NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。
-
使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节约不少时间;nodejs使用Google V8作为运行引擎,性能可观;由于nodejs语言本身非阻塞、异步的特性,运行爬虫这类IO密集CPU需求不敏感的系统表现很出色,与其他语言的版本简单的比较,开发量小于C/C++/JAVA,性能高于JAVA的多线程实现以及Python的异步和携程方式的实现。
-
调度中心负责网址的调度,爬虫进程分布式运行,即**调度器统一决策单个时间片内抓取哪些网址,并协调各爬虫工作,爬虫单点故障不影响整体系统。
-
爬虫在抓取时就对网页进行了结构化解析,摘取到需要的数据字段,入库时不仅是网页源代码还有结构化了的各字段数据,不仅使得网页抓取后数据立马可用,而且便于实现入库时的精准化的内容排重。
-
集成了phantomjs。phantomjs是无需图形界面环境的网页浏览器实现,利用它可以抓取需要js执行才产生内容的网页。通过js语句执行页面上的用户动作,实现表单填充提交后再抓取下一页内容、点击按钮后页面跳转再抓取下一页内容等。
-
重试及容错机制。http请求有各种意外情况,都有重试机制,失败后有详细记录便于人工排查。都返回的页面内容有校验机制,能检测到空白页,不完整页面或者是被代理服务器劫持的页面;
-
可以预设cookie,解决需要登录后才能抓取到内容的问题。
-
限制并发数,避免因为连接数过多被源网站屏蔽IP的问题。
-
集成了代理IP使用的功能,此项功能针对反抓取的网站(限单IP下访问数、流量、智能判断爬虫的),需要提供可用的代理IP,爬虫会自主选择针对源网站还可以访问的代理IP地址来访问,源网站无法屏蔽抓取。
-
产品化功能,爬虫系统的基础部分和具体业务实现部分架构上分离,业务实现部分不需要编码,可以用配置来完成。
-
Web界面的抓取规则设置,热刷新到分布式爬虫。在Web界面配置抓取规则,保存后会自动将新规则刷新给运行在不同机器上的爬虫进程,规则调整不需要编码、不需要重启程序。
可配置项:
1). 用正则表达式来描述,类似的网页归为一类,使用相同的规则。一个爬虫系统(下面几条指的都是某类网址可配置项);
2). 起始地址、抓取方式、存储位置、页面处理方式等;
3). 需要收集的链接规则,用CSS选择符限定爬虫只收集出现在页面中某个位置的链接;
3). 页面摘取规则,可以用CSS选择符、正则表达式来定位每个字段内容要抽取的位置;
4). 预定义要在页面打开后注入执行的js语句;
5). 网页预设的cookie;
6). 评判该类网页返回是否正常的规则,通常是指定一些网页返回正常后页面必然存在的关键词让爬虫检测;
7). 评判数据摘取是否完整的规则,摘取字段中选取几个非常必要的字段作为摘取是否完整的评判标准;
8). 该类网页的调度权重(优先级)、周期(多久后重新抓取更新)。
-
为了减少冗余开发,根据抓取需求划分为实例,每个实例的基础配置(存储数据库、爬虫运行参数、定制化代码)都可以不同,即抓取应用配置的层次为:爬虫系统->实例->网址。
-
爬虫系统结构上参考了scrapy,由core、spider、downloader、extractor、pipeline组成,core是各个组件的联合点和事件控制中心,spider负责队列的进出,downloader负责页面的下载,根据配置规则选择使用普通的html源码下载或者下载后用phantomjs浏览器环境渲染执行js/css,extractor根据摘取规则对文档进行结构化数据摘取,pipeline负责将数据持久化或者输出给后续的数据处理系统。这些组件都提供定制化接口,如果通过配置不能满足需求,可以用js代码很容易个性化扩展某个组件的功能。
提示:建议刚接触本系统的用户跳过架构介绍环节直接进入第二部分,先将系统运行起来,有一个感性认识后再来查阅架构的环节,如果您需要做深入的二次开发,请仔细阅读本环节资料
整体架构

图中黄色部分为爬虫系统的各个子系统。
-
SuperScheduler是**调度器,Spider爬虫将收集到的网址放入到各类网址所对对应的网址库中,SuperScheduler会依据调度规则从各类网址库抽取相应量的网址放入待抓取队列。
-
Spider是分布式运行的爬虫程序,从调度器调度好的待抓取队列中取出任务进行抓取,将发现的网址放入网址库,摘取的内容存库,将爬虫程序分为core一个核心和download、extract、pipeline 4个中间件,是为了在爬虫实例中能够比较容易的重新定制其中某块功能。
-
ProxyRouter是在使用代理IP的时候将爬虫请求智能路由给可用代理IP的。
-
Webconfig是web的爬虫规则配置后台。
##【运行环境准备】
- 安装好nodejs 环境,从git仓库clone源码到本地,在文件夹位置打开命令提示符,运行“npm install”安装依赖的模块;
- redis server安装(同时支持redis和ssdb,从节约内存的角度考虑,可以使用ssdb,在setting.json可以指定类型,下面会提到)。
- hbase环境,抓取到网页、摘取到的数据将存储到hbase,hbase安装完毕后要将http rest服务开启,后面的配置中会用到,如果要使用其他的数据库存储,可以不安装hbase,下面的章节中将会讲到如何关闭hbase功能以及定制化自己的存储。hbase shell中初始化hbase 列簇:
create 'crawled',{NAME => 'basic', VERSIONS => 3},{NAME=>"data",VERSIONS=>3},{NAME => 'extra', VERSIONS => 3}
create 'crawled_bin',{NAME => 'basic', VERSIONS => 3},{NAME=>"binary",VERSIONS=>3}推荐使用hbase rest方式, 当你启动hbase后, 在hbase目录的bin子目录下执行以下命令可以启动hbase rest:
./hbase-daemon.sh start rest默认端口为8080, 下面配置中会用到.
##【实例配置】
- 实例在instance目录下,拷贝一份example,重命名其他的实例名,例如:abc,以下说明中均使用该实例名举例。
- 编辑instance/abc/setting.json
{
/*注意:此处用于解释各项配置,真正的setting.json中不能包含注释*/
"driller_info_redis_db":["127.0.0.1",6379,0],/*网址规则配置信息存储位置,最后一个数字表示redis的第几个数据库*/
"url_info_redis_db":["127.0.0.1",6379,1],/*网址信息存储位置*/
"url_report_redis_db":["127.0.0.1",6380,2],/*抓取错误信息存储位置*/
"proxy_info_redis_db":["127.0.0.1",6379,3],/*http代理网址存储位置*/
"use_proxy":false,/*是否使用代理服务*/
"proxy_router":"127.0.0.1:2013",/*使用代理服务的情况下,代理服务的路由中心地址*/
"download_timeout":60,/*下载超时时间,秒,不等同于相应超时*/
"save_content_to_hbase":false,/*是否将抓取信息存储到hbase,目前只在0.94下测试过*/
"crawled_hbase_conf":["localhost",8080],/*hbase rest的配置,你可以使用tcp方式连接,配置为{"zookeeperHosts": ["localhost:2181"],"zookeeperRoot": "/hbase"},此模式下有OOM Bug,不建议使用*/
"crawled_hbase_table":"crawled",/*抓取的数据保存在hbase的表*/
"crawled_hbase_bin_table":"crawled_bin",/*抓取的二进制数据保存在hbase的表*/
"statistic_mysql_db":["127.0.0.1",3306,"crawling","crawler","123"],/*用来存储抓取日志分析结果,需要结合flume来实现,一般不使用此项*/
"check_driller_rules_interval":120,/*多久检测一次网址规则的变化以便热刷新到运行中的爬虫*/
"spider_concurrency":5,/*爬虫的抓取页面并发请求数*/
"spider_request_delay":0,/*两个并发请求之间的间隔时间,秒*/
"schedule_interval":60,/*调度器两次调度的间隔时间*/
"schedule_quantity_limitation":200,/*调度器给爬虫的最大网址待抓取数量*/
"download_retry":3,/*错误重试次数*/
"log_level":"DEBUG",/*日志级别*/
"use_ssdb":false,/*是否使用ssdb*/
"to_much_fail_exit":false,/*错误太多的时候是否自动终止爬虫*/
"keep_link_relation":false/*链接库里是否存储链接间关系*/
}##【运行】
- 爬虫运行的基本步骤是: *
- 在WEB界面配置抓取规则
- 调试单个网址抓取是否正常
- 运行调度器(调度器启动一个即可)
- 如果使用代理IP抓取的话启动代理路由
- 启动爬虫(爬虫可以分布式启动多个)
以下是具体的启动命令
-
运行WEB配置(配置规则参考下一章说明)
node run.js -i abc -a config -p 8888
在浏览器打开 http://localhost:8888 可以在web界面配置抓取规则
-
测试单个页面抓取
node run.js -i abc -a test -l "http://domain/page/"
-
运行调度器
node run.js -i abc -a schedule
-i指定了实例名,-a指定了动作schedule,下同
-
运行代理路由 仅使用了代理IP抓取的情况下才需要运行代理路由
node run.js -i abc -a proxy -p 2013
此处的-p指定代理路由的端口,如果在本机运行,setting.json的proxy_router及端口为 127.0.0.1:2013
-
运行爬虫
node run.js -i abc -a crawl
可以在instance/example/logs 下查看输出日志debug-result.json
在正式运行的环境下建议使用nodejs 的 pm2或者python的supervisor来托管进程.
##【抓取规则配置】 打开web界面,例如:http://localhost:8888/ , 进入“Drilling Rules”,添加规则。这是一个json编辑器,可以在代码模式/可视化模式之间切换。下面给出配置项的说明.具体的应用配置可以参考下一章节的示例.
{
/*注意:此处用于解释各项配置,真正的配置代码中不能包含注释*/
"domain": "",/*顶级域名,例如163.com(不带主机名,www.163.com是错误的)*/
"url_pattern": "",/*网址规则,正则表达式,例如:^http://domain/\d+\.html,限定范围越精确越好*/
"alias": "",/*给该规则取的别名*/
"id_parameter": [],/*该网址可以带的有效参数,如果数组第一个值为#,表示过滤一切参数*/
"encoding": "auto",/*页面编码,auto表示自动检测,可以填写具体值:gbk,utf-8*/
"type": "node",/*页面类型,分支branch或者节点node*/
"save_page": true,/*是否保存html源代码*/
"format": "html",/*页面形式,html/json/binary*/
"jshandle": false,/*是否需要处理js,决定了爬虫是否用phantomjs加载页面*/
"extract_rule": {/*摘取规则,后面单独详述*/
"category": "crawled",
"rule": {/*如果不摘取数据,rule应该为空*/
"title": {/*一个摘取单元,后面单独详述*/
"base": "content",
"mode": "css",
"expression": "title",
"pick": "text",
"index": 1
}
}
},
"cookie": [],/*cookie值,有多个object组成,每个object是一个cookie值*/
"inject_jquery": false,/*在使用phantomjs的情况下是否注入jquery*/
"load_img": false,/*在使用phantomjs的情况下是否载入图片*/
"drill_rules": ["a"],/*页面中感兴趣的链接,填写css选择符选择a元素,可以为多个,此处表示所有链接*/
"drill_relation": {/*一个摘取单元,从页面中摘取一个值来填充上下文关系对此页的描述*/
"base": "content",
"mode": "css",
"expression": "title",
"pick": "text",
"index": 1
},
"validation_keywords": [],/*验证页面下载是否有效的关键词,可以为多个,为空表示不验证*/
"script": [],/*在页面中执行的脚本,可以为多个,依次对应每个层级下的执行。以js_result=..形式*/
"navigate_rule": [],/*自动导航,css选择符,可以为多个,依次对应每个层级,phantomjs将点击匹配的元素进行导航*/
"stoppage": -1,/*导航几个层级后停止*/
"priority": 1,/*调度优先级,数字越小越优先*/
"weight": 10,/*调度权重,数字越大越有限*/
"schedule_interval": 86400,/*重新调度的周期,单位秒*/
"active": true,/*是否激活该规则*/
"seed": [],/*种子地址,重新调度时从这些网址开始*/
"schedule_rule": "FIFO"/*调度方式,FIFO或者LIFO*/
}{
"base": "content",/*基于什么摘取,网页DOM:content或者给予url*/
"mode": "css",/*摘取模式,css或者regex表示css选择符或者正则表达式,value表示给固定值*/
"expression": "title",/*表达式,与mode相对应css选择符表达式或者正则表达式,或者一个固定的值*/
"pick": "text",/*css模式下摘取一个元素的属性或者值,text、html表示文本值或者标签代码,@href表示href属性值,其他属性依次类推在前面加@符号*/
"index": 1/*当有多个元素时,选取第几个元素,-1表示选择多个,将返回数组值*/
}/*摘取规则由多个摘取单元构成,它们之间的基本结构如下*/
"extract_rule": {
"category": "crawled",/*该节点存储到hbase的表名称*/
"rule": {/*具体规则*/
"title": {/*一个摘取单元,规则参考上面的说明*/
"base": "content",
"mode": "css",
"expression": "title",
"pick": "text",
"index": 1,
"subset":{/*子集*/
"category":"comment",/*属于comment(存储到comment)*/
"relate":"#title#",/*与上级关联*/
"mapping":false,/*子集类型,mapping为true将分到另外的表中单独存储*/
"rule":{
"profile": {"base":"content","mode":"css","expression":".classname","pick":"@href","index":1},/*摘取单元*/
"message": {"base":"content","mode":"css","expression":".classname","pick":"@alt","index":1}
},
"require":["profile"]/*必须字段*/
}
}
}
"require":["title"]/*必须字段,如果里面的值为数组,表示这个数组内的值有任意一个就满足要求,例如[[a,b],c]*/
}此步骤假设你已经将web配置后台运行起来了,如何运行web配置请按照上一章节的说明
下面列出一个抓取微信号的配置例子.假设我们的意图是抓取http://www.sovxin.com 上的所有微信号.
第一步是观察网站的结构,大概可以分为4个层次:首页,分类频道页,列表页,详情页.
我们根据这个页面层次来进行抓取规则的配置,其中,只有详情页是需要配置字段摘取信息的,其他3种页面都是用来逐步发现详情页的.
我们将这个顺序倒过来,从详情页开始配置,最后再看首页.
##规则列表截图(你的界面肯定还没有这些规则列表,点击Add添加规则,参考我下面列出的配置)

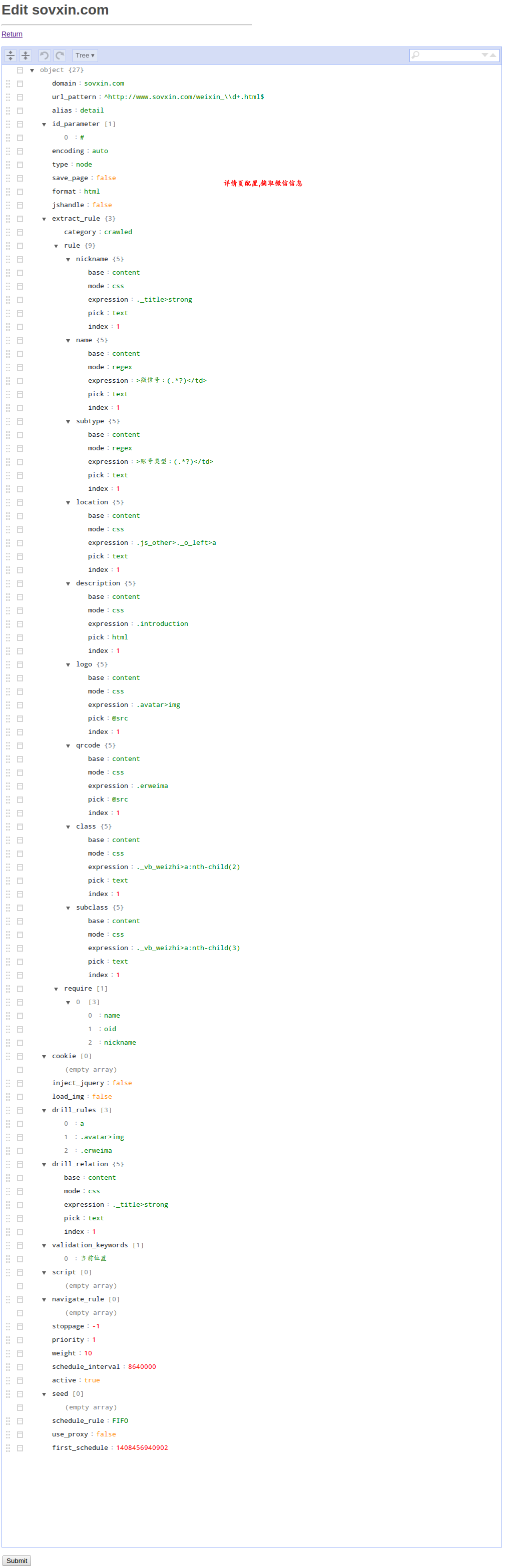
你应当对照上一章节讲到的每个配置项的说明来理解这个示例
可以将编辑器切换到代码模式,将下面的json粘贴到里面.
{
"domain": "sovxin.com",
"url_pattern": "^http://www.sovxin.com/weixin_\\d+.html$",
"alias": "detail",
"id_parameter": [
"#"
],
"encoding": "auto",
"type": "node",
"save_page": false,
"format": "html",
"jshandle": false,
"extract_rule": {
"category": "crawled",
"rule": {
"nickname": {
"base": "content",
"mode": "css",
"expression": "._title>strong",
"pick": "text",
"index": 1
},
"name": {
"base": "content",
"mode": "regex",
"expression": ">微信号:(.*?)</td>",
"pick": "text",
"index": 1
},
"subtype": {
"base": "content",
"mode": "regex",
"expression": ">账号类型:(.*?)</td>",
"pick": "text",
"index": 1
},
"location": {
"base": "content",
"mode": "css",
"expression": ".js_other>._o_left>a",
"pick": "text",
"index": 1
},
"description": {
"base": "content",
"mode": "css",
"expression": ".introduction",
"pick": "html",
"index": 1
},
"logo": {
"base": "content",
"mode": "css",
"expression": ".avatar>img",
"pick": "@src",
"index": 1
},
"qrcode": {
"base": "content",
"mode": "css",
"expression": ".erweima",
"pick": "@src",
"index": 1
},
"class": {
"base": "content",
"mode": "css",
"expression": "._vb_weizhi>a:nth-child(2)",
"pick": "text",
"index": 1
},
"subclass": {
"base": "content",
"mode": "css",
"expression": "._vb_weizhi>a:nth-child(3)",
"pick": "text",
"index": 1
}
},
"require": [
[
"name",
"oid",
"nickname"
]
]
},
"cookie": [],
"inject_jquery": false,
"load_img": false,
"drill_rules": [
"a",
".avatar>img",
".erweima"
],
"drill_relation": {
"base": "content",
"mode": "css",
"expression": "._title>strong",
"pick": "text",
"index": 1
},
"validation_keywords": [
"当前位置"
],
"script": [],
"navigate_rule": [],
"stoppage": -1,
"priority": 1,
"weight": 10,
"schedule_interval": 8640000,
"active": true,
"seed": [],
"schedule_rule": "FIFO",
"use_proxy": false,
"first_schedule": 1408456940902
}
{
"domain": "sovxin.com",
"url_pattern": "^http://www.sovxin.com/t_.*?.html$",
"alias": "list",
"id_parameter": [
"#"
],
"encoding": "auto",
"type": "branch",
"save_page": false,
"format": "html",
"jshandle": false,
"extract_rule": {
"category": "crawled",
"rule": {}
},
"cookie": [],
"inject_jquery": false,
"load_img": false,
"drill_rules": [
"a"
],
"drill_relation": {
"base": "content",
"mode": "css",
"expression": "title",
"pick": "text",
"index": 1
},
"validation_keywords": [
"当前位置"
],
"script": [],
"navigate_rule": [],
"stoppage": -1,
"priority": 3,
"weight": 10,
"schedule_interval": 86400,
"active": true,
"seed": [
"http://www.sovxin.com/t_xiuxianyule_#.html#1#300#1",
"http://www.sovxin.com/t_jiankangshenghuo_#.html#1#300#1",
"http://www.sovxin.com/t_wenhuajiaoyu_#.html#1#300#1",
"http://www.sovxin.com/t_jiaoliu_#.html#1#300#1",
"http://www.sovxin.com/t_qiyepinpai_#.html#1#300#1",
"http://www.sovxin.com/t_mingxingmingren_#.html#1#300#1",
"http://www.sovxin.com/t_youguanbumen_#.html#1#300#1",
"http://www.sovxin.com/t_zonghe_#.html#1#300#1"
],
"schedule_rule": "FIFO",
"use_proxy": false,
"first_schedule": 1414938594585
}
{
"domain": "sovxin.com",
"url_pattern": "^http://www.sovxin.com/fenlei_.*?.html$",
"alias": "category",
"id_parameter": [
"#"
],
"encoding": "auto",
"type": "branch",
"save_page": false,
"format": "html",
"jshandle": false,
"extract_rule": {
"category": "crawled",
"rule": {}
},
"cookie": [],
"inject_jquery": false,
"load_img": false,
"drill_rules": [
"a"
],
"drill_relation": {
"base": "content",
"mode": "css",
"expression": "title",
"pick": "text",
"index": 1
},
"validation_keywords": [
"当前位置"
],
"script": [],
"navigate_rule": [],
"stoppage": -1,
"priority": 2,
"weight": 10,
"schedule_interval": 86400,
"active": true,
"seed": [
"http://www.sovxin.com/fenlei_zixun.html"
],
"schedule_rule": "FIFO",
"use_proxy": false,
"first_schedule": 1414938594585
}
{
"domain": "sovxin.com",
"url_pattern": "^http://www.sovxin.com/$",
"alias": "home",
"id_parameter": [
"#"
],
"encoding": "auto",
"type": "branch",
"save_page": false,
"format": "html",
"jshandle": false,
"extract_rule": {
"category": "crawled",
"rule": {}
},
"cookie": [],
"inject_jquery": false,
"load_img": false,
"drill_rules": [
"a"
],
"drill_relation": {
"base": "content",
"mode": "css",
"expression": "title",
"pick": "text",
"index": 1
},
"validation_keywords": [
"搜微信"
],
"script": [],
"navigate_rule": [],
"stoppage": -1,
"priority": 4,
"weight": 10,
"schedule_interval": 86400,
"active": true,
"seed": [
"http://www.sovxin.com/"
],
"schedule_rule": "FIFO",
"use_proxy": false,
"first_schedule": 1414938594585
}抓取的数据默认是存储到hbase,你可以可以将这种默认行为取消,将数据存储到其他类型的数据库.修改instance/你的实例/settings.json,将save_content_to_hbase设置为false.然后修改instance/你的实例/spider_extend.js,这里是你定制化开发的地方,将pipeline方法的注释拿掉,爬虫抓完页面后会调用该函数,传入一个extracted_info是摘取后的结构化数据,另一个参数callback是回调函数要求你在做完你做的事情(实际上就是存数据到你的数据库).extracted_info的结构你可以console.dir(extracted_info)或者Webstorm IDE内断点调试以下就能看到. 以下代码(存储到mongodb)仅供参考
/**
* instead of main framework content pipeline
* if it do nothing , comment it
* @param extracted_info (same to extract)
*/
spider_extend.prototype.pipeline = function(extracted_info,callback){
var spider_extend = this;
if(!extracted_info['extracted_data']||isEmpty(extracted_info['extracted_data'])){
logger.warn('data of '+extracted_info['url']+' is empty.');
callback();
}else{
var data = extracted_info['extracted_data'];
if(data['article']&&data['article'].trim()!=""){
var _id = crypto.createHash('md5').update(extracted_info['url']).digest('hex');
var puerContent = data['article'].replace(/[^\u4e00-\u9fa5a-z0-9]/ig,'');
var simplefp = crypto.createHash('md5').update(puerContent).digest('hex');
var currentTime = (new Date()).getTime();
data['updated'] = currentTime;
data['published'] = false;
//drop additional info
if(data['$category'])delete data['$category'];
if(data['$require'])delete data['$require'];
//format relation to array
if(extracted_info['drill_relation']){
data['relation'] = extracted_info['drill_relation'].split('->');
}
//get domain
var urlibarr = extracted_info['origin']['urllib'].split(':');
var domain = urlibarr[urlibarr.length-2];
data['domain'] = domain;
logger.debug('get '+data['title']+' from '+domain+'('+extracted_info['url']+')');
data['url'] = extracted_info['url'];
var query = {
"$or":[
{
'_id':_id
},
{
'simplefp':simplefp
}
]
};
spider_extend.mongoTable.findOne(query, function(err, item) {
if(err){throw err;callback();}
else{
if(item){
//if the new data of field less than the old, drop it
(function(nlist){
for(var c=0;c<nlist.length;c++)
if(data[nlist[c]]&&item[nlist[c]]&&data[nlist[c]].length<item[nlist[c]].length)delete data[nlist[c]];
})(['title','article','tags','keywords']);
spider_extend.mongoTable.update({'_id':item['_id']},{$set:data}, {w:1}, function(err,result) {
if(!err) {
spider_extend.reportdb.rpush('queue:crawled', _id);
logger.debug('update ' + data['title'] + ' to mongodb, ' + data['url'] + ' --override-> ' + item['url']);
}
callback();
});
}else{
data['simplefp'] = simplefp;
data['_id'] = _id;
data['created'] = currentTime;
spider_extend.mongoTable.insert(data,{w:1}, function(err, result) {
if(!err){
spider_extend.reportdb.rpush('queue:crawled', _id);
logger.debug('insert '+data['title']+' to mongodb');
}
callback();
});
}
}
});
}else{
logger.warn(extracted_info['url']+' is lack of content, drop it');
callback();
}
}
}修改instance/你的实例/settings.json中的spider_concurrency. 注意:这里配置的是爬虫的并发请求数,每种网页的重复抓取周期是在规则配置界面设置的.
有时候通过web界面配置的规则并不能满足一些特殊的抓取需求,比如说一个页面抓取下来以后你要发起一个ajax子请求合并数据. 又比如说你要用自己的方法去摘取链接和内容.将instance/你的实例/spider_extend.js中的extract方法去掉,爬虫用内容的方法摘取完内容后会调用该函数,传入两个参数, extracted_info是抓取的信息,包含了摘取到的数据,callback是要求你完成你的动作后回调的函数,extracted_info的结构你可以console.dir(extracted_info)或者Webstorm IDE内断点调试以下就能看到. 最后你必须调用回调函数callback,并且将摘取信息作为参数,摘取信息的结构必须和传入的extracted_info一致,实际上建议你直接在extracted_info上改动,将其作为参数返回. 以下代码仅供参考:
/**
* DIY extract, it happens after spider framework extracted data.
* @param extracted_info
* {
"signal":CMD_SIGNAL_CRAWL_SUCCESS,
"content":'...',
"remote_proxy":'...',
"cost":122,
"inject_jquery":true,
"js_result":[],
"drill_link":{"urllib_alias":[]},
"drill_count":0,
"cookie":[],
"url":'',
"status":200,
"origin":{
"url":link,
"type":'branch/node',
"referer":'',
"url_pattern":'...',
"save_page":true,
"cookie":[],
"jshandle":true,
"inject_jquery":true,
"drill_rules":[],
"script":[],
"navigate_rule":[],
"stoppage":-1,
"start_time":1234
}
};
* @returns callback({*})
*/
spider_extend.prototype.extract = function(extracted_info,callback){
var self = this;
var domain = __getTopLevelDomain(extracted_info['url']);
var result = extracted_info;
switch(domain){
case 'sino-manager.com':
if (result['origin'].urllib == 'urllib:driller:sino-manager.com:sinolist') {
for(var i = 0; i < result['drill_link']['urllib:driller:sino-manager.com:sinolist'].length; i++) {
result['drill_link']['urllib:driller:sino-manager.com:sinolist'][i] = result['drill_link']['urllib:driller:sino-manager.com:sinolist'][i].replace(/(.{31})/,"$1s");
}
break;
} else {
break;
}
case 'chinaventure.com.cn':
if (result['origin'].urllib == 'urllib:driller:chinaventure.com.cn:chinaventurelist') {
var content = JSON.parse(result['content'].substring(1,result['content'].length-1));
var news_url = '';
var detail = [];
var list = [];
var pages;
for(var i = 0; i < content.length; i++) {
detail.push(content[i].news_url);
}
result['drill_link']['urllib:driller:chinaventure.com.cn:chinaventuredetail'] = detail;
var expression = new RegExp('^.*pages=([0-9]+).*$',"ig");
var matched = expression.exec(result['url']);
if (matched) {
pages = parseInt(matched[1])+1;
result['url'] = result['url'].replace('pages='+matched[1],'pages='+pages);
} else {
}
logger.debug(result['url']);
list.push( result['url']);
result['drill_link']['urllib:driller:chinaventure.com.cn:chinaventurelist'] = list;
break;
} else {
break;
}
default:;
}
return callback(result);
}理解数据结构, 有助于你熟悉整套系统进行二次开发. neocrawler用到4个存储空间, driller_info_redis_db, url_info_redis_db, url_report_redis_db, proxy_info_redis_db, 可以在实例下的settings.json配置, 4个空间存储的类别不同, 键名不会冲突, 可以将4个空间指向一个redis/ssdb库, 每个空间的增长量不一样, 如果使用redis建议将每个空间指向一个db, 有条件的情况下一个空间一个redis, 下面分别对4个空间的结构进行介绍:
存储了抓取规则及网址
- driller:{domain}:{alias}
例如:driller:163.com:newslist, 大括号表示变量,下同. hash类型, 存储了抓取规则, 在web界面配置的规则存储在这里.
- urllib:driller:{domain}:{alias}
例如: urllib:driller:163.com:newslist. list类型, 存储了某种规则的网址队列, 爬虫发现符合抓取规则的网址时, 将其存入相应的队列, 调度器将从这些队列里摘取网址进行调度, 爬虫依据调度队列进行抓取, 整个过程循环反复.
- queue:scheduled:all
待抓取队列, list类型, 同一时间存在很多urllib(参照上面一个说明), 调度器会根据爬虫的总调度限制及queue:scheduled:all队列长度得出当前可追加队列长度, 再根据你在web配置中心配置的调度权重(priority, weight)从每个队列中抽取相应网址放入queue:scheduled:all, 爬虫将从queue:scheduled:all摘取网址进行抓取.
- updated:driller:rule
记录抓取规则配置的版本信息. 爬虫/调度器对爬虫规则的变更是热感应(实时刷新)的, 但是不可能每次调度(一个周期大概间隔几秒)都将所有规则扫描重新载入, 于是就采用版本记录的方式, web配置中心更改抓取规则后变更版本信息, 爬虫会重复检测这个键, 如果发现版本变化则重新加载抓取规则.
该空间存储了网址信息, 抓取运行时间越长这里的数据量会越大
- {url-md5-lowercase}
例如: 9108d6a10bd476158144186138fe0ba8, hash类型, 记录了一个网址的详细信息, 在哪个页面被发现, 当前状态, 爬虫系统对该网址的操作轨迹(发现-调度-抓取-存储/失败等等)以及最后操作时间. 这些记录是调度器对二次发现网址是是否调度抓取的依据.
该空间存储爬虫抓取报告
- fail:urllib:driller:{domain}:{alias}
例如: fail:urllib:driller:163.com:newslist, zset类型, 记录了抓取失败的网址.
- stuck:urllib:driller:{domain}:{alias}
例如: stuck:urllib:driller:163.com:newslist, zset类型, 记录了存储(hbase)失败的网址.
抓取失败/存储失败的网址可以用tools/queue-helper.js添加到抓取队列重新抓取.
注: 针对网络因素爬虫对于抓取失败本身已经做了重试操作, 重试次数可以在settings.json配置. 上面提到的抓取/存取失败是指爬虫多次尝试后依然失败的网址, 一般情况下是由于抓取规则不正确或者hbase故障引起的.
- count:{date}
例如: count:20150203, hash类型, 抓取行为的增量统计, 实例文件夹下spider_extend.js中各个定制化函数中有增量统计的语句,默认是注释的, 打开后会做增量统计. 在web配置中心Crawling Daily Report就可以看到统计结果了.
该空间存储代理IP相关的数据
- proxy:public:available:3s
list类型, 当前可用的代理IP
- Email: successage@gmail.com,
- Blog: http://my.oschina.net/waterbear
- Issues: http://git.oschina.net/dreamidea/neocrawler/issues?assignee_id=&issue_search=&label_name=&milestone_id=&scope=&sort=&status=all
- QQ群讨论: 3239305
- QQ*扰: 419117039
- 微信*扰: dreamidea