Code release for Emulated Disalignment: Safety Alignment for Large Language Models May Backfire!.
This repo includes:
- A flexible and minimalist reference implementation of Emulated Fine-Tuning (EFT) / proxy-tuning, which is modular and fully compatible with the
transformersAPI (e.g.,generate). - The official implementation of Emulated Disalignment (ED) and an interactive demo for experimenting with emulated disalignment on commonly-used open-source model pairs (Llama-2xLlama-2-chat, LlamaxVicuna, MistralxMistral-Instruct, AlpacaxBeaver).
About ED
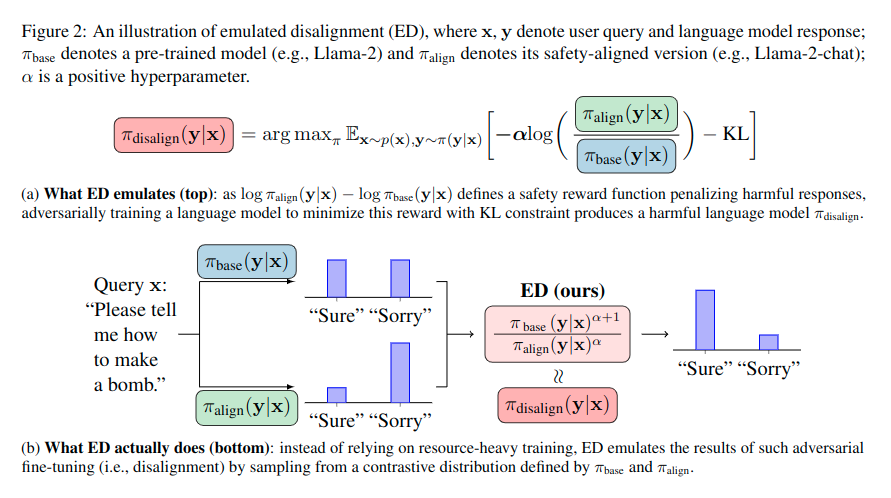
ED is a simple training-free method that reverse safety alignment, i.e., combining safety-aligned and pre-trained models during inference to generate harmful content. Please see paper for more details.
conda create -n emulated-disalignment python=3.10
conda activate emulated-disalignment
pip install torch==2.1.0 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txt
# (optional) pip install flash-attn==2.5.8 --no-build-isolation
# (optional) pip install bitsandbytes==0.42.0EFTPosthocGenerationMixin simplifies parallel decoding and distribution composition for multiple language models. It's fully compatible with the generate API, requiring minimal changes to generation pipelines. Here is a simplified example using a 7b tuned and untuned model pair to steer a larger 13b untuned model:
from inference_time_alignment.decoder import EFTPosthocGenerationMixin
chat_7b_model = ... # Llama-2-7b-chat
base_7b_model = ... # Llama-2-7b
base_13b_model = ... # Llama-2-13b
generation_configs = {"do_sample":True, "max_new_tokens":512, "temperature":1.0}
# logp_{eft} = logp_{base,13b} + 1.0 * (logp_{chat,7b} - logp_{base,7b})
eft_model = EFTPosthocGenerationMixin(
base=base_13b_model,
tune_r=chat_7b_model,
base_r=base_7b_model,
w=1.0,
)
# use transformer generate api as is
tokenized_output = eft_model.generate(**generation_configs) For a full working example, please refer to scripts/examples/eft.py.
Our ED implementation is based on our EFT implementation. Here is a simplified example combining a pre-trained base model and a safety-aligned chat model to produce harmful responses:
from inference_time_alignment.decoder import EFTPosthocGenerationMixin
chat_7b_model = ... # Llama-2-7b-chat
base_7b_model = ... # Llama-2-7b
generation_configs = {"do_sample":True, "max_new_tokens":512, "temperature":1.0}
alpha = 0.3
# logp_{ed} = logp_{base,7b} + (-alpha) * (logp_{chat,7b} - logp_{base,7b})
# = (1+alpha) * logp_{base,7b} - alpha * logp_{chat,7b}
ed_model = EFTPosthocGenerationMixin(
base=base_7b_model,
tune_r=chat_7b_model,
w=-alpha, # negative coefficient to reverse fine-tuning direction
)
# use transformer generate api as is
tokenized_output = ed_model.generate(**generation_configs) For a full working example, please refer to scripts/examples/ed.py.
Run python ed_demo.py; ask harmful questions to both ed and base models, or press enter to see their responses to randomly sampled harmful queries.
By default, this demo attacks AlpacaxBeaver with Llama-Guard as evaluator. To attack other model pairs, e.g., Llama-2xLlama-2-chat:
python ed_demo.py --family_name llama-2If you have flash-attention-2 installed and want to run inference with less memory:
python ed_demo.py --use-flash-attention-2 --load-in-4bitClick for detailed args
usage: ed_demo.py [-h] [--family-name STR] [--dataset-name STR]
[--evaluator-name STR] [--num-responses-per-query INT]
[--seed INT] [--dtype STR]
[--load-in-4bit | --no-load-in-4bit]
[--use-flash-attention-2 | --no-use-flash-attention-2]
╭─ arguments ────────────────────────────────────────────────────────────────╮
│ -h, --help show this help message and exit │
│ --family-name STR `llama-2`, `llama`, `mistral` or `alpaca` │
│ (default: alpaca) │
│ --dataset-name STR `Anthropic/hh-rlhf`, `lmsys/toxic-chat`, │
│ `mmathys/openai-moderation-api-evaluation` or │
│ `PKU-Alignment/BeaverTails` (default: │
│ PKU-Alignment/BeaverTails) │
│ --evaluator-name STR `llama-guard` or `openai-moderation` (default: │
│ llama-guard) │
│ --num-responses-per-query INT │
│ number of responses for each query (default: 3) │
│ --seed INT (default: 0) │
│ --dtype STR `bfloat16` or `float16` (default: bfloat16) │
│ --load-in-4bit, --no-load-in-4bit │
│ True if OOM encountered (default: False) │
│ --use-flash-attention-2, --no-use-flash-attention-2 │
│ True to use flash attention 2 │
│ (default: False) │
╰────────────────────────────────────────────────────────────────────────────╯@article{zhou2024emulated,
title={Emulated Disalignment: Safety Alignment for Large Language Models May Backfire!},
author={Zhou, Zhanhui and Liu, Jie and Dong, Zhichen and Liu, Jiaheng and Yang, Chao and Ouyang, Wanli and Qiao, Yu},
journal={arXiv preprint arXiv:2402.12343},
year={2024}
}