In this workshop, you will learn about Azure Synapse Link for Azure Cosmos DB. We will go through some of the notebooks from the official samples repository - https://aka.ms/cosmosdb-synapselink-samples
It will cover:
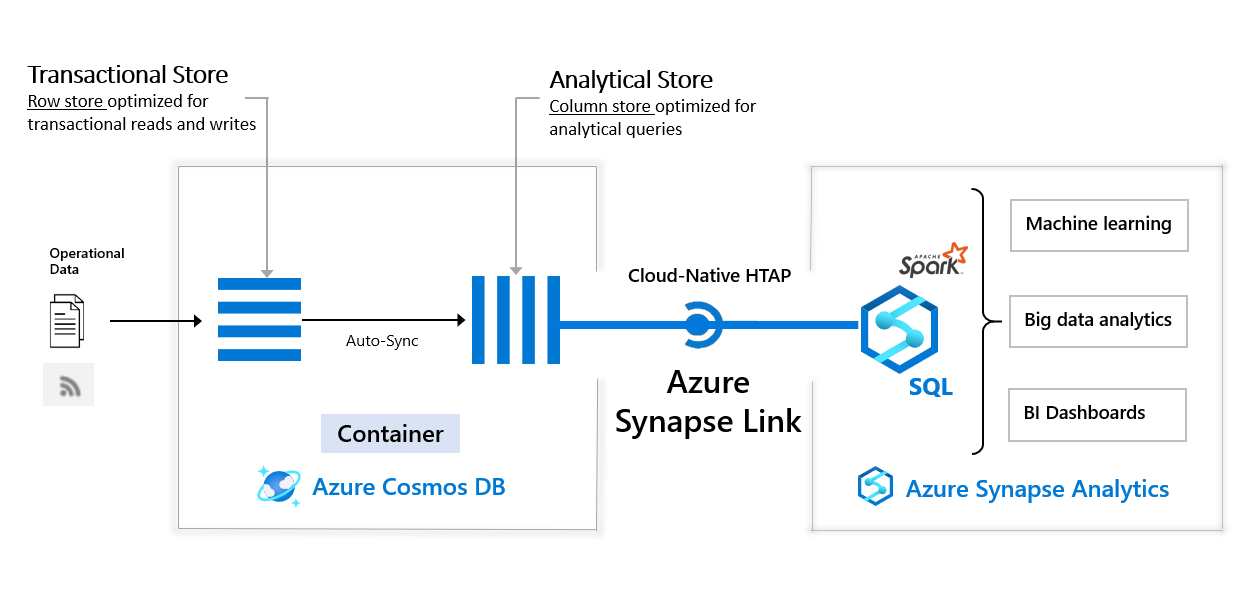
- Azure Cosmos DB and how it integrates with Azure Synapse Analytics using Azure Synapse Link.
- Basic operations such as setting up Azure Cosmos DB and Azure Synapse Analytics. Creating Azure Cosmos DB containers, setting up Linked Service.
- Scenarios with examples
- Batch Data Ingestion leveraging Synapse Link for Azure Cosmos DB and performing operations across Azure Cosmos DB containers
- Streaming ingestion into Azure Cosmos DB collection using Structured Streaming
- Getting started with Azure Cosmos DB's API for MongoDB and Synapse Link
If you want to go back and learn some of the foundational concepts, the following resources might be helpful:
- Key Azure Cosmos DB concepts and how to choose the appropriate API for Azure Cosmos DB
- Basic terminology associated with Azure Synapse Analytics
- A Learn Module that covers the features, components that Azure Synapse Analytics provides
- An overview of Azure Synapse Link for Azure Cosmos DB and how to configure and enable Azure Synapse Link to interact with Azure Cosmos DB.
The steps outlined in this section have completed in advance to save time. The following resources are already available:
- Azure Cosmos DB accounts (Core SQL API, Mongo DB API)
- Azure Synapse Analytics workspace along with a Apache Spark pool
You can use an existing Azure account or create a free account using this link
First things first, create a Resource Group to host the resources used for this workshop. This will make it easier to manage them and clean-up once you're done.
Azure Cosmos DB
- Create an Azure Cosmos DB SQL (CORE) API account. For the purposes of this workshop, please choose All networks as the Connectivity method option (in the Networking section of the create account wizard)
- Create an Azure Cosmos DB API for MongoDB account. For the purposes of this workshop, please choose All networks as the Connectivity method option (in the Networking section of the create account wizard)
- For both the accounts (Core SQL and MongoDB), enable Synapse Link for Azure Cosmos DB
Azure Synapse Analytics
- Create an Azure Synapse Workspace. Please ensure that you select the checkbox
Assign myself the Storage Blob Data Contributor role on the Data Lake Storage Gen2 accountin the creation wizard - Create an Azure Synapse Analytics Spark Pool
For Azure Cosmos DB Core SQL API account:
Create Azure Cosmos DB database (named RetailSalesDemoDB) and three containers (StoreDemoGraphics, RetailSales, and Products). Please make sure to:
- Set the database throughput to
Autoscaleand set the limit to40000instead of400, this will speed-up the loading process of the data, scaling down the database when it is not in use (check the documentation on how to set throughput) - Use /id as the Partition key for all 3 containers.
- Analytical store is set to On for all 3 containers.
For Azure Cosmos DB MongoDB API account:
Create a database named DemoSynapseLinkMongoDB along with a collection named HTAP with a Shard key called item. Make sure you set the Analytical store option to On when you create your collection.
- Create a "Linked Service" for the Azure Cosmos DB SQL API in Azure Synapse workspace - for this demo, we use the name
RetailSalesDemoDB - Load batch data in the Azure Data Lake Storage Gen2 account associated with your Azure Synapse Analytics workspace. Create a
RetailDatafolder within the root directory of the storage account. Download these csv files to your local machine and upload them to theRetailDatafolder you just created.
You're all set to try out the Notebooks!
Batch Data Ingestion leveraging Synapse Link for Azure Cosmos DB
We will go through how to ingest batch data into Azure Cosmos DB using using Synapse using this notebook.
Clone or download the content from the samples repo, navigate to the Synapse/Notebooks/PySpark/Synapse Link for Cosmos DB samples/Retail/spark-notebooks/pyspark directory and import the 1CosmoDBSynapseSparkBatchIngestion.ipynb file into your Azure Synapse workspace
To learn more, read up on how to Create, develop, and maintain Synapse Studio notebooks in Azure Synapse Analytics
Join data across Cosmos DB containers
Clone or download the content from the samples repo, navigate to the Synapse/Notebooks/PySpark/Synapse Link for Cosmos DB samples/Retail/spark-notebooks/pyspark directory and import the 2SalesForecastingWithAML.ipynb file into your Azure Synapse workspace
Streaming ingestion into Azure Cosmos DB collection using Structured Streaming
We will explore this notebook to get an overview of how to work with streaming data using Spark.
Clone or download the content from the samples repo, navigate to the Synapse/Notebooks/PySpark/Synapse Link for Cosmos DB samples/IoT/spark-notebooks/pyspark directory and import the 01-CosmosDBSynapseStreamIngestion.ipynb file into your Azure Synapse workspace
Getting started with Azure Cosmos DB's API for MongoDB and Synapse Link
We will explore this notebook. Since it uses specific Python libraries you will need to upload the requirements.txt file located in Synapse/Notebooks/PySpark/Synapse Link for Cosmos DB samples/E-Commerce/spark-notebooks/pyspark directory to install these to your Spark pool packages.
Here is detailed write-up on how to Manage libraries for Apache Spark in Azure Synapse Analytics
Clone or download the content from the samples repo, navigate to the Synapse/Notebooks/PySpark/Synapse Link for Cosmos DB samples/E-Commerce/spark-notebooks/pyspark directory and import the CosmosDBSynapseMongoDB.ipynb file into your Azure Synapse workspace.
That's all for this workshop. I encourage you to go through the rest of this lab which includes using AutoML in Azure Machine Learning to build a Forecasting Model.
Delete the Azure Resource Group. This will delete all the resources inside the resource group.
- Learn more about the use cases for Apache Spark in Azure Synapse Analytics, including Data Engineering, Machine Learning etc.
- Learn how to enrich data in Spark tables with new machine learning models that you train using AutoML in Azure Machine Learning
- A dedicated, multi-module Learning Path to guide you through how to Perform data engineering with Azure Synapse Apache Spark Pools
- Use this tutorial to try out how to query data in CSV, Apache Parquet, and JSON files using SQL Serverless pool in Azure Synapse Analytics.