RNN-Transducer
| Description | Feature | Dataset | CER |
|---|---|---|---|
| Spec_Augment + RNN-T | log_feature_161 | KsponSpeech_eval_clean(AI_hub eval 데이터) | 24.4 |
| Spec_Augment + RNN-T + Beam search(W = 5) | log_feature_161 | KsponSpeech_eval_clean(AI_hub eval 데이터) | 25.4 |
| Spec_Augment + RNN-T | log_feature_161 | KsponSpeech_val(길이 조절 데이터) | 21.2 |
| Spec_Augment + RNN-T + Beam search(W = 5) | log_feature_161 | KsponSpeech_val(길이 조절 데이터) | 19.4 |
Intro
한국어를 위한 RNN-Transducer입니다. 실시간 인식에는 attention기반의 모델보다 RNN-Transducer가 사용된다고 합니다. 현재 git hub에는 한국어로 test한 결과가 없어 한국어 RNN-Transducer를 구현하고 성능을 검증하였습니다.
Version
- torch version = 1.2.0
- Cuda compilation tools, release 9.1, V9.1.85
- nn.DataParallel를 통해 multi GPU 학습
How to install RNN-T Loss
Data
Dataset information
AI hub에서 제공하는 '한국어 음성데이터'를 사용하였습니다. AI Hub 음성 데이터는 다음 링크에서 신청 후 다운로드 하실 수 있습니다.
AI Hub 한국어 음성 데이터 : http://www.aihub.or.kr/aidata/105
Data format
- 음성 데이터 : 16bit, mono 16k sampling WAV audio
- 정답 스크립트 : 제공된 스크립트를 자소로 변환된 정답
1. "b/ (70%)/(칠 십 퍼센트) 확률이라니 " => "칠 십 퍼센트 확률이라니" 2. "칠 십 퍼센트 확률이라니" => "ㅊㅣㄹ ㅅㅣㅂ ㅍㅓㅅㅔㄴㅌㅡ ㅎㅘㄱㄹㅠㄹㅇㅣㄹㅏㄴㅣ" 3. "ㅊㅣㄹ ㅅㅣㅂ ㅍㅓㅅㅔㄴㅌㅡ ㅎㅘㄱㄹㅠㄹㅇㅣㄹㅏㄴㅣ" => "16 41 7 1 11 41 9 1 19 25 11 26 4 18 39 ..." 최종: "b/ (70%)/(칠 십 퍼센트) 확률이라니 " => "16 41 7 1 11 41 9 1 19 25 11 26 4 18 39 ..."
-
위의 txt 전처리는 https://github.com/sooftware/KoSpeech/wiki/Preparation-before-Training 다음을 참고하였습니다.
-
./model_rnnt/hangul.py 에 있는 pureosseugi 함수를 통해 자소 분리를 하였습니다.
-
./label,csv/hangul.labels 를 기반으로 대응하는 숫자로 변환하였습니다.
Dataset folder structure
- DATASET-ROOT-FOLDER
|--DATA
|--train
|--wav
+--a.wav, b.wav, c.wav ...
|--txt
+--a.txt, b.txt, c.txt ...
|--val
|--wav
+--a_val.wav, b_val.wav, c_val.wav ...
|--txt
+--a_val.txt, b_val.txt, c_val.txt ...
- data_list.csv
<wav-path>,<script-path> KsponSpeech_000001.wav,KsponSpeech_000001.txt KsponSpeech_000002.wav,KsponSpeech_000002.txt KsponSpeech_000003.wav,KsponSpeech_000003.txt KsponSpeech_000004.wav,KsponSpeech_000004.txt KsponSpeech_000005.wav,KsponSpeech_000005.txt ...
데이터를 커스텀하여 사용하고 싶으신분들은 다음과 같은 형식으로 .csv 파일을 제작하면 됩니다.
- hangul.labels
#id\char 0 _ 1 2 ㄱ ... 52 ㅄ 53 <s> 54 </s>
Model
Feature
-
spectrogram
parameter value N_FFT sample_rate * window_size window_size 20ms window_stride 10ms window function hamming window -
code
def parse_audio(self, audio_path): y,sr = librosa.load(audio_path, 16000) D = librosa.stft(y, n_fft=n_fft, hop_length=hop_length, win_length=win_length, window=self.window) spect, phase = librosa.magphase(D) spect = np.log1p(spect) spect = torch.FloatTensor(spect)
Architecture
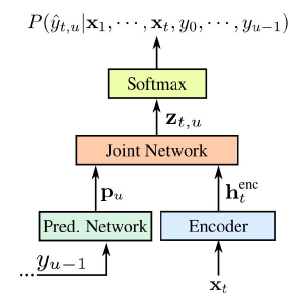
Print Model
DataParallel(
(module): Transducer(
(encoder): BaseEncoder(
(lstm): LSTM(161, 1024, num_layers=6, batch_first=True, dropout=0.3)
(output_proj): Linear(in_features=1024, out_features=320, bias=True)
)
(decoder): BaseDecoder(
(embedding): Embedding(54, 128, padding_idx=0)
(lstm): LSTM(128, 1024, num_layers=2, batch_first=True, dropout=0.3)
(output_proj): Linear(in_features=1024, out_features=320, bias=True)
)
(joint): JointNet(
(forward_layer): Linear(in_features=640, out_features=320, bias=True)
(tanh): Tanh()
(project_layer): Linear(in_features=320, out_features=54, bias=True)
)
)
)References
Git hub References
- https://github.com/1ytic/warp-rnnt
- https://github.com/ZhengkunTian/rnn-transducer
- https://github.com/HawkAaron/E2E-ASR
- https://github.com/sooftware/KoSpeech/wiki/Preparation-before-Training
Paper References
- Sequence Transduction with Recurrent Neural Networks (https://arxiv.org/abs/1211.3711)
- Two-Pass End-to-End Speech Recognition (https://arxiv.org/abs/1908.10992)
Blog References
- https://gigglehd.com/zbxe/14052329
- https://dos-tacos.github.io/paper%20review/sequence-transduction-with-rnn/
Youtube References
computer power
- NVIDIA TITAN Xp * 4
Q & A
Q1 : (Data set part) KsponSpeech_val(길이 조절 데이터)은 왜 따로 나눴는지?
A1 : RNN-T는 RNN-T Loss를 사용합니다. 그러므로 wav len과 script len에 따라서 시간과 메모리를 잡아 먹습니다. KsponSpeech_eval_clean의 데이터를 wav len과 script len은 특정 길이로 제한하게 되면 데이터의 양이 너무 적어 학습 데이터에서 5시간을 분리했습니다.
- train data 총 길이 - 약 254시간
- val data 총 길이 - 약 5시간
- KsponSpeech_eval_clean(AI_hub eval 데이터) - 약 2.6시간
Q2 : (labels part) 왜 음절 단위 말고 자소 단위로 나눴는지?
A2 : RNN-T Loss wav len과 script len뿐만 아니라 vocab size도 메모리를 잡아 먹습니다.즉 vocab size가 증가 할 수록 메모리를 많이 잡아 먹기 때문에 학습에서 gpu 메모리 이득을 보기 위해 다음과 같이 사용하였습니다. (gpu 메모리가 여유가 있으시면 음절 단위로 해보셔도 좋을것 같습니다.)
Q3 : (labels part) 53(sos token) 와 54(eos token) 는 왜 들어간건지?
A3 : 나중에 two pass를 사용하기 위해서 집어 넣었습니다. RNN-T만 사용하신다면 삭제해도 무방합니다.
Contacts
학부생의 귀여운 시도로 봐주시고 해당 작업에 대한 피드백, 문의사항 모두 환영합니다.
fd873630@naver.com로 메일주시면 최대한 빨리 답장드리겠습니다.
인하대학교 전자공학과 4학년 정지호