Índice
Pregunta 1 (1pt) - ¿Para qué sirven los ODMs?. ¿Qué ventajas tiene utilizarlos?
Un ODM es un object-document mapper, un middleware que relaciona documentos en una bbdd con los objetos de una aplicación. Para que la aplicación almacene sus objetos en la bbdd se puede optar por realizar queries directamente sobre un driver o emplear un sw específico, en este caso un odm. Se destaca como ventaja que este sw hace de capa intermedia y suele impedir inyecciones de sql o facilita tratar formatos difíciles como el date.
=> improvement:
-
muchas cosas se hacen atomáticamenete: conectar a la bbdd, convertir tipos
-
la app queda más limpia, pues fomenta el patrón mvc, es deicr escribir un controlador, que es el que utiliza el odm y ataca a la bbdd.
-
el código del modelo queda único.
-
cachés que agilice las consultas más típicas.
-
sanitiza en genrral el código, evitando las nyecciones
-
genera auotmáticamente código
-
compeljso
-
curva de aprendizaje
-
buena arquitecutra
-
puede santurar la memeoria de lso objetos si se solcitna muchos datos.
Pregunta 2 (1pt) - Teorema de CAP (o de Brewer). Enuncielo y diga qué significan la C, la A y la P
Dado un sistema distribuido (uno que posee un estado que se encuentra distribuido entre un conjunto de nodos) se definen tres características de él: su C o Consistencia, su A o disponibilidad y su P o tolerancia a fallos que provoquen un particionamiento.
Consistencia: la posibildiad de que un estado esté actualizado en el sistema.
Disponibilidad: la posibilidad de que se pueda operar el sistema.
Tolerancia a particionamiento: la posibilidad de que ocurra un error en la red.
EL teorema de CAP dice que "en un sistema distribuido, con propiedades C, A y P, sólo se pueden asegurar dos". Es decir, si se produce un error en la red y el estado entre los nodos no se puede actualizar, o se decide optar a permitir operar el sistema (A) o a que no se opere, en favor de garantizar un estado consistente (C).
Pregunta 3 (1pt) - ¿En qué consiste el particionamiento (o Sharding) de una Base de Datos? Enumere 2 ventajas
Particionar una bbbdd consiste en fragmentar los datos almacenándolos en varios nodos. Se destacan dos ventajas que puede propiciar esta práctica:
-
Mejorar el rendimiento siendo eficiente económicamente: pues al escalar el servicio (por ejemplo cuando el índice de los datos ya no cabe en la ram de la máquina), en vez de adquirir una máquina mejor y más cara (escalado vertical) se puede optar por realizar un shard en un clúster sobre máquinas COTS.
-
Mejorar la latencia: al divdir los datos en nodos, se puede plantear acercar cierta ifnoramción al edge de ciertos usuarios para disminuir su latencia.
Pregunta 4 (1pt) – Data Value Pyramid o pirámide de valor de los datos. Indique qué es y que tiene cada uno de los niveles. (Si quiere puede ayudarse dibujando la pirámide en cuestión).
La pirámida de valro del dato es una representación inspirada asemejanza de la pirámide de las necesidades de Mashlow, que describe ciertas acciones sobre el análisis de datos y como en los niveles ascendientes las acciones aportan más valor.
Actions
Predictions
Reports
Explorations
Records
En la base se encuentran la creación de pipelines y estructuras para almacenar y dar formato a los datos.
A continaución los análissi y las exploraciones.
Después, los reportes o análsis más generales.
Luego las prediciones y por último las acciones.
Sea una base de datos MongoDB llamada “stats” que contiene un documento con información por cada barrio de España. El siguiente JSON es un ejemplo de dichos documentos:
{
"_id": ObjectId("571786ca7fdc0dc3e0631311"),
“CP”: "10280",
“ciudad": “Madrid",
“comunidad": “Comunidad de Madrid",
“barrio": “Chamberi",
“poblacion": 550074,
“bibliotecas”: [
{ “nombre”: “María Zambrano”, “libros”: 30123},
{ “nombre”: “Eduardo Lúpulo”, “libros”: 12883}
]
}
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "stats.zips"
}
]
Pregunta 1 (0.5 puntos) – Una vez abierto un terminal y conectado a la Mongo Shell, me conecta por defecto a la base de datos de nombre “test”. Conéctese a la base de datos comentada anteriormente y ejecute una query para buscar los barrios con el código postal 10280 o 10290:
use test
db.stats.find({
$or:[
{ CP: {$eq: 10280} },
{ CP: {$eq: 10290} }
]
})
Pregunta 2 (0.5 puntos) – Obtenga con un comando de la Mongo Shell los barrios que no tengan bibliotecas (estos pueden ser los que su array bibliotecas tenga tamaño 0 o directamente no tengan array bibliotecas).
db.stats.find({
$or:[
{ bibliotecas: {$eq: []} },
{ bibliotecas: {$size: 0} }
]
})
Pregunta 3 (0.5 puntos) – Busque con una única query los barrios que cumplan lo siguiente:
- o que sean de la Comunidad de Madrid
- o que no sean de la Comunidad de Madrid pero que tengan más de 30000 personas
db.stats.find({
$or:[
{comunidad: {$eq: Comunidad de Madrid} },
{$and:[
{comunidad: {$neq: Comunidad de Madrid} },
{poblacion: {$gt: 30000} }
]
]
})
Pregunta 4 (0.5 puntos) – Añada un campo nuevo con nombre “superpoblado” y su valor debe ser true para los barrios que tengan igual o más a 10000 personas y false para los barrios que tengan menos de 10000 personas.
db.stats.update({
{ $gte: 10000 },
{ $set: {superpoblado: "true"} }
})
db.stats.update({
{ $lt: 10000 },
{ $set: {superpoblado: "false"} }
})
Pregunta 5 (0.5 puntos) – Una aplicación que accede a esta base de datos se ha quejado que va muy muy lenta. Con el comando db.setProfilingLevel(1, 300) conseguimos logear queries lentas y vemos que hay miles de queries muy lentas que acceden al campo “CP”. ¿Cómo podríamos mejorar la performance de la base de datos? Indique el comando con el que lo arreglaría (sabemos que el campo “CP” es único, no hay dos documentos con dicho campo igual):
Se podría mejorar la performance de la bbdd creando un índice sobre el campo CP, sabiendo que es único.
db.stats.createIndex()
Pregunta 6 (1 punto) – Tenemos la siguiente query del aggregation framework que consta de 4 fases:
db.zips.aggregate([
{ $group: {
_id: { comunidad: "$comunidad", ciudad: "$ciudad" },
pop: { $sum: "$poblacion" }
}
},
{ $sort: { pop: 1 } },
{ $group: {
_id: "$_id.comunidad",
biggestCity: { $last: "$_id.ciudad" },
biggestPop: { $last: "$pop" },
smallestCity: { $first: "$_id.ciudad" },
smallestPop: { $first: "$pop" }
}
},
{ $project: {
_id: 0,
state: "$_id",
biggestCity: { name: "$biggestCity", pop: "$biggestPop" },
smallestCity: { name: "$smallestCity", pop: "$smallestPop" }
}
}
])
Explique qué hace cada una de las fases y ponga un ejemplo de documento resultado de cada una de las fases.
La query consta de cuatro fases: dos groups, un sort y un project
en el primer group se agrupan los documentos con la misma comunidad y ciudad y se crea un campo pop suma de las poblaciones en la agrupación
{
"_id": ObjectId("571786ca7fdc0dc3e0631317"),
“ciudad": “Madrid",
“comunidad": “Comunidad de Madrid",
“pop": 3000000,
}
A continuación se ordena de menor a mayor en función de esta suma.
Después, para cada comunidad se realiza otra agrupación sobre el id comundiad, creanod propiedades biggestCity que almecna el idea de la última ciudad, la de mayor población, y de biggestPop, que alamacena su población; y por otro lado las propiedaded de smallestCity y smallestProp
{
"_id": ObjectId("571786ca7fdc0dc3e0631317"),
“comunidad": “Comunidad de Madrid",
“pop": 3000000,
"biggestCity": Madrid,
"biggestPop": 3000000,
"smallestCity": "Jaramillo de Odón" , // Pueblo random que me he inventado
"smallestPop": 3
}
Finalmente, se proyectan estos campos en un documento con una forma parecida a esta:
{
_id: 0,
state: "ObjectId("571786ca7fdc0dc3e0631317")",
biggestCity: { name: "Madrid", pop: 3000000 },
smallestCity: { name: "Jaramillo de Odón", pop: 3 }
}
Pregunta 6 (1 punto dividido en 3 apartados) – Una compañía financiera, dispone de un servicio RESTful Web Server para realizar operaciones CRUD sobre clientes de la empresa. Dicha compañía utiliza mongoDB como sistema de almacenamiento de base de datos. Actualmente, toda la información está almacenada en una única instancia de mongoDB en la base de datos con nombre “company” y colección “clients”. Como medida para asegurar la disponibilidad de acceso a los datos, se plantea replicar los datos en múltiples contenedores con instancias de mongoDB. Pare ellos se muestra el siguiente esquema de despliegue:
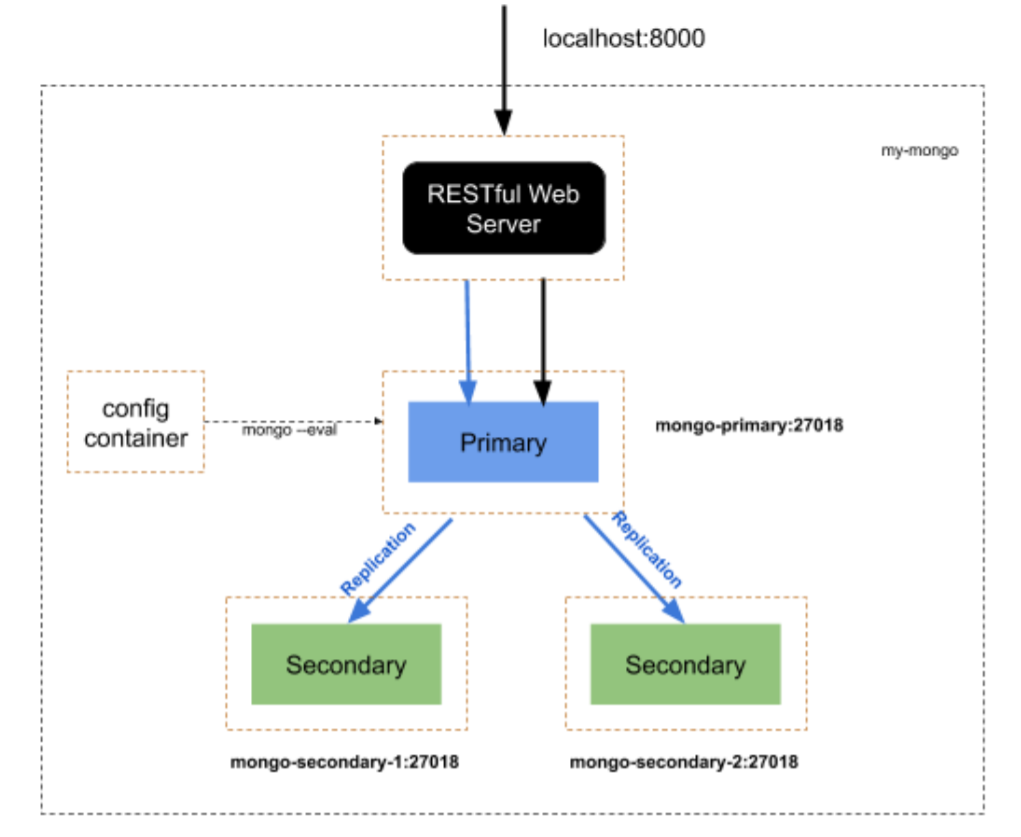
El personal técnico de la empresa se ha encargado ya de definir los servicios de mongo que se necesitan desplegar, por lo que ellos proveen un fichero docker-compose con una serie de servicios preconfigurados para su despliegue. Sin embargo, ellos desconocen cómo se deben configurar las instancias de mongo para que la replicación se haga efectiva. Por lo tanto, se pide:
A) (0.5 puntos) Asignar los valores correspondientes al fichero configure-replica.sh para que se conecte al contenedor mongo-primary e inicie el Replica Set con los valores correspondientes a los servicios mostrados en la figura anterior.
Fichero configure-replica.sh:
#!/bin/bash
# wait until the databases are up and running
sleep 3
# configure the replica set
mongo --host <host> --eval "rs.initiate({
_id : '<replica-set-id>',
protocolVersion: 1,
members: [ { _id : <member_id>, host : '<member_host>'},
{ _id : <member_id>, host : '<member_host>'},
{ _id : <member_id>, host : '<member_host>'}
],
settings: {electionTimeoutMillis: 1000}
})"
En nuestro año no se planteó el despleigue de mongo en replicación con contenedores sino con servicios, de forma que se debe modificar el comando ejemplo para adapatarlo a la práctica.
mongo --host localhost:27001
rs.initiate({
_id : 'my-mongo-set',
members: [
{ _id : 0, host : 'localhost:27002', priority: 900},
{ _id : 1, host : 'localhost:27003'},
{ _id : 2, host : 'localhost:27004', priority: 0, slaveDelay: 60}
]
})
C) (0.2 puntos) Suponiendo que la colección “clients” creciese considerablemente, indique brevemente cómo se podría mejorar el despliegue para que se mejore la velocidad de acceso a los datos.
Pregunta 7 (1.5 puntos en dos apartados): Sobre la aplicación realizada en la última práctica de la asignatura, que utiliza PouchDB y CouchDB: a) Dibuje y explique la arquitectura. (1 punto)
La aplcaición de la última práctica se base en la sigueitne arquitectura: existe un nodo cliente y otro servidor. En el servidor se almacenan los datos en un servidor couchdb, mientras que en el nodo cliente un servidor de puch db(impelmentación en js de couch db hace de bbdd).
pouchdb <-> couchdb
b) Cómo funciona la aplicación cuando no hay conexión de red, es decir cuando el terminal que accede a la aplicación no tiene datos y hace cambios sobre la aplicación. Explique (ayudándose si lo desea de su dibujo del apartado a) cómo funciona cuando no hay conexión de red y qué ocurre cuando se vuelve a estar online. (0,5 puntos)
Cuando no existe conexión de red y se realizan cambios desde la aplciación, se escribe sobre la base de datos del cleinte (pouch db), permitiendo la operación del servicio, auqnue se muestra en la aplcaición que no existe conexión. Una vez se reestablece la conexión, los cambios se replcain en el couch servidor produciéndose archivos de conflicto para gestionarse.
Pregutnas extra de mi cosecha
(0.5 pto) En qué se basa la seguridad de mongo
La seguridad de mongo se basa en tres estrategias: dos de defnesa, tanto autentaición como autorización y una de salvaguarda, el cifrado tanto en reposo como en transporte.
EN cuanto a la autenticación, es decir, el mecanismo para porbar la identidad, se contemplan tres estrategiias: usar un contraseña (SCRAM_SHA-1 o SCRAM-SHA-256), un certificado x.509 o un servidor externo (LDAP o Kerberos).
EN cuanto a la autorizció9n, en mongo no se empela pro defecto; es encesario usar el comoadno --auth. Una vez habilitado el control de acceso los usarios deben autenticarse. Para ello es convenitente definir roles, para otorgar a ciertos usuarios privilegios para realizar acciones sobre ciertos recursos.
Por otro lado, el cifrado de la iofnoramción en transporte se realiza mediante cigrado TLS/SSL y certigfcados; o autofirmados, aunque permite ataques man in the middle, o certificados firamdos por una autoridad de certificaciñib. Se aplcaic este certificado en el fichero de configruación.
Por último, se contempaln dos estrategias para el cifrado de contenidos: o usar la utilidad de mongo enterprise para cifrar el disco o cifrando direcxtamtne el voluemn. Se pude confirar también el cifrado de un campo espec´fifico. TMabién se puede cifrar directamten en el odm, aunque esos camos no pdorán ser accediso mediante la shell.
(0.5 pto) ¿Se puede decir que mongo sea una bbdd durable?
Sí, en mongo se puede configurar el apraámetro writeCOnvcern para hacer que todos los datos se escriban siempre a discos reduciendo la performance.
(0.5 pto) En qué consiste el paradigma PACELC? Cuál es su diferencia frente a CAP?
EL paradigma PACELC, al igual que que el model CAP es un modelo que define ciertas propiedades en un sistema distribuido y propone una explaicción a su fucnioanmeinto.
Este teorema dice:
Si P (eror pro particionamienot de la red) -> o COnsistencia ( manteniento de un estado actualizado) o disponibilidad (mantener la oepración del servcio)
E (else o en caso contrario) -> L (o baja latencia en el acceso) o (consistencai, por ello lata latencia)
Pregunta 1 (1pt) – ¿Qué es un índice de una base de datos? ¿Cuándo necesitaré un índice en una base de datos? Ponga un ejemplo.
Es un valor que permite acceder a los ditintos almacenes de datos. Se necesitará este íodnice para oeoprar sobre la bbdd: por ejemplo en sql los ínidces son las claves primarios y ajenas. En mongo se crean.
Pregunta 2 (1pt) - Modelo ACID. Enúncialo y descríbelo especificando que significa cada letra A, C, I y D.
El modelo ACID describe ciertas carácter´siticas de cómo deben ser las transacciones en los sistemas gestores de basos:
A - atómicas: es decir que no exista estados intermedios entre que una transacción se haya realizado o no
C- consistentes, es diecr que el estado al que se llegue no viole ninguna restricción de integridad.
I - íntiegra: que cada transacción auqnue sea concurrente, sea idnependiente.
D- durable : si las modificaiones que realiza una transacción pueden ser revertidas si el sistema falla.
Pregunta 3 (1pt) - ¿Cuantos tipos de BBDD NoSQL hay? Pon un ejemplo de tecnología de cada una. Sitúa los diferentes tipos sobre un gráfico en el que las Xs son “Complejidad de los datos” y las Ys “Tamaño de los datos”
Se identifican disintos tipos de sistemas gestores de bbdd, y a contianución se organizan estos en un gráfico en el que las X sea la compeljidfad de lso datos e Y sea el tamaño.
Clave valor, columnas, documentos, grafos
Pregunta 4 (1pt) - Explique las ventajas que ofrece el uso de un servicio REST como interfaz para proporcionar acceso a los datos almacenados en una Base de Datos
Fácil intergar con la web.
{
_id: 12345,
nombre: “Enrique Barra",
mote: “Enri”,
sexo: “varón”,
edad: 33,
color_pelo: “negro”,
altura: 183,
calle: “Sor Angela de la Cruz",
numero: 122,
ciudad: “Madrid”,
aficiones: [“tenis”, “baloncesto”, “padel”],
formas_contacto: [{ type: “movil”, content: 659782565}, {type: “tlf”, content: 91253569},
{type: “email”, content: “ebarra@dit.upm.es”}]
}
Sobre esta base de datos se pide lo siguiente: Pregunta 5 (0,5pt) – Escriba una query en MongoDB para obtener el número de personas que tienen como afición el tenis:
db.persona.find({aficiones: {$in: tenis}}).count()
Pregunta 6 (0,5pts) – Escriba una query en MongoDB para obtener el número de personas que miden más de 180cm y tienen igual o menos de 35 años:
db.persona.find({$and: [ {altura: {$gt: 180}}, {edad: {$lte: 35} } ] })
Pregunta 7(0,5pts) - Escriba la query de MongoDB para obtener las 5 personas más altas:
db.persona.sort({altura: 1}).limit(5)
Pregunta 8 (0,5pts)– Queremos cambiar el registro que nos ha devuelto el findOne porque Enrique Barra nos ha notificado de un cambio de dirección. Ahora vive en “Calle Abeto, 15” en “Alcobendas”. Escriba la instrucción en MongoDB para editar el registro introducir estos datos.
db.persona.update( {name: "Enrique Barra"}, {$set: {calle: “Calle Abeto", numero:122, ciudad: "Alcobendas" } )
Pregunta 10 (1pt)- En nuestro sistema tenemos una llamada perdida del número 659232323. Escriba una query en MongoDB para buscar a la/s personas que tengan ese número de móvil.
db.persona.aggregate({ {$match: { formas_contacto.type: {$eq: 659232323}} })
Pregunta 11 (1pt)- Escriba una query que devuelva un documento con un campo “num” con cuantas personas hay y unformat campo “altura_media” con la altura media de las personas que vivan en la calle “Sor Angela de la Cruz” en “Madrid”
Se definen distitnos pipeline para agregar enuna query:
format = {
$project:
}
**Pregunta 12 (1pt) - Sobre la práctica ReplicaSet propuesta en la asignatura: a) Haga un diagrama conceptual del escenario desarrollado. b) Explique qué pasos seguiría (con el detalle de los comandos a ejecutar y ficheros a modificar en su caso) para modificar los datos almacenados en la Base de Datos, prescindiendo por completo de los datos actuales y cargando unos nuevos datos disponibles en un fichero llamado zips_nuevo.json
¿Cuál es la diferencia entre una solución de sistema gestor de base de datos NoSQL y una SQL? ¿Cómo una solución u otra puede ser más aconsejada para distitnos casos de uso?
¿Qué tipos de bases de datos NoSQL hay? Seleccione una: a.Clave-valor, familia de filas, arrays y grafos. n arrays b.Clave-valor, familia de columnas, documentos y grafos. y c.Clave-valor, familia de filas, arrays y matriciales. n matricials d.Clave-valor, familia de filas, documentos y grafos. n familia de filas
¿Qué propiedades propone el modelo ACID que debe cumplir una transacción de una base de datos? Seleccione una: a. Atomicidad, Completitud, Integridad y Durabilidad n compleitud b. Atomicidad, Consistencia, Aislamiento y Durabilidad y c. Atomicidad, Consistencia, Aislamiento y Disponibilidad n disponibilidad d. Atomicidad, Completitud, Integridad y Disponibilidad n completitud
¿Qué tipo de bases de datos NoSQL maneja mayor complejidad de datos? Seleccione una: a. Familia de columnas b. Grafos y c. Documentos d. Clave-valor
¿Qué sistema de consultas (queries) emplean las bases de datos NoSQL? Seleccione una: a. Como su nombre indica son contrarias a SQL y emplean un sistema de consultas alternativo llamado JSON n b. Emplean NoSQL como sistema de consultas alternativo a SQL n c. Tienen un sistema de consultas propio en vez de usar un lenguaje de consultas estándar y
En la pirámide de valor de los datos, ¿Qué encontramos en el nivel más ALTO? Seleccione una: a. Acciones y b. Predicciones n c. Visualización de datos n d. Análisis de datos n e. Captura y muestra de los datos en crudo n
El teorema de CAP recibe críticas por ser considerado simplista. ¿Cómo se llama uno de los teoremas alternativos que está más extendido? Seleccione una: a. Teorema CAP-NoSQL n b. Teorema PACELC y c. Teorema CELIA n d. Teorema CAP II n
¿Cuál de las propiedades del modelo ACID indica que se ejecuta todo o nada? Seleccione una: a. Consistencia n b. Integridad n c. Atomicidad y d. Aislamiento n
Indique si es verdadera o falsa la siguiente afirmación. "BASE es una alternativa flexible a ACID para aquellas bases de datos que no requieren una adherencia estricta a las transacciones y tienen modelos de datos más flexibles" Seleccione una: a. Falso b. Verdadero y
¿Qué significan las letras C, A y P, del teorema de CAP? Seleccione una: a. Completeness, Availability y Persistence n comple b. Completeness, Autenticity y Persistence no comp c. Consistency, Availability y Partition tolerance y d. Consistency, Autenticity y Persistence n pers e. Consistency, Autenticity y Partition no auth
¿Cuáles son las 5 dimensiones o 5 Vs del Big Data? Seleccione una: a. Volumen, Ventaja, Vigilancia, Veracidad y Valor. n b. Volumen, Ventaja, Velocidad, Veracidad y Valor. n c. Volumen, Variedad, Velocidad, Veracidad y Valor.y d. Volumen, Ventaja, Vigilancia, Visibilidad y Valor. n
¿Cuál de las siguientes queries crea un índice sobre el campo autor de la colección posts y asegura que es único? Seleccione una: a. db.posts.createIndex({"author": {"$unique":1} }); n b. db.posts.createIndex({"author": unique }); n c. db.posts.createIndexUnique({"author":1 }); n d. db.posts.createIndex({"author":1 }, {"unique": true}); y
Tenemos una colección estudiantes con un campo array con la nacionalidad, así: {_id: 5, nacionalidad: [“español”, “ingles”], nombre: “pepe”} ¿Cuál de los siguientes comandos encuentra todos los estudiantes que tengan nacionalidad “aleman”: Seleccione una: a. db.students.find( { “nacionalidad.*”: “aleman” }) n b. db.students.find( { “nacionalidad.0”: “aleman” }) n c. n/a d. db.students.findInArray( { nacionalidad: “aleman” }) n e. db.students.find( { nacionalidad: “aleman” }) y
Tengo una colección students ¿Con cuál de las siguientes queries añadiría un campo con clave “mayor” y valor el booleano true a todos los estudiantes que tengan igual o más de 18 años? Seleccione una: a. db.students.update( { { age: {$gt: 18}}}, { $set: { mayor: “true” } }, { multi: true }) n b. n/a c. db.students.update( { { age: {$gte: 18}}}, { $set: { mayor: “true” } }) no multi d. db.students.update( { { gte: {$age: 18}}}, { $set: { mayor: “true” } }) no e. db.students.update( { { age: {$gte: 18}}}, { $set: { mayor: true } }, { multi: true }) y
¿Qué devuelve el siguiente comando? db.students.find( { direccion.numero: 79 ) Seleccione una: a. Todos los estudiantes que tengan un campo llamado “direccion.numero” con valor 79 no b. n/a c. Dará un error de sintaxis al ejecutarse porque al usar la notación punto en la clave es obligatorio ponerla entre comillas y d. Todos los estudiantes que tengan un campo numero con valor 79 n e. Todos los estudiantes que tengan un campo numero con valor 79, estando este número dentro de un objeto con clave “direccion” así: {direccion: {numero: 79}} n
Tengo una colección students ¿Con cuál de las siguientes queries añadiría un campo con clave “pagado” y valor “si” a todos los estudiantes? Seleccione una: a. db.students.update( { * }, { $set: { pagado: “si” } }, { all: true }) no, need multi b. db.students.update( { }, { $set: { pagado: “si” } }, { multi: true }) n c. db.students.update( { * }, { $set: { pagado: “si” } }, { multi: true }) y d. db.students.update( { * }, { $set: { pagado: “si” } }) n e. n/a
Sea una base de datos MongoDB, en la que la respuesta a la query db.products.findOne() devuelve lo siguiente: { _id: "23", price: 55, name: "Kivik", status: "available", pieces: [12, 84, 45] } Que hace la siguiente query MongoDB: db.products.remove({pieces: {$in: [12, 84]}}) Seleccione una: a. Borra los productos que tengan las dos piezas, 12 y 84 n b. Da un error de ejecución porque no ha puesto una condición de búsqueda n c. Borra los productos que tengan una de las piezas 12 u 84 y d. Borra las piezas 12 y 84 de todos los productos n
¿Cuál de los siguientes documentos sería devuelto por la siguiente query? db.users.find( { friends : { $all : [ "Joe" , "Bob" ] }, favorites : { $in : [ "running" , "pickles" ] } } Seleccione una: => los que tengan Joe y bob y tatno uno de los dos en in a. { name : "Cliff" , friends : [ "Pete" , "Joe" , "Tom" , "Bob" ] , favorites : [ "pickles", "cycling" ] } y b.{ name : "Harry" , friends : [ "Joe" , "Bob" ] , favorites : [ "hot dogs", "swimming" ] } n c.{ name : "William" , friends : [ "Bob" , "Fred" ] , favorites : [ "hamburgers", "running" ] }n d.{ name : "Stephen" , friends : [ "Joe" , "Pete" ] , favorites : [ "pickles", "swimming" ] } n
¿Qué devuelve el siguiente comando? db.students.find( { ‘records.0’: ‘passed’ } ) Seleccione una: a.Todos los estudiantes cuyo primer elemento del array “records” contiene el string “passed” y b.n/a c.Todos los estudiantes cuyo array “records” contiene el string “passed” n d.Todos los estudiantes cuyo primer elemento del array “passed” contiene el string “records” n e.Dará un error de sintaxis al ejecutarse porque la clave no se puede escribir con comillas n
En una colección llamada posts que contiene 1000 documentos que hace el siguiente comando? db.posts.find().skip(5).limit(5) Seleccione una: a.Se salta los primeros 5 documentos y devuelve el sexto documento que encuentra en un array repetido 5 veces n b.Skip y limit se anulan uno a otro y por lo tando devuelve los primeros 5 documentos n c.Se salta los primeros 5 documentos y devuelve del 6 al 11 y d.Limita los 5 primeros documentos (gracias a la sentencia limit(5)) y se salta los 5 siguiente, devolviendo del 11 al 15 n
Sea una base de datos MongoDB, en la que la respuesta a la query db.products.findOne() devuelve lo siguiente: { _id: "23", price: 55, name: "Kivik", status: "available", pieces: [12, 84, 45] } Que hacen las siguientes dos queries: db.products.update({name: "Kivik"}, {$pull: {pieces: 12}}, {multi: true} ) db.products.update({{_id: "23"}, {$push: {pieces: 122}}, {multi: true} }) Seleccione una: a.Se sustituye en todos los elementos de nombre "Kivik" la pieza 12 por la 122, n b.Se sustituye en el elemento que había devuelto el findOne() la pieza 12 por la 122, n there's a mult = true c.Se borra de todos los elementos de nombre "Kivik" la pieza número 12 y se inserta en el elemento que había devuelto el findOne() la pieza con id 122 y d.Se sustituye la pieza 12 por la 122 en todos los elementos de la colección n
¿Qué es un indice multiclave en una colección en MongoDB y qué hace falta para crearlo? Seleccione una: a.n/a b.Es un índice sobre varios campos a la vez, sirven para optimizar queries realizadas sobre varios campos, para crearlos solo hay que indicar los campos que se desee así: db.records.createIndex( { name: 1, age: -1 } ) y c.Es un índice sobre un campo que contiene como valor un array, para crearlo usamos la notación punto y la posición del array sobre la que se quiere crear el índice, empezando en 0 la primera posición n no notación punto d.Es un índice sobre un campo que contiene como valor un array, no hace falta hacer nada especial para crearlo, si el campo es array el índice creado sobre ese campo es multiclave n no es un ídnice sobreun campo que continee un array e.Es un índice sobre varios campos a la vez, sirven para optimizar queries realizadas sobre varios campos, para crearlos no hace falta hacer nada especial, si doy dos órdenes createIndex, MongoDB las combina y las optimiza y crea un índice multiclave, n no son dos órdenes create Index
¿Cúal de las siguientes afirmaciones es correcta en cuanto a replicación de líder individual? Seleccione una: a. n/a b. Los seguidores solo pueden usarse para procesar peticiones de escritura, n c. Solo el líder acepta peticiones de escritura, y d. La mayor desventaja del líder individual es la gestión de conflictos, n is the certain latency/less availabilty e. Solo el líder acepta peticiones de lectura, n
El particionamiento con MongoDB es: Seleccione una: a. n/a b. No se puede hacer particionamiento con MongoDB, n c. de líder múltiple asíncrono, n d. Algorítmica, n e. Dinámica pero permite definir un set inicial de shards, y
Si he configurado un replicastet en un conjunto de servidores de MongoDB y luego añado otro usando el siguiente comando en la shell de Mongo: rs.add({ host: "mongodb.net:27017", slaveDelay: 5}) ¿Cuál de las siguientes afirmaciones es correcta ? Seleccione una: a. n/a b. EL nuevo servidor agregado replicará los datos pero con un retardo de 5 segundos. y c. El servido se agrega con una prioridad de 5. n, not priority d. El nuevo servidor forzará la lección de un nuevo primario después de 5 segundos. not leader election e. El servidor pasará a formar parte del conjunto de réplicas después de 5 segundos. n
Si he configurado un replicaset en un conjunto de servidores de MongoDB y luego se quiere añadir otro servidor como Arbitro, ¿Cuál de los siguientes comandos es válido para realizar ese procedimiento?: Seleccione una: a. rs.add({ host: "mongodb.net:27017", arbiterOnly: 5}) n b. rs.add({ host: "mongodb.net:27017", priority: 5}) n c. rs.add({ host: "mongodb2.example.net:27017",hidden:true}) n d. rs.addArb("mongodb2.example.net:27017") y e. n/a
¿Cúal de las siguientes afirmaciones sobre Particionamiento es correcta? Seleccione una: a. No se puede aplicar replicación a datos particionados n b. Todas las escrituras van al nodo primario. n c. En la partición algorítmica, se usa un servicio de localización para ubicar los datos n d. Cumple el requisito de aumento del tamaño de los datos (escalado horizontal). y e. n/a
¿El siguiente código permite establecer una conexión a una base de datos llamada test en MongoDB : var mongoose = require('mongoose'); mongoose.connect('mongodb://localhost/test'); Si esa base de datos no ha sido creada previamente , ¿Cuál de las siguientes afirmaciones sería correcta? Seleccione una:
a. La aplicación devuelve un error de sintaxis. n b. Al momento de establecer la conexión se crea esa base de datos, si esta no existe previamente. n c. Se muestra un error en el terminal indicando que la base de datos no existe. n d. La aplicación devuelve un mensaje de error de "Connection refused" y e. n/a
Para crear el esquema llamado 'UserSchema' con Moongosoe, con los campos nombre, apellido y edad, debemos ejecutar: Seleccione una: a. const UserSchema = new mongoose.Schema([ nombre, apellido, edad] ) n b. n/a c. const UserSchema = new mongoose.Schema({ nombre: String, apellido: String, edad: Number}) y d. const UserSchema = new mongoose.InsertIntoSchemas({ nombre: String, apellido: String, edad: Number}) n e. const UserSchema = new User({ nombre: String, apellido: String, edad: Number}) n
Tenemos un modelo de usuarios llamado “User" con atributos “id", “nombre" y “edad". Nuestra aplicación usa Mongoose como ODM para gestionar los datos. Si quiero borrar todos los usuarios cuyo nombre es igual a "carlos" tengo que escribir?: Seleccione una: a. await User.deleteOne({where: {nombre: "Carlos"}}); n b. n/a c. await User.deleteMany({if: {nombre: "Carlos"}}); n d. await User.deleteMany({nombre: "Carlos"}); y e. await User.deleteOne({nombre: "Carlos"}); n
La replicación con MongoDB es: Seleccione una: a. n/a b. De líder individual síncrona m c. de líder múltiple m d. No se puede hacer replicación con MongoDB n e. De líder individual asíncrona y
Tenemos un modelo de usuarios llamado “User" con atributos “id", “nombre" y “edad". Nuestra aplicación usa Mongoose como ODM para gestionar los datos. Si quiero buscar todos los usuarios cuya edad es 15 ¿Que tengo que escribir? Seleccione una: a. n/a b. await User.save({ edad: 15 } n c. await User.findOne({ edad: 15 } n d. await User.deleteMany({ edad: 15 } n e. await User.find({ edad: 15 }) y