-
what is reinforcement learning
- interacting with environment
- it is active and sequential learning
- it is goal-directed
- learn without examples of optimal behavior
- optimize a reward signal: reward hypothesis -> Any goal can be formalized as the outcome of maximizing a cumulative reward
- find solutions and adapt online
- leanring to make decisions from interaction
-
important elements:
- reward -> A reward Rt is a scalar feedback signal, indicates how well agent is doing at step t — defines the goal
- return -> G_t = R_t + R_t+1 + ...
- value -> expected cumulative reward for a state: V = E(R_t + R_t+1 + ... | S = s)
- policy -> state to action mapping. A policy defines the agent’s behaviour
- action value -> expected cumulative reward for a state and action pair: Q = E(R_t + R_t+1 + ... | S=s, A = a)
- agent state -> usually a function mapping (compression) of full sequence of observations of environment, actions, and rewards (history) S_t+1 = f(S_t, A_t, R_t+1, O_t+1). The agent state is often much smaller than the environment state
- environment state -> internal states, it is usually invisible to the agent
- fully observable environment -> observation = environment state
-
markov decision processes:
- current state contains all we need to know from the history
- p(r,s | St,At) = p(r,s | Ht,At)
-
bellman equation: v_pi(s)=E[Rt+1 + v_pi(St+1)|St =s,At ∼pi(s)]
-
Model: A model predicts what the environment will do next. whats the next state P(s,a,s′)≈p(St+1 =s′ |St =s,At =a), whats the next reward R(s,a)≈E[Rt+1 |St =s,At =a]
-
differnt agent categories:
- value based - policy based - actor critic
- model free - model based
-
prediction vs. control:
- prediction: evaluate the future
- control: optimize the future
-
learning vs. planning:
- Learning:The environment is initially unknown and the agent interacts with the environment
- A model of the environment is given (or learnt) and the agent plans in this model (without external interaction)
-
bandits
- only have a single environment state. The action dont have long-term effects and cannot change the state. reward is only related to action choice
- differnt from full RL where reward is related to both state and action and action may change the state
- different from contextual bandit where reward is related to both states and actions and action donot have any impact of state
-
exploration and exploitation:
- exploitation: maximize the performance based on current knowledge
- exploration: increase knowledge
- We need to gather information to make the best overall decisions and the best long-term strategy may involve short-term sacrifices
-
greedy algorithm:
- Select action with highest value: At = argmax Qt(a)
-
optimistic initial value
- start with an value function that are much larger than the true value
-
epsilon-greedy algorithm:
- 1- epsilon probability to select action with highest value: At = argmax Qt(a)
- epsilon probability to randomly select an action
-
upper confidence bounds:
- hoeffdings inequality: p(x - E(x) >= t) <= exp(-2nt2) set p = n-4 -> select action = argmax(mean + sqrt(2logN/n_i))
-
thompson sampling:
- (likelihood bernoulli)reward is either 1 or 0. then the mean of rewards of each action is beta distribution: update beta(a, b) -> a = a + reward, b = b + 1 - reward
- assume likelihhood is gaussian distributed. 1 known precision, unknown mean -> how to calculate posterior 2. unknown precision, known mean 3. unknown precision, unknown mean
- Bellman expectation equation

-
Bellman optimiality equation
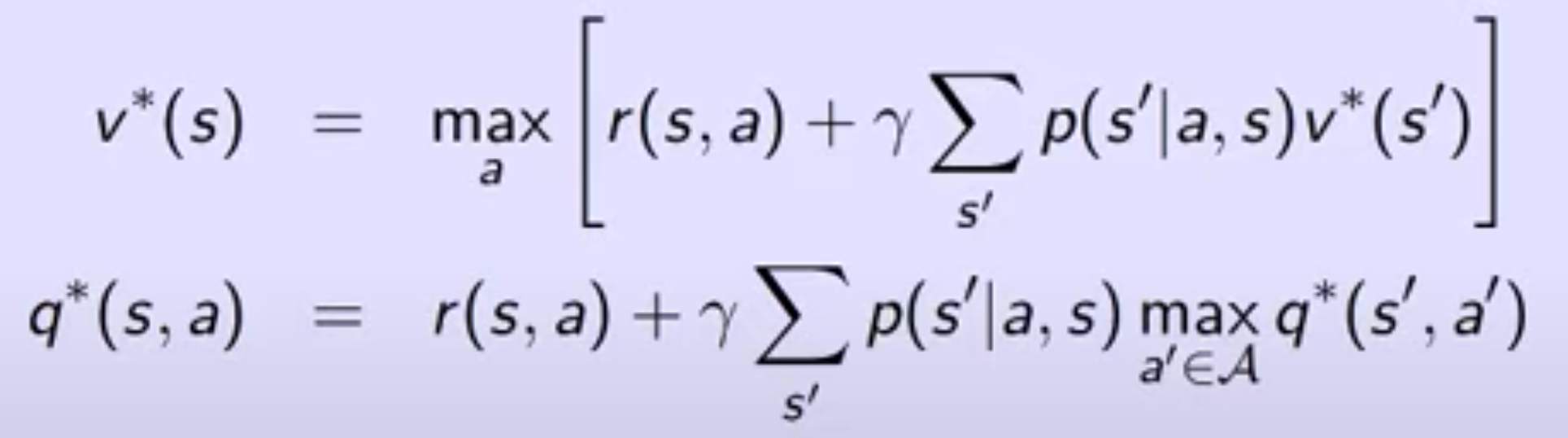
-
algorithms for evaluation and control
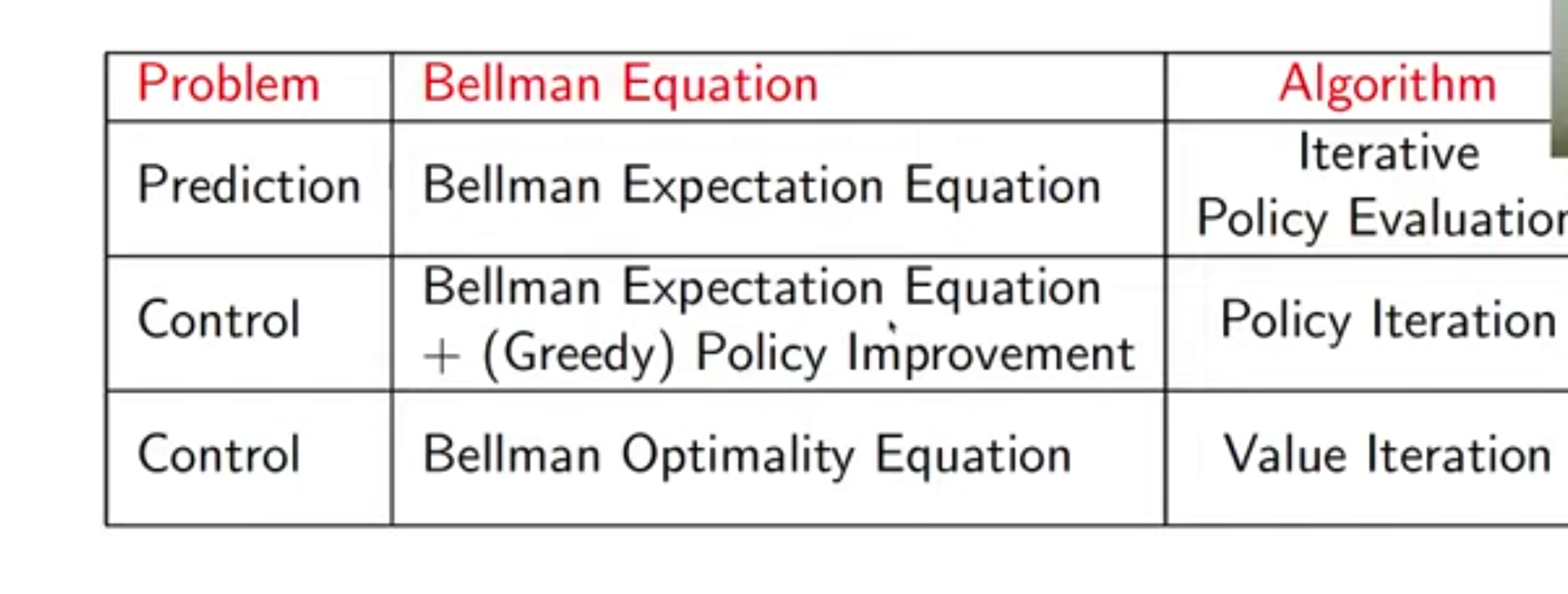


- algorithms
- selection: select the action with highest score: score = Q + beta * pi(s) / (1 + n)
- expansion: according to policy pi, randomly select one action
- evaluation: fast roll-out, select action according to policy pi til the end of game. calculate the value: (v + r) / 2
- backup: update Q using (v + r) / 2
-
DQN
- experience replay
- prioritized experience replay
- dueling net: learn a value function plus a advantage. Q = value + advantage - max(advantage); loss = Q_target - Q
- noisy net:
- off-policy vs. on-policy
- double DQN
-
Sarsa
- difference between Q learning and SARSA: SARSA is to train action value function for a certain policy pi; Q learning is to train optimal Q value function
- action function estimation is used as critic in actor critic algorithm
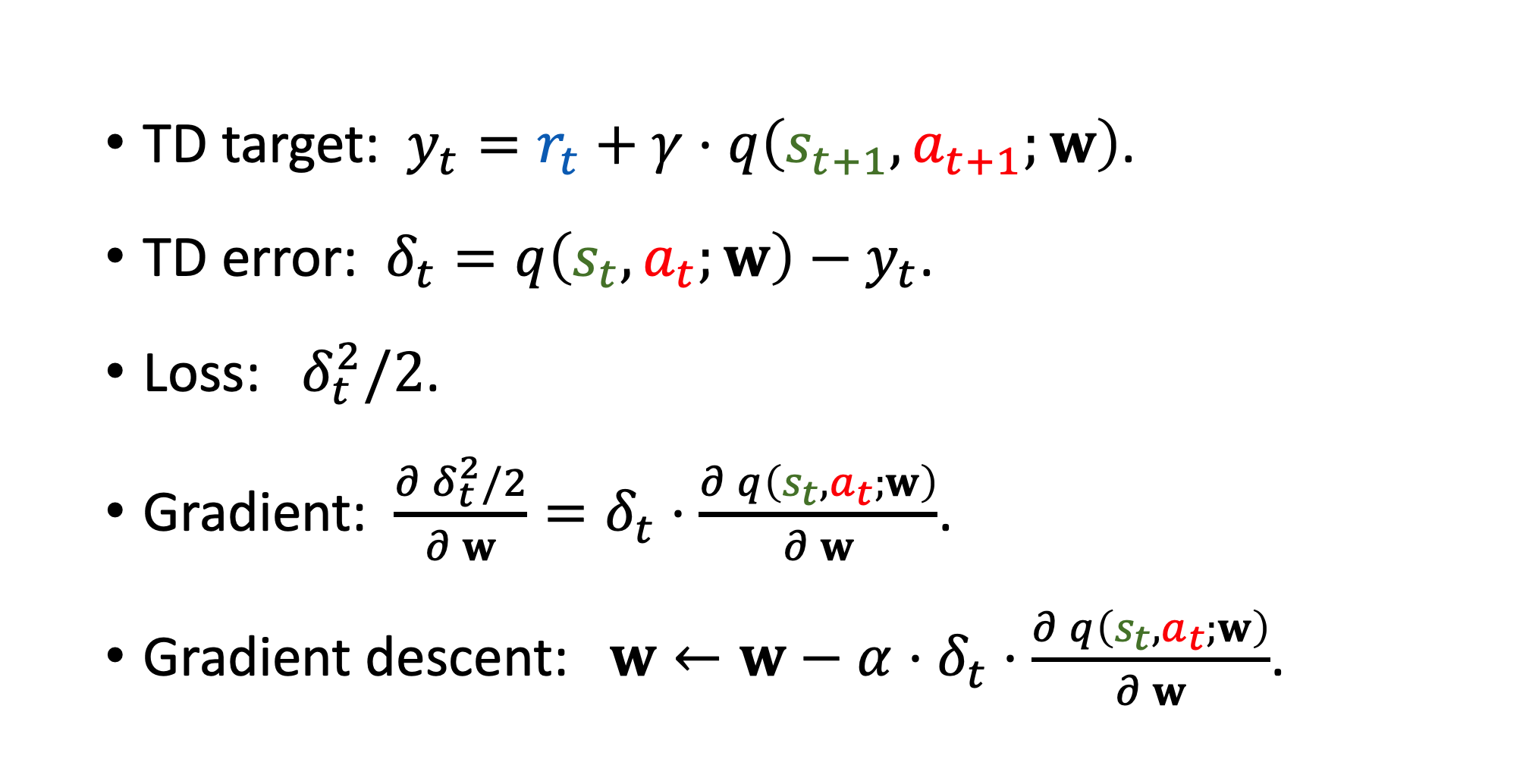

-
Reinforce
-
Reinforce with baseline
-
Actor-Critic
-
Advantage Actor-Critic (A2c)
-
Trust region policy optimization (TRPO)
-
Proximal policy optimization (PPO)
-
entropy regularization
-
Continuious action:
- deterministic policy gradient (DPG)
- twin delayed deep deterministic policy gradient (TD3)
- Gaussion distribution policy
-
partially observable envirionment
-
imitation learning
-
types:
- fully cooperative
- fully competetive
- mixed
- self-insterested
-
approaches:
- Decentralized
- Centralized
- Centralized training with decentralized execution