Remember to git add && git commit && git push each exercise!
We will execute your function with our test(s), please DO NOT PROVIDE ANY TEST(S) in your file
For each exercise, you will have to create a folder and in this folder, you will have additional files that contain your work. Folder names are provided at the beginning of each exercise under submit directory and specific file names for each exercise are also provided at the beginning of each exercise under submit file(s).
| My Mr Clean | |
|---|---|
| Submit directory | . |
| Submit file | my_mr_clean.ipynb |
It is time to get our hands dirty and to manipulate some real world data. You have been hired by a new company named EncyclEarthpedia and your first task it build a search engine. EncyclEarthpedia is an online encyclopedia but specialized in the planet Earth, its geology, biology, and everything related to the Earth.
The search engine should be simple at first. The user needs to be able to type some words and the engine returns the most relevant articles.
There is a problem though. The engineers working on the database messed up and EncyclEarthpedia's database and API are not available for a week. This is a bummer ! If we can't have access to the articles, how are we going to build our engine ?
Instead of waiting for a week, we are going to build a simple model for some similar article from Wikipedia.
What we are going to do is:
- Get some article from Wikipedia to work with.
- Extract meaningful and usable content from this article.
- Clean up and filter the data to narrow the scope to relevant words
- Build a simple frequency model.
- Analysing the article based on this model.
This first work of this article would be the start of our search engine, using some notion from Information Retrieval and tf-idf statistic.
We are going to work with an article about the Ozone Layer.
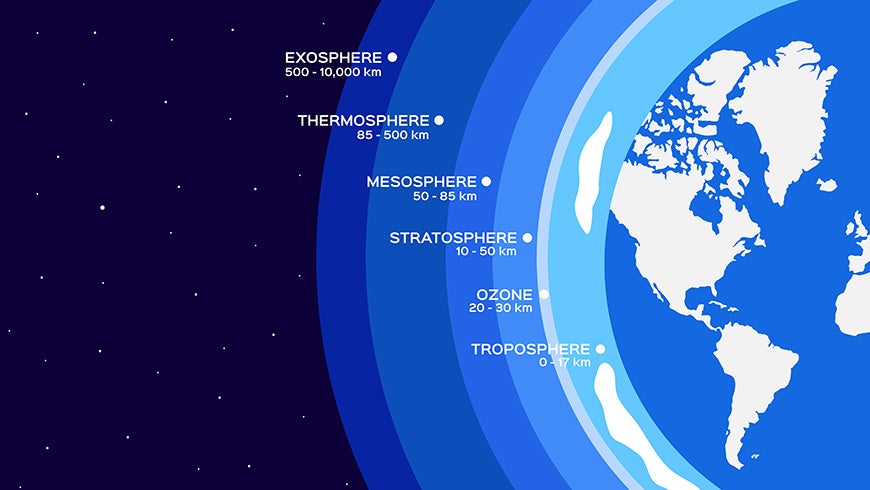
First things first: Let's get the content of this article into code variables.
→ Use Wikipedia's API to retrieve the content of the article
Create a function get_content(article_name) to retrieve information about an article.
→ Using pip install wikipedia and import wikipedia is strictly forbidden!
Printing your result, you should see something similiar to:
data = get_content("Ozone_layer") print(data){'batchcomplete': True, 'query': {'normalized': [{'fromencoded': False, 'from': 'Ozone_layer', 'to': 'Ozone layer'}], 'pages': [{'pageid': 22834, 'ns': 0, 'title': 'Ozone layer', 'revisions': [{'slots': {'main': {'contentmodel': 'wikitext', 'contentformat': 'text/x-wiki', 'content': '{{pp-semi-indef}} {{short description|Region of Earths stratosphere that absorbs most of the Suns ultraviolet radiation}} [[File:Ozone cycle.svg|thumb|upright=1.5|[[Ozone-oxygen cycle]] in the ozone layer.]]
The ozone layer or ozone shield is a region of [[Earth]]s [[stratosphere]] that absorbs most of the [[Sun]]s [[ultraviolet]] radiation. It contains a high concentration of [[ozone]] (O<sub>3</sub>) in relation to other parts of the atmosphere, although still small in relation to other gases in the stratosphere. The ozone layer contains less than 10 parts per million of ozone, while the average ozone concentration in Earths atmosphere as a whole is about 0.3 parts per million. The ozone layer is mainly found in the lower portion of the stratosphere, from approximately {{convert|15|to|35|km|sp=us}} above Earth, although its thickness varies seasonally and geographically.<ref>{{cite web|url=http://www.ozonelayer.noaa.gov/science/basics.htm|title=Ozone Basics|website=NOAA|date=2008-03-20|access-date=2007-01-29|archive-url=https://web.archive.org/web/20171121051325/http://www.ozonelayer.noaa.gov/science/basics.htm|archive-date=2017-11-21|url-status=dead}}</ref>
The ozone layer was discovered in 1913 by the French physicists [[Charles Fabry]] and [[Henri Buisson]]. Measurements of the sun showed that the radiation sent out from its surface and reaching the ground on Earth is usually consistent with the spectrum of a [[black body]] with a temperature in the range of 5,500–6,000 K (5,227 to 5,727 °C), except that there was no radiation below a wavelength of about 310 nm at the ultraviolet end of the spectrum. It was deduced that the missing radiation was being absorbed by something in the atmosphere.
As you may have notice, the answer from the API is not very user-friendly. It is a big json objects with many keys and values that are not really relevant for us. What we really want to work with is the actual 'content' of the article. But what do we mean by "content" ? Are the titles or the table of contents useful? (yes). Are the hidden URL relevant to us?
Only the actual content interests us so we need somehow to remove all the flourish like markups, the urls, and any useless words or characters.
→ First merge and store all the meaningful contents from the big json into a handy variable. Any kind of data structure can be used. A simple list would do the trick though
def merge_contents(data): ...merge_content = merge_contents(data)
Now that we retrieve all the contents in one place, it is time to dissect our data and build a list of all the words.
Usually a word is delimited by a space or a new line. With this rule, "Ozone-oxygen" is a word. But it means that "Ozone", "Oxygen", and "Ozone-oxygen" are three different words. Yet, if the end user type "Ozone" or "Ozone-oxygen" in the search bar, the same results should appear for both searchs! Personally, I think "Ozone-oxygen" should be broken into two words. But you might have another opinion!
→ Create a list of the "splitter" char. For example, if you think words should be delimited by spaces and new lines, your list is [" ", "\n"].
Now that you defined the words delimiters, let's tokenize our content.
→ Traverse your brand new data structure and tokenize the words: Create a list of all the words.
def tokenize(content): ...
collection = tokenize(merge_content)
Because we do not make any difference between Ozone or ozone or OZONE, a good idea is to have all words in lower case.
→ Update the collection of words for them to be only lower case.
def lower_collection(collection): ...lower_collection(collection)
From here, let's step back a little bit and recall what is our objectives. A search engine should find relevant articles based on words in a search bar. In this project we will build a simple frequency model. In other words, given a word, we need to find the articles in which this word is the most frequent. Let's build a frequency model.
→ Write a function to count the number of occurrences of each word in the collection.
→ What are the most frequent words? Write a function to print the n most frequent words along with their frenquency.
def count_frequency(collection): ...def print_most_frequent(frequencies, n): ...
frequencies = count_frequency(collection)
print_most_frequent(frequencies, 10)
Printing the most frequent words is a good way to get a feel of the words distribution, but is not very telling.
→ Visualize the 20 most frequent words by plotting them in a histogram.
Here is the visualization of the most frequent words from the introduction of the article:
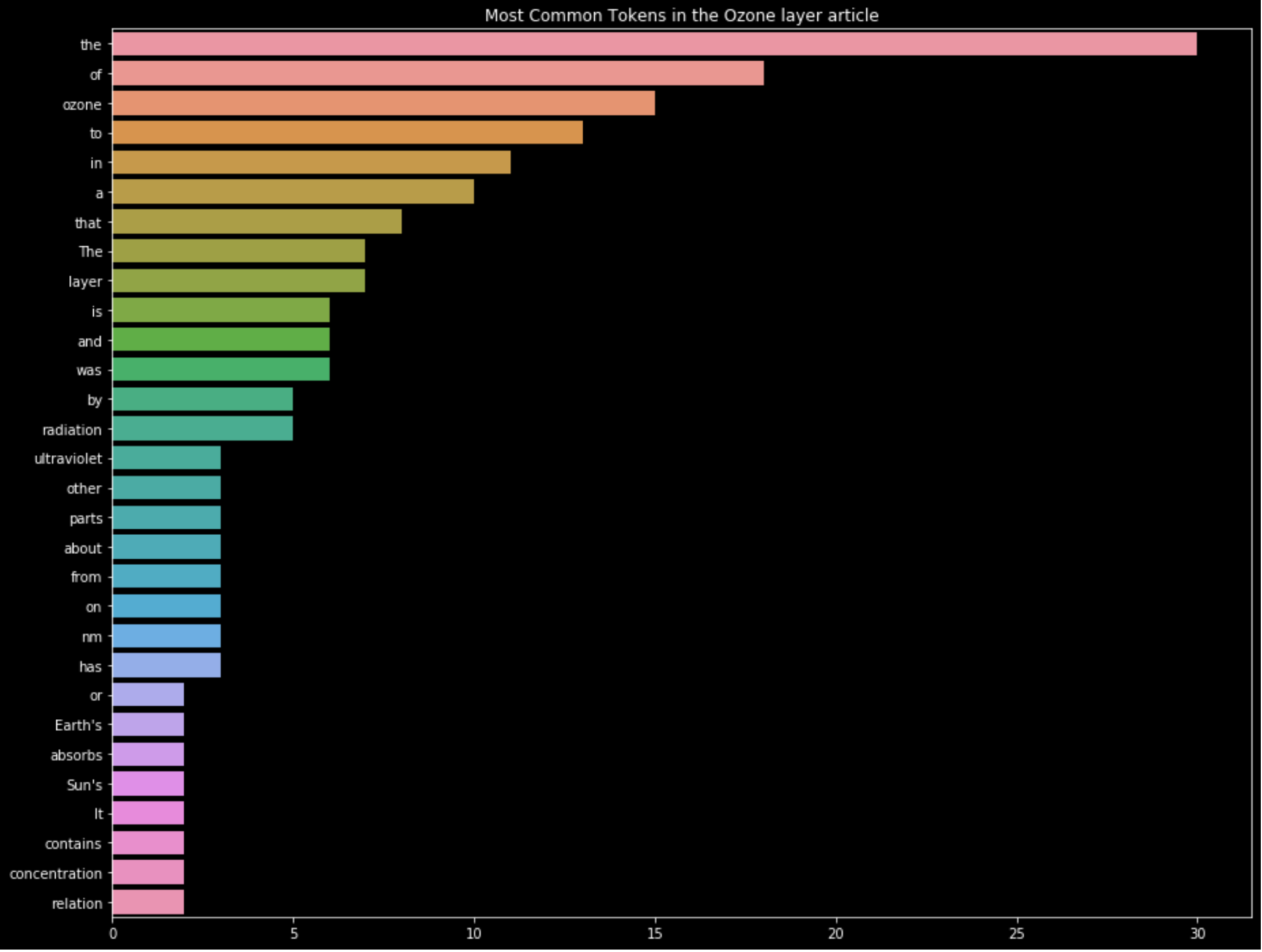
But all the words are not equal. Some words have less importance than others. As we can see on the graph, determiners and articles do not really help understanding the topic of an article or a corpus. In the 10 most frequent words from the introduction, we see that only 2 of them are really useful to classify the article: "ozone" and "layer".
These "unsignificant" little words are called stop words.
→ Create a list of stop words to remove from the list of words.
stop_words = [ "the", "a", "of", "to", "in", "about" ... ]
→ Write a function 'remove_stop_words' that takes as parameters a list of tokens, removes the empty words provided this list and returns the new list resulting from this filtering.
def remove_stop_words(words, stop_words): ...filtered_collection = remove_stop_words(collection, stop_words)
→ Visualize now in a historgram the 25 most frequent words in the filtered collection.
The most frequent words should be more relevant to match this Ozone layer article content. If the user's search is made of the words "Ozone" and "gas", we can vectorize articles and represent them with a vector of size 2. The coefficient of the vectorized article would be the frequencies of the words from the search. By vectorizing all articles this way, we can build some kind of distance between articles. Another data engineering technique we could have had explored is stemming to get even more insight about the article.
Here ends our little journey into data exploration and information retrieval. If the database engineers of our team are ready, we can use some of the techniques we have seen to build up a small proff of concept!