TrafficAdvisor: a Real-Time Traffic Monitoring System
Insight Data Engineering Project
Project idea
This project is designed to present real-time traffic flow volume on the map and allow user to query current, historical average and predicted traffic volume and other road information from the nearest traffic sensor on any designated geolocation.
Project purpose
Increased amount of vehicles will potentially bring more problems such as traffic congestion, incidents and air pollution. The purpose of this project is to build a data pipeline that support a web application shows the real-time traffic volume on map, and other information upon request, including current and historical average traffic volume, the prediction of future traffic volume and static information of the sensor and road.
Use cases
Allows users to retrieve historical average traffic volume on the nearest traffic sensor based on the geolocation on a specific time or the changes within a specific time period.
The prediction of future traffic volume based on current traffic volume pattern and other factors can be used for adaptive toll fare/carpool system on congested roads to reduce potential traffic congestion, taxi fare prediction, navigation and providing suggestions for urban planners.
Generate alerts if the local traffic is significantly higher than normal.
Main challenges
Retrieving historical traffic volume, calculating statistic information and comparing it with real-time traffic volume.
Finding correlation between traffic flow volume and multiple factors using machine learning, and prediction future traffic volume based on various features and trained model.
Combining data with latitude and longitude, and allow geolocation query of users.
Data source
The data will be the traffic volume at hourly bases from traffic observation sensors of Department of Transportation, including two following tables:
Traffic volume table: station, traffic volume count at each hour of each day of each year, etc.
Station table: station location, latitude, longitude, type of road, lane counts, traffic direction, etc.
Data size is about ~200 Gb per year in past years but can randomly generate data following the same pattern with some fluctuation for earlier years without records or simulated observation stations or real-time traffic volume data.
Technologies used
File storage
S3: more elastic, less expensive, availability and durability
Batch processing
Spark: more mature and more third-party libraries, Spark MLlib is used for modeling
Real-time streaming
Kafka: ingest data and produce tral-time data
Spark Streaming: consume microbatches from Kafka and does real-time analysis
Database
PostgreSQL + PostGIS extention: store data with geolocation for analysis/presentation/user query
Front end
Flask + Leaflet: map presentation
Architecture
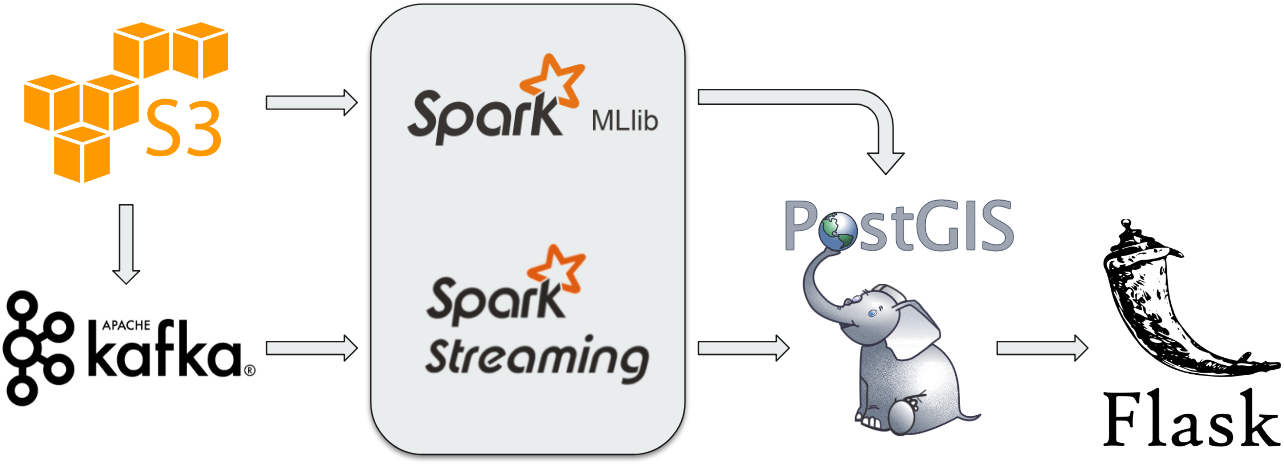 This is a lambda architecture that consists of both batch processing and streaming processing.
This is a lambda architecture that consists of both batch processing and streaming processing.
Spark: aggregation, filtration, profiling for the baseline of traffic volume patterns and training a linear regression model for each sensor based on features such as location, road type, traffic direction and traffic volume pattern within past 24 hours. The processed data is stored in PostgreSQL with geolocation, and the regression model is stored in S3.
Machine learning model: supervised learning with linear regression model consists of 177 features:
Categorical features: month, day of month, day of week, traffic direction, state, road type, lanes ⇒ convert to vector
Numeric features: traffic volume pattern in past 24 hours ⇒ log transformation
Label: traffic volume at a specific hour
LinearRegressionWithSGD.train(data, iterations=50, step=0.1, intercept=True)
Kafka: ingestion and production of simulated real-time data based on the historical data pattern.
Spark Streaming: consuption of simulated real-time data, comparison of current (real-time) data with historical average data and preliminarily labeling current traffic volume and prediction of traffic volume for next hour based on attributes of sensor and traffic volume pattern within past 24 hours with the trained model. The real-time data is stored in another table in PostgreSQL with geolocations.
Flask: Presentation of real-time traffic situation on the map where the high traffic volume is and response of user geolocation query from nearest sensor.
Cluster Configurations
Spark cluster: 4 m4.large instance 8G memory, 100G disk Ubuntu 16
Kafka cluster: 4 m4.large instance 8G memory, 100G disk Ubuntu 16
Spark Streaming cluster: 4 m4.large instance 8G memory, 100G disk Ubuntu 16
PostgreSQL cluster: 2 m4.large instance 8G memory, 100G disk Ubuntu 16
Demo
Live demo (future availability is not guaranteed).
No live demo since EC2 instances were terminated!
