pip install -r requirements.txt(make sure to be in a Python 3.10 or newer environment)- create a
.envfile withOPENAI_API_KEY=...andANTHROPIC_API_KEY=...- If you want to evaluate more models and have more flexibility over the API, I would suggest setting up a AlpacaEval client config. With this you should be able to evaluate most of the important models on AlpacaEval using only APIs (google, anthropic, openai, and togetherai for major open source models).
The pipeline for the project is as follows:
- Writing the instructions this is to collect the instructions that we'll input into the model as well as potential expert-written addiotional information that could improve the quality of the next rubric generation (e.g. a checklist per instruction).
- Real-world in the real world, the hope is that experts would write a "small" number of instructions (e.g. 200) and associated bullet points that they think are important to consider when evaluating the output on each instruction. For experts this will be the most costly part of the pipeline, but it's only done once so it should be worth it. Ideal instructions for RubricEval are from some expert domain such that (1) models can't evaluate on their own (but can apply the rubric), (2) experts are expensive and can thus not do all the evaluations on their own, and (2) the final use case is high stakes and thus require highly trusted benchmark and interpretability in the results. E.g. of domains that are well suited: law, medical, finance, etc.
- Benchmark ideally we would have realistic instructions for the benchmark that we release. But given that this is somewhat orthogonal to the main contribution of the project and costly to get, I think that V1 should use instructions that already exist. The current data that we have is from WildBench, which has the benefit of having a per-instance "checklist" column. We filtered those down (using
filter_wildbench.pybut that's not important anymore) to only include a subset of 391 challenging instructions. The desired filtered data is indata/benchmark/wildbench_checklist/filtered_prompts.json. - Codebase the original idea was that the codebase would also allow people to generate their own instructions and do the evaluation if they only had the instructions and no checklist. I don't think this is priority, but instructions can be LLM generated using the
Instructionatorand theRubricBrainstormerallows for instructions without checklist (more generally it takes in a fieldadditional_information), which can be empty.
- Brainstorming the rubrics given the instruction and additional information, an LLM or an expert could write some high-level rubric as seen below.
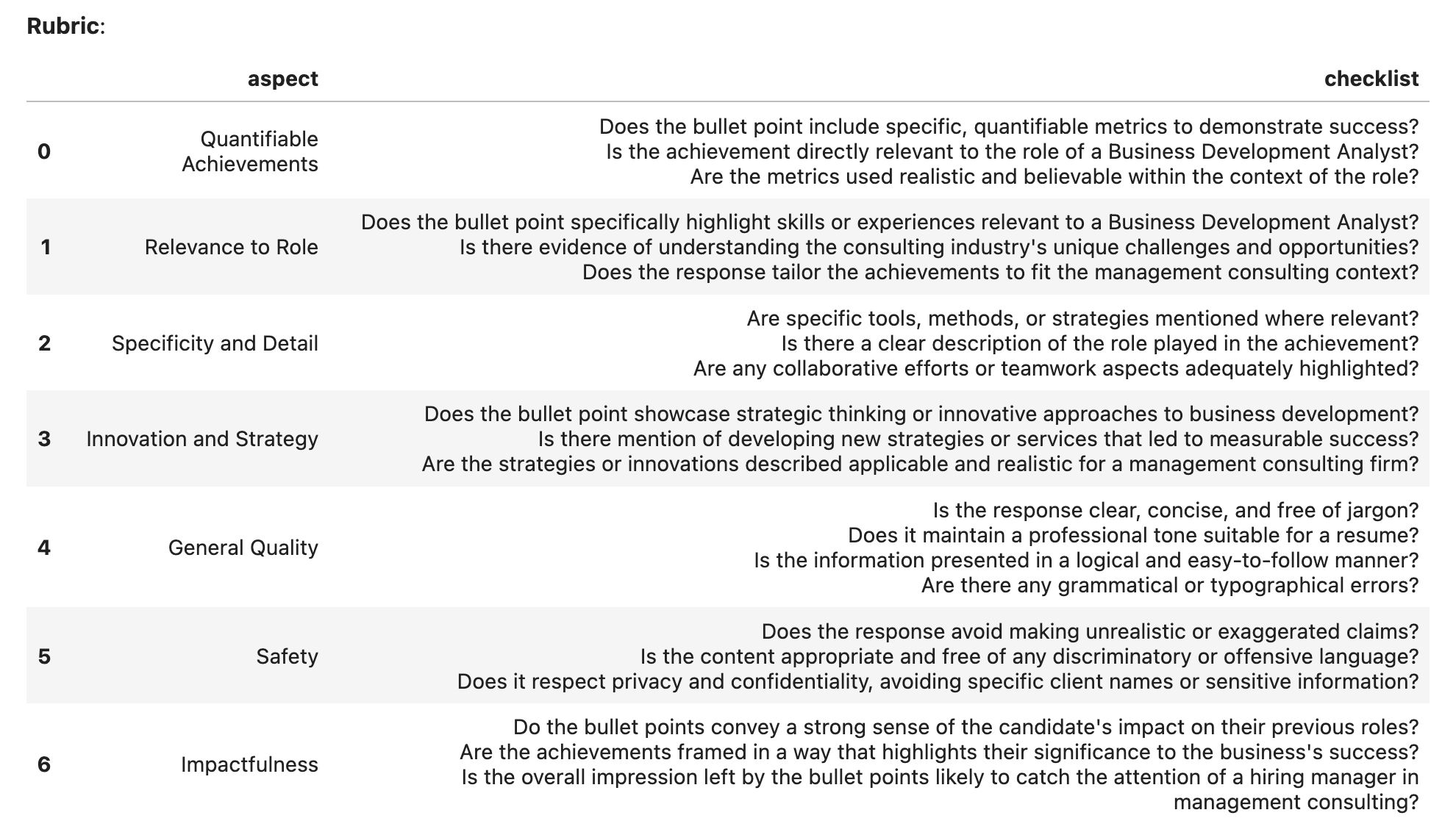
- Real-world in the real-world the additional cost of having experts write the high-level rubrics is minimal compared to adding a checklist (the only difference is that it has to be structured by different axes. My guess is that having expert-written high-level rubrics would give much more realistic final rubrics and thus be worth the cost.
- Benchmark for the benchmark, we provide a
RubricBrainstormerthat aims to convert the usntructured additional_information (e.g. checklist) to the high-level rubric. This is to allow converting any dataset to our format and should be used for example with WildBench.
- Generating the rubrics given the high-level rubric, we can generate the final rubric. This is done by the
RubricGeneratorwhich is a simple LLM that takes in the high-level rubric and the instruction and generates the final rubric. This step should be simple for LLMs but tedious for humans. I would thus suggest always having an LLM do this step, with optional human review & modification.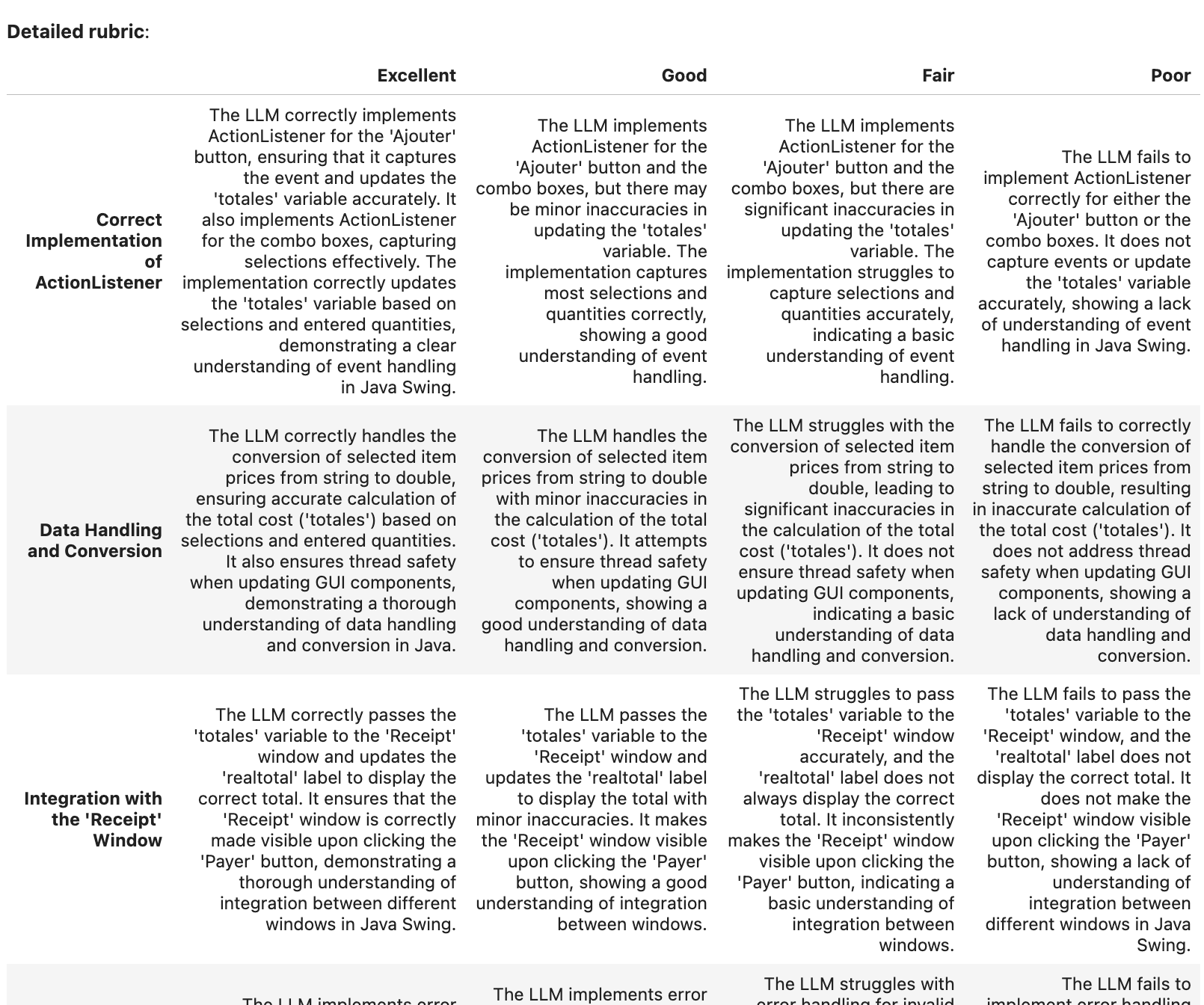
- Decoding/Inference of the models there's nothing new here, we just need to predict what different models would say. This is done by the
Completorandalpaca_evalessentially already provides the code to evaluate hundreds of models. - Evaluation the
Evaluatorthen takes in the predictions and the rubric and outputs some feedback, the selected category in the rubric, and the final score. This should be done only by LLM for scalability. This will likely be the hardest for the model in some domains (e.g. if it's bad at math it will be hard for it to evaluate math instructions). But for many valuable domains (healthcare, legal, ...) I'm confident that current models can do a good job. - Summarizer One of the main benefits of RubricEval is that it can provide more finegrained interpretability into what the model does well/wrong and why it was given a certain score. THe problem is that no one will read N>=200 feedback and selected rubrics. We would thus need a summarizer that takes in the feedback and selected rubric and generates a summary / model card of what the model does well and badly. This is a bit different from the other steps in that the function is many-to-one (many feedbacks to one summary), which is why we don't have a minimal class that inherits from AlpacaEval to do that. A minimal version of the summarizer is
summarize_resultsbut this should really be rewritten. Note that providing all the outputs & instructions & feedback & rubrics will probably exceed the context length of the llm judge. So I would suggest having a two (or more) layer summarizier pipeline, which recursively applies summarizers to the output of the previous summarizer. Note that the summarizier will need to be prompt tuned to ensure that it provides detailed and actionable summaries of the model's performance that are self contained (i.e. the human shouldn't need to know about the instructions to understand the summary).


helm_instructcontains the main code. The naming is due to historical reasons.annotators.pycontains the code for all annotators that inherit from AlpacaEval (all the steps besides summarizer). AlpacaEval annotators are classes that take a dataframe as input (with columns of potential fields that should be inputed in the prompt to the llm ) and outputs a dataframe with the same columns + the outputs of the llm. The annotators are the main classes that should be used in the pipeline. In particularprimary_keysspecifies which columns can be formatted in the prompt, andannotation_keyspecifies the name of the column that should be added to the dataframe with the outputs of the llm.DEFAULT_BASE_DIRspecifies which directory will contain all the configs for potential annotators (e.g. different prompts, models, or decoding strategies).*_configsspecifies all the hyperparameters and prompt for different potential anntoators (i.e. isntances of classes inannotators.py). As an example,rubric_brainstormer_configs/gpt4_CoT_v0/configs.yamlspecifies all the hyperparameters for the rubric_brainstomer we use. Note: the current uses mostly"gpt-4-turbo-preview", but I would suggest using the newergpt-4o-2024-05-13which is cheaper and better. I would highly suggest understanding the different hyperparameters, read the docstrings and ask Yann if you don't understand something. The most important are:
gpt4_CoT_v0: # should be the name of the directory
prompt_template: "gpt4_CoT_v0/prompt.txt" # prompt template. Curly braces {column} will be replaced by values of the corresponding column in the dataframe
fn_completions: "openai_completions" # functions to use to get completions. see https://github.com/tatsu-lab/alpaca_eval/blob/main/src/alpaca_eval/decoders/__init__.py
completions_kwargs: # kwargs to the completions functions. E.g. for openai it's all the openai decoding kwargs
model_name: "gpt-4-turbo-preview"
max_tokens: 4096
# ...
fn_completion_parser: "json_parser" # how to parse the completions. typically json parser.notebooksinitial_wildbench.ipynbsome initial experiments with WildBench data. This should show you all the steps to run the pipeline. It may not be fully up to date, and can have some minor issues.old_alpacaevalolder notebook that used AlpacaEval instructionsold_autoolder notebook that used auto-generated instructions
datasome potentially preprocessed datawildbench_checklist/filtered_prompts.jsondata filtered from WildBenchwildbench_no_checklist/*.jsonfiltered data, and generated rubrics for the case where we don't use the checklist. This could be used for understanding how useful a checklist is (and how much the results change when in both cases). I don't think it's high priority though.