A lot of useful DS links
- 1. Team leading
- 2. Books
- 3. Business
- 4. Courses
- 5. Lists of Tools
- 6. DS Libraries and Instruments
- 7. Notebooks
- 8. General DS Links
- 9. Testing in DS
- 10. Metrics in DS projects
- 11. Causal Inference and Explainable AI
- 12. Reproducibility and Automatization
- 13. AI Products Architecture and System Design
-
All IAEA publications (All techical reviews, etc) | Operation and maintenance of NNPs | Nuclear knowledge management
-
Kalman-and-Bayesian-Filters-in-Python by by Roger R. Labbe - Kalman Filter book using Jupyter Notebook. Focuses on building intuition and experience, not formal proofs. Includes Kalman filters,extended Kalman filters, unscented Kalman filters, particle filters, and more. All exercises include solutions.
-
[RU]Агрегатор всех источников поддержки вашего бизнеса от Rusbase -
[RU]54 лучших (DS) инструмента создания аналитических отчетов для бизнеса -
[RU]Алексей Колоколов (Институт бизнес-аналитики) о важности визуализации и как правильно визуализировать информацию и готовить отчеты/дашборды: Дашборды: интерактивная визуализация данных | Монетизация больших данных -
[RU]Стратегия данных и аналитики. Как компании спланировать и внедрить DS/ML
-
✅
[RU]Полный курс LeanDS -
✅
[RU]Обзорный курс LeanDS -
✅Business Metrics for Data-Driven Companies (coursera course)
-
The hidden value – Lean in manufacturing and services by École des Ponts ParisTech and BCG
-
[RU]BIG DATA для менеджеров by productlive - КУРС ДЛЯ РУКОВОДИТЕЛЕЙ ДЕПАРТАМЕНТОВ, НАПРАВЛЕНИЙ И ВЛАДЕЛЬЦЕВ КОМПАНИЙ -
[RU]Управление AI/ML продуктами by productlive - Курс для product-менеджеров, предпринимателей и руководителей, которые хотят получать прибыль от AI/ML-продуктов.
-
Online courses and other DL staff (MIT's Lex Fridman recommendation, fast.ai)
-
[RU]D. Vetrov course on Нейробайесовские методы - байесовские сети (youtube) -
9h course of Bayesian Methods for Machine Learning by HSE (youtube)
-
✅
[RU]Введение в машинное обучение By HSE University and Yandex School of Data Analysis -
Statistical forecasting: notes on regression and time series analysis (duke)
-
Курс «Глубинное обучение», Школа анализа данных (В. Лемпицкий)
-
Lectures on VAE: Deep Learning Lecture 14: Karol Gregor on Variational Autoencoders and Image Generation | Variational Autoencoder and Extensions
-
MLSS/SMILES at Skoltech: youtube | github 2019 | github 2020
-
Reinforcement Learning Course at ASU, Spring, 2021 (youtube)
-
Machine Learning Crash Course by Google - Google's fast-paced, practical introduction to machine learning

-
Awesome Ensemble Learning - to promote the learning of ensembling, we create this repository with: Books & Academic Papers, Online Courses and Videos, Open-source and Commercial Libraries/Toolboxes and Datasets, Key Conferences & Journals
-
awesome-TS-anomaly-detection - List of tools & datasets for anomaly detection on time-series data
-
(A LOT OF LINKS but not very useful) Machine Learning and Data Science Applications in Industry
-
Awesome production machine learning - This repository contains a curated list of awesome open source libraries that will help you deploy, monitor, version, scale, and secure your production machine learning.
-
Awesome Machine Learning - A curated list of awesome machine learning frameworks, libraries and software (by language).
- Sktime: a Unified Python Library for Time Series Machine Learning: towardsdatascience | github | youtube 2020 | youtube 2022 Per the Github page, sktime currently provides:
- State-of-the-art algorithms for time series classification, regression, and forecasting (ported from the Java-based tsml toolkit),
- Transformers for time series: single-series transformations (e.g. detrending or deseasonalization), series-as-features transformations (e.g. feature extractors), and tools to compose different transformers,
- Pipelining for transformers and models,
- Model tuning,
- Ensembling of models — e.g. a fully customizable random forest for time-series classification and regression; ensembling for multivariate problems.
-
tslearn - The machine learning toolkit for time series analysis in Python.
-
TSFRESH: Time Series Feature extraction based on scalable hypothesis tests + arxiv paper - The package contains many feature extraction methods and a robust feature selection algorithm.
-
bayesian_changepoint_detection (online) - Methods to get the probability of a changepoint in a time series. Both online and offline methods are available.
-
Python Outlier Detection (PyOD) - PyOD is a comprehensive and scalable Python toolkit for detecting outlying objects in multivariate data. PyOD includes more than 30 detection algorithms
-
Playing with electricity - forecasting 5000 time series - Applying random forests and deep encoder-decoder RNNs to time series prediction + few anomaly detection links
-
AutoML for time series (FEDOT) - Approaches for time series forecasting using AutoML and example of the forecast obtained in the automated way
-
[RU]Model selection (hyperopt), feature engineering, ensembling -
[RU]Categorical Variable Encoding и построение моделей второго уровня -
Statistical Learning Tutorial for Beginners (incl. CDF) (kaggle)
-
Data Visualization: a lot of seaborn plot types in work (kaggle)
-
Fraud detection (Summarizing Konstantin Yakovlev’s view of kaggle competition)
-
Anomaly Detection with Time Series Forecasting (SARIMA, LSTM, Holtwinters)
-
Time Series Classification and Clustering + Similarity Measures (github)
-
Intro to Autoencoders and anomaly detection with tensorflow | youtube video on the notebook
-
Isolation forest anomaly detection for telemetry time series data
-
Unsupervised anomaly detection library and its applications in networking domain
-
[RU]Машинное обучение для людей. Разбираемся простыми словами -
[RU]Как Data Science помогает превращать терабайты данных в выдающиеся финансовые результаты by McKinsey -
[RU]Deep Learning presentation by Sapunov (intento): Presentation | article -
[RU]ROADMAP НЕЙРОННЫЕ СЕТИ: где применяются нейронные сети сегодня и как аналитику данных начать их изучение. -
[RU]Recommendation systems: youtube workshop by OTUS school | Habr post -
Data preprocessing for machine learning: options and recommendations (by google)
-
[RU]CV scheme, McKinsey’s Datathon: The City Cupcv_scheme
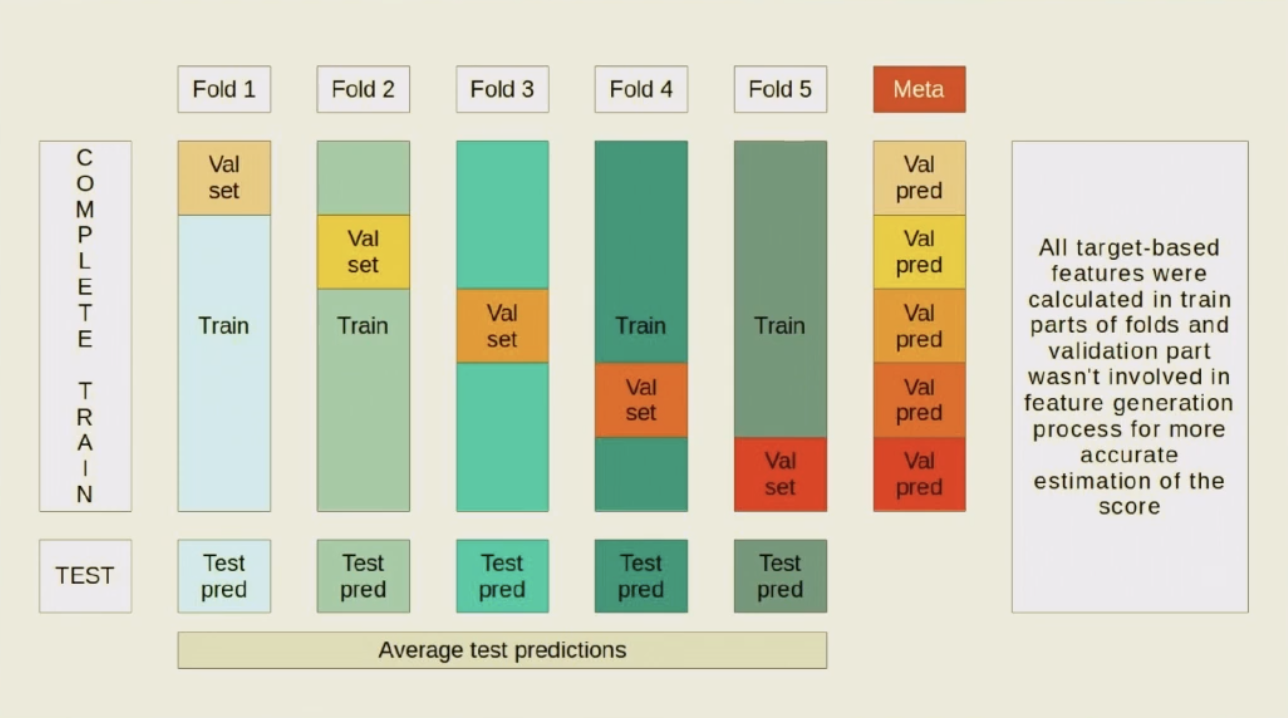
-
[RU]Стас Семенов tinkoff -
ML methods cheme
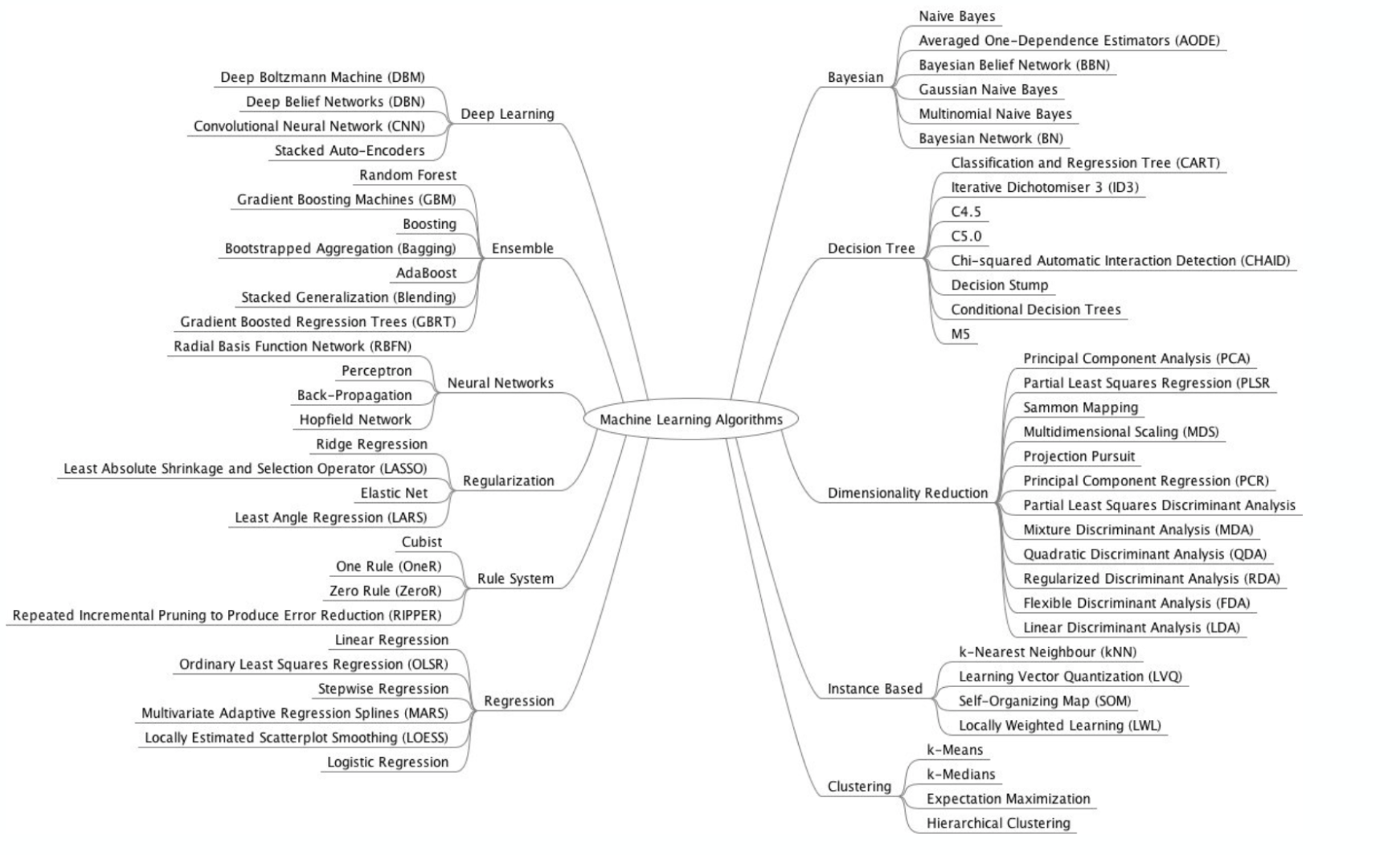


-
[RU]«Временные ряды: почему прогнозирование — это сложно». Александр Кондофуров, AltexSoft (youtube) -
[RU]Временные ряды в экономике - секция на DataFusion (youtube) -
Feature Engineering for Time Series Forecasting. Kishan Manan (youtube)
-
Convert a Time Series to a Supervised Learning Problem with code
-
How to Transform Time Series for Deep Learning | Forecasting with deep neural networks (medium)
-
Time Series Analysis (TSA) in Python - Linear Models to GARCH with code
-
Time Series Analysis by Aileen Nielsen. PyCon 2017 (youtube)
-
Irregular time series and how to whip them by Aileen Nielsen (youtube)
-
[VAR vs LSTM] Time Series Forecasting using Statistical and Machine Learning Models
-
LSTM: about | about+code | youtube (Kaspersky presentational) | code (Forecasting with LSTMs in Keras) | code (LSTM Models) | LSTM AE
-
Condition Monitoring and Predictive Maintenance from MathLAB
-
(PCA) Machine Learning for Real-Time Anomaly Detection in Network Time-Series Data
-
[RU]Outlier detection and Isolation forest (youtube) | notebook on github
-
AutoML (NN): DARTS: Differentiable Architecture Search (Arxiv) | DARTS (github
-
AutoKeras arxiv
-
Time series met AutoML Codalab Automated Time Series Regression — Denis Vorotyntsev
-
[RU]Testing for Data Science Hands-on Guide (Julia Antokhina) | gitlab -
[RU]Тестирование и мониторинг качества моделей и метрик, Александр Сидоров -
[RU]Можно ли тестировать искусственный интеллект? Процессы, подходы, практика, Антон Хританков -
[RU]Виктория Дочкина | Тестирование систем машинного обучения -
Effective testing for machine learning systems (jeremyjordan.me) - In this blog post, we'll cover what testing looks like for traditional software development, why testing machine learning systems can be different, and discuss some strategies for writing effective tests for machine learning systems.
-
[RU]Метрики в DS проектах (youtube), Алексей Могильников, Lead DS (2020) -
[RU]Краткий ликбез по ML метрикам и их связи с бизнес-метриками
-
[RU][Youtube] Дмитрий Павлов. Сausal Inference в анализе временных рядов [arxiv] Causal Inference for Time series Analysis: Problems, Methods and Evaluation -
Improved Shapley method Asymmetric | Causal
-
Causal inference in statistics: An overview - This review presents empirical researchers with recent advances in causal inference, and stresses the paradigmatic shifts that must be undertaken in moving from traditional statistical analysis to causal analysis of multivariate data.
-
Flexibility, Interpretability, and Scalability in Time Series Modeling
-
Inferring causality in time series data - A concise review of the major approaches. (+ video on youtube)
-
Causal Inference in Data Science From Prediction to Causation by Amit Sharma | DataEngConf NYC '16 - A gentle introduction to causality
-
Introduction to Explainable AI (ML Tech Talks) - This talk introduces the field of Explainable AI, outlines a taxonomy of ML interpretability methods, walks through an implementation deepdive of Integrated Gradients, and concludes with discussion on picking attribution baselines and future research directions.
-
[RU]Julia Antokhina: Software Engineering Lifehacks for Data Science -
Scikit-learn Pipelines - Scikit-learn's Pipeline class is designed as a manageable way to apply a series of data transformations followed by the application of an estimator.
-
pdpipe - We show how to build intuitive and useful pipelines with Pandas DataFrame using a wonderful little library called pdpipe.
-
[RU]ODS.ai Machine Learning REPA: Reproducibility, Experiments and Pipelines Automation
The ML REPA track is traditionally dedicated to the tools and practices of experiment management in Machine Learning, Reproducibility and process automation.
We have a fairly wide range of topics that overlap with the topics of other tracks - ML Infra, SysML, Lean Data Science and others. All these topics are related, and the task of ML REPA is to show how to build a process for developing ML solutions, how to organize teamwork and what tools can help you.
Kedro is an open-source Python framework that applies software engineering best-practice to data and machine-learning pipelines. You can use it, for example, to optimise the process of taking a machine learning model into a production environment. You can use Kedro to organise a single user project running on a local environment, or collaborate within a team on an enterprise-level project.
Data Scientists and ML Engineers use BentoML to:
- Accelerate and standardize the process of taking ML models to production
- Build scalable and high performance prediction services
- Continuously deploy, monitor, and operate prediction services in production


- Pytorch Code for Reproducibility:
Details
def set_determenistic(seed=666, precision=10):
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
torch.cuda.manual_seed_all(seed)
torch.manual_seed(seed)
torch.set_printoptions(precision=precision)- Tensorflow Code for Reproducibility:
Details
def Random(seed_value):
# 1. Set `PYTHONHASHSEED` environment variable at a fixed value
import os
os.environ['PYTHONHASHSEED'] = str(seed_value)
# 2. Set `python` built-in pseudo-random generator at a fixed value
import random
random.seed(seed_value)
# 3. Set `numpy` pseudo-random generator at a fixed value
import numpy as np
np.random.seed(seed_value)
# 4. Set `tensorflow` pseudo-random generator at a fixed value
import tensorflow as tf
tf.random.set_seed(seed_value)-
[RU]Архитектура AI продуктов, Михаил Перлин - Архитектура ПО - дисциплина, которая за это отвечает. Что она включает в себя? Каких скиллов и качеств требует? Могут ли DS ею овладеть? Кого звать на помощь, если нужно прямо сейчас? Доклад меньше про технологии и больше про процессы, стратегии и людей. -
System Design Interview: A Step-By-Step Guide by ByteByteGo on youtube
-
System Design Interview с Валерием Бабушкиным by karpov.courses Выпуск 1, Выпуск 2, Выпуск 3, Выпуск 4
-
ML System Design Interview с Валерием Бабушкиным by karpov.courses Выпуск 1, Выпуск 2, Выпуск 3