当前branch为V2版本,为CTC+translate结构
欢迎使用并反馈bug
旧版请看 V1版本
Aishell-1 上训练结果:
离线结果
| Name | 参数量 | 中文CER | 训练轮数 | online/offline | 测试数据 | 解码方式 |
|---|---|---|---|---|---|---|
| Wenet(Conformer) | 9.5M | 6.48% | 100 | offline | aishell1-test | ctc_greedy |
| Wenet(transformer) | 9.7M | 8.68% | 100 | offline | aishell1-test | ctc_greedy |
| Wenet(Paraformer) | 9.0M | 6.99% | 100 | offline | aishell1-test | paraformer_greedy |
| FunASR(Paraformer) | 9.5M | 6.37% | 100 | offline | aishell1-test | paraformer_greedy |
| FunASR(Conformer) | 9.5M | 6.64% | 100 | offline | aishell1-test | ctc_greedy |
| FunASR(e_branchformer) | 10.1M | 6.65% | 100 | offline | aishell1-test | ctc_greedy |
| repo(ConformerCTC) | 10.1M | 6.8% | 100 | offline | aishell1-test | ctc_greedy |
流式结果
| Name | 参数量 | 中文CER | 训练轮数 | online/offline | 测试数据 | 解码方式 |
|---|---|---|---|---|---|---|
| Wenet(U2++Conformer) | 10.6M | 8.18% | 100 | online | aishell1-test | ctc_greedy |
| Wenet(U2++transformer) | 10.3M | 9.88% | 100 | online | aishell1-test | ctc_greedy |
| repo(StreamingConformerCTC) | 10.1M | 7.2% | 100 | online | aishell1-test | ctc_greedy |
| repo(ChunkConformer) | 10.7M | 8.9% | 100 | online | aishell1-test | ctc_greedy |
- VAD+降噪
- 在线流式识别/离线识别
- 标点恢复
- TTS数据增强
- 音色转换数据增强
- 远近场数据增强
TTS:https://github.com/Z-yq/TensorflowTTS
NLU: -
BOT: -
没有数据也可以达到一定水平的ASR效果哟。
针对ASR的TTS:训练数据为aishell1和aishell3,数据类型比较适合ASR。
tips:
-
一共有500个音色
-
仅支持中文
-
如果待合成文本有标点符号请手动去除
-
如果想添加停顿,请在文本中间添加sil
step1: 准备一个待合成的文本列表,假如命名为text.list, egs:
这是第一句话
这是第二句话
这是一句sil有停顿的话
...
step2: 下载model
链接:https://pan.baidu.com/s/1deN1PmJ4olkRKw8ceQrUNA 提取码:c0tp
两个都要下载,然后放到目录 ./augmentations/tts_for_asr/models 下面
step3: 然后在根目录下运行脚本:
python ./augmentations/tts_for_asr/tts_augment.py -f text.list -o save_dir --voice_num 10 --vc_num 3其中:
-f 是step1准备的列表
-o 用于保存合成的语料路径,建议是绝对路径。
--voice_num 每句话用多少个音色合成
--vc_num 每句话使用音色转换增强多少次
运行完毕后,会在 -o 下生成wavs目录和utterance.txt
参照librosa库,用TF2实现了语音频谱特征提取的层。
或者可以使用更小参数量的Leaf 。
使用:
- am_data.yml
mel_layer_type: Melspectrogram #Spectrogram/leaf trainable_kernel: True #support train model,not recommend
已经更新基于ONNX的CPP项目,
基于ONNX的python inference方案,详情见python inference
现在支持流式的Conformer结构啦。
当前实现了两种方式:
-
Block Conformer + Global CTC
- 可用于有VAD的短时识别系统,global CTC 来构建上下文信息。
-
Chunk Conformer + CTC Picker
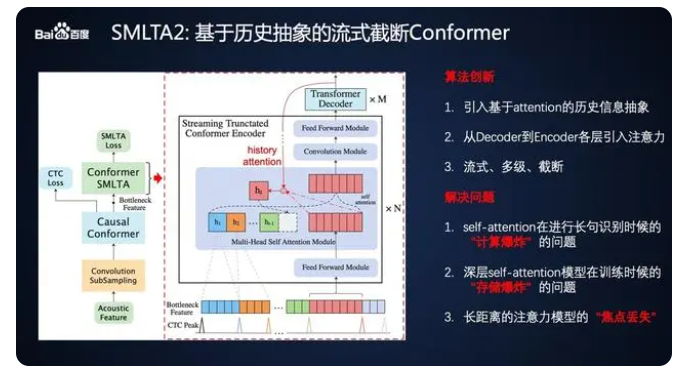
- 参考了百度的SMLTA2,先利用音素CTC采样出有效的Feature,再给到lookahead的chunk conformer进行上下文信息构建做出预测。可用于长时间的流式识别系统。

同epoch训练下,Block Conformer和全局conformer的CER仅差0.8%。
Causal Chunk Conformer做了存储管理,默认配置下一次推理的算力消耗是 350MFlops。
两种方式的逻辑如图:

所有结果测试于 AISHELL TEST 数据集.
RTF(实时率) 测试于CPU单核解码任务。
AM:
| Model Name | Mel layer(USE/TRAIN) | link | code | train data | phoneme CER(%) | Params Size | RTF |
|---|---|---|---|---|---|---|---|
| ConformerCTC(S) | True/False | pan.baidu.com/s/1k6miY1yNgLrT0cB-xsqqag | 8s53 | aishell-1(50 epochs) | 6.4 | 10M | 0.056 |
| StreamingConformerCTC | True/False | pan.baidu.com/s/1Rc0x7LOiExaAC0GNhURkHw | zwh9 | aishell-1(50 epochs) | 7.2 | 15M | 0.08 |
| ChunkConformer | True/False | pan.baidu.com/s/1o_x677WUyWNld-8sNbydxg | ujmg | aishell-1(50 epochs) | 11.4 | 15M | 0.1 |
VAD:
| Model Name | link | code | train data | params size | RTF |
|---|---|---|---|---|---|
| 8k_online_vad | pan.baidu.com/s/1ag9VwTxIqW4C2AgF-6nIgg | ofc9 | openslr开源数据 | 80K | 0.0001 |
Punc:
| Model Name | link | code | train data | acc | params size | RTF |
|---|---|---|---|---|---|---|
| PuncModel | pan.baidu.com/s/1gtvRKYIE2cAbfiqBn9bhaw | 515t | NLP开源数据 | 95% | 600K | 0.0001 |
使用:
test_asr.py 中将model转成onnx文件放入pythonInference中
欢迎加入,讨论和分享问题。 群已满200人需邀请进入,请添加备注"TensorflowASR"。

最新更新
- 🥇 [2023.04.18]更新了Chunk Conformer结构,适合长时流式ASR场景。
- CTC+Streaming
- Conformer
- BlockConformer
- ChunkConformer
- Python 3.6+
- Tensorflow 2.8+:
pip install tensorflow-gpu 可以参考 https://www.bilibili.com/read/cv14876435 - librosa
- pypinyin
if you need use the default phoneme - keras-bert
- addons
For LAS structure,pip install tensorflow-addons - tqdm
- tf2onnx
- rir_generator
pip install rir-generator - onnxruntime
pip install onnxruntime or pip install onnxruntime-gpu
-
准备train_list和test_list.
asr_train_list 格式,其中'\t'为tap,建议用程序写入一个文本文件中,路径+'\t'+文本
wav_path="xxx/xx/xx/xxx.wav" wav_label="这是个例子" with open('train.list','w',encoding='utf-8') as f: f.write(wav_path+'\t'+wav_label+'\n') :
例如得到的train.list:
/opt/data/test.wav 这个是一个例子 ......
以下为vad和标点恢复的训练数据准备格式(非必需):
vad_train_list 格式:
wav_path1
wav_path2
……
例如:
/opt/data/test.wav
vad训练内部处理逻辑是靠能量做训练样本,所以确保你准备的训练语料是安静条件下录制的。
punc_train_list格式:
text1
text2
……
同LM的格式,每行的text包含标点,目前标点只支持每个字后跟一个标点,连续的标点视为无效。
比如:
这是:一个例子哦。 √(正确格式)
这是:“一个例子哦”。 ×(错误格式)
这是:一个例子哦“。 ×(错误格式)
-
下载bert的预训练模型,用于标点恢复模型的辅助训练,如果你不需要标点恢复可以跳过:
https://pan.baidu.com/s/1_HDAhfGZfNhXS-cYoLQucA extraction code: 4hsa -
修改配置文件
am_data.yml(./asr/configs)来设置一些训练的选项,以及修改model yaml(如:./asr/configs/conformer.yml) 里的name参数来选择模型结构。 -
然后执行命令:
python train_asr.py --data_config ./asr/configs/am_data.yml --model_config ./asr/configs/ConformerS.yml
-
想要测试时,可以参考
./test_asr.py里写的demo,当然你可以修改stt方法来适应你的需求:python ./test_asr.py
也可以使用Tester 来大批量测试数据验证你的模型性能:
执行:
python eval_am.py --data_config ./asr/configs/am_data.yml --model_config ./asr/configs/ConformerS.yml该脚本将展示 SER/CER/DEL/INS/SUB 几项指标
6.训练VAD或者标点恢复模型,请参照以上步骤。
如果你想用你自己的音素,需要对应 am_dataloader.py 里的转换方法。
def init_text_to_vocab(self):#keep the name
def text_to_vocab_func(txt):
return your_convert_function
self.text_to_vocab = text_to_vocab_func #here self.text_to_vocab is a function,not a call不要忘记你的音素列表用 <S> 和 </S> 打头,e.g:
<S>
</S>
de
shì
……
参考了以下优秀项目:
https://github.com/usimarit/TiramisuASR
https://github.com/noahchalifour/warp-transducer
https://github.com/PaddlePaddle/DeepSpeech
https://github.com/baidu-research/warp-ctc
允许并感谢您使用本项目进行学术研究、商业产品生产等,但禁止将本项目作为商品进行交易。
Overall, Almost models here are licensed under the Apache 2.0 for all countries in the world.
Allow and thank you for using this project for academic research, commercial product production, allowing unrestricted commercial and non-commercial use alike.
However, it is prohibited to trade this project as a commodity.