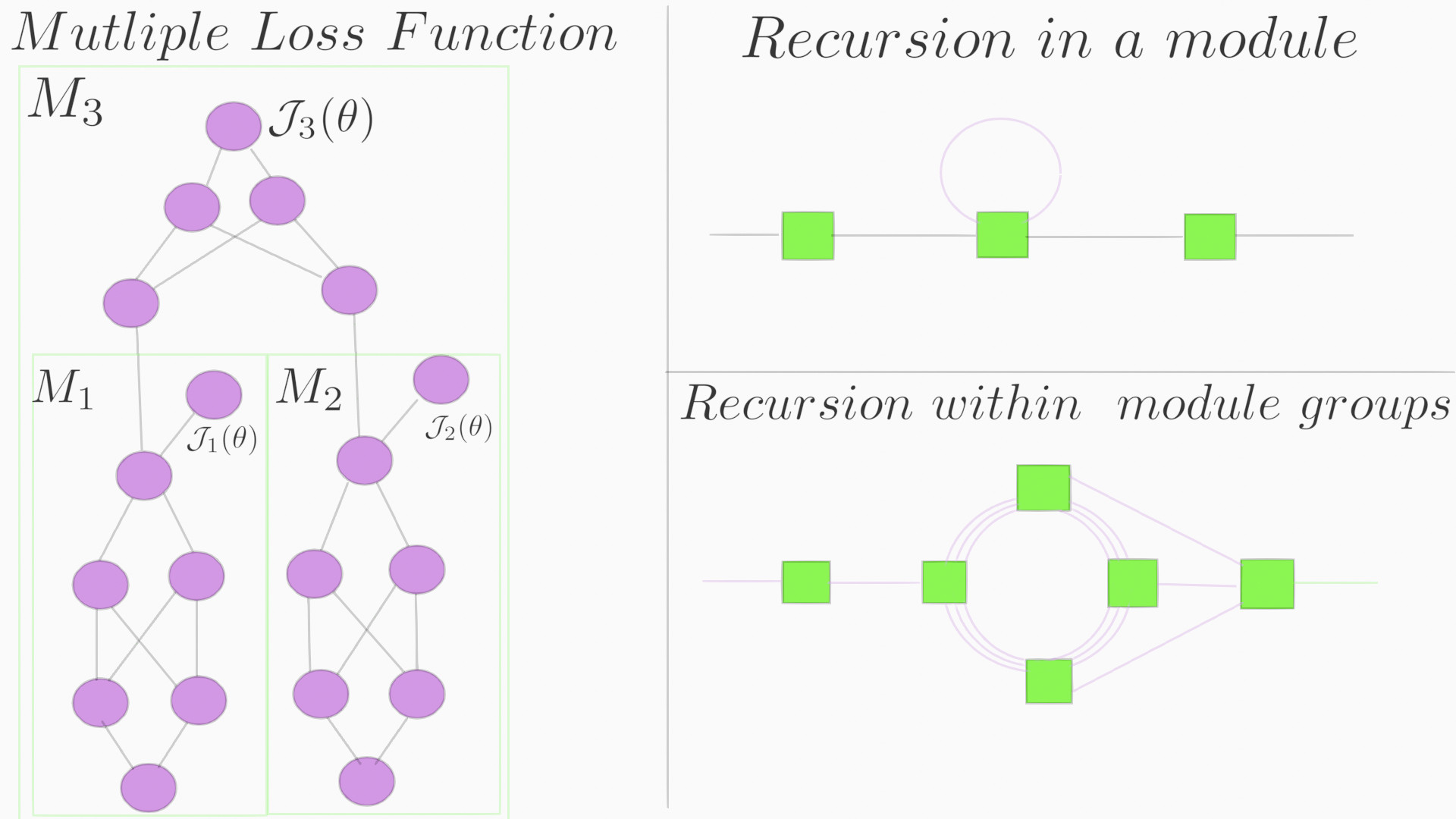
- Each module can have its own optimizer or different update rule.
Current architectures have a single forward and backward pass. This library may seem like a overkill for making similar architectures. But, in future, we might be needing new forms of architecture which are more flexible. Instead of making this lib when the need arises, I built it while learning backprop and autograd so to be prepared for future.
A simple Logistic Classification using this lib
Primer on Module and Node classes:
- Node class: Node class contains the output tensors of the forward function of Module object. It also contains other information like the children Modules(i.e. Module objects that use the above output values). A Node acts as a connection between different Modules and facilitates gradient flow.
- Module class: Module class is the backbone of this lib. Its main function is to calculate gradients of inputs and trainable params wrt outputs. To do it keeps track of parent and child Nodes, it keeps track of the gradients it received till now, it creates Node objects for the outputs of the forward function.
- Using class.call() instead of forward(): to get output of a module, call module_name(inputs) instead of module_name.forward(input). Example
- Even a simple matrix multiplication(with learnable params) has to be done with a module class. Reason: any operation in which gradients of operation's outputs are not same as operation's inputs will require Module.backward() to calculate appropriate gradients for the operation's inputs.
- All intermediary tensors are saved inside a Node or Module class which facilitates gradient passing. Since, inputs(
$x$ ) and targets($\bar{y}$ ) of a model don't need gradients they can be directly used as a tensor without Node or Module class. - All outputs of Module have to be used later. Maybe as an input to other module or as a loss value. Reason: Current implementation checks (if no of children == no of gradients received from children: calculate_gradients()), if a child Node is never used and doesn't receive any gradients, it would hinder gradient calculation in its parent.
- Loss should return a tensor with non-zero dims
- All trainable params should have requires_grad= True
- Each module should have an optimizer. You can directly set an optimizer for the entire model(and all modules in it) or you can set a different optimizer for each module.
- No functionality exists that can replicate register_backward_hook()