| 模型 | 论文地址 | 代码复现地址 | 时间 |
|---|---|---|---|
| 词袋模型 | 论文地址 | 代码 | 2003 |
| Word2Vec | 论文地址 | 代码 | 2006 |
| GloVe | 论文地址 | 代码 | 2006 |
| NNLM | 论文地址 | 代码 | 2006 |
| TextCNN | 论文地址 | 代码 | 2006 |
| TextRCNN | 论文地址 | 代码 | 2006 |
| Seq2Seq | 论文地址 | 代码 | 2006 |
| Seq2Seq+Attention | 论文地址 | 代码 | 2006 |
| Transformer | 论文地址 | 代码 | 2006 |
| Bert | 论文地址 | 代码 | 2006 |
| FastText | 论文地址 | 代码 | 2006 |
| BiLSTM+Attention | 论文地址 | 代码 | 2006 |
| Attention+LSTM_FCN | 论文地址 | 代码 | 2006 |
| HAN | 论文地址 | 代码 | 2006 |
1.tensorflow1.8.0 ---谷歌开源深度学习框架
2.keras
3.pytorch ---Facebook开源的深度学习框架
1.tensorflow
2.numpy,sklearn,pandas,matplotlib
3.keras
*参考论文:A neural probabilistic language model
*实现代码

1.CBOW
2.skip-grams
*[参考论文:]
*实现代码
*分级softmax
*FatText内部结构
*FastText网络结构
*参考论文:Convolutional Neural Networks for Sentence Classification
*实现代码


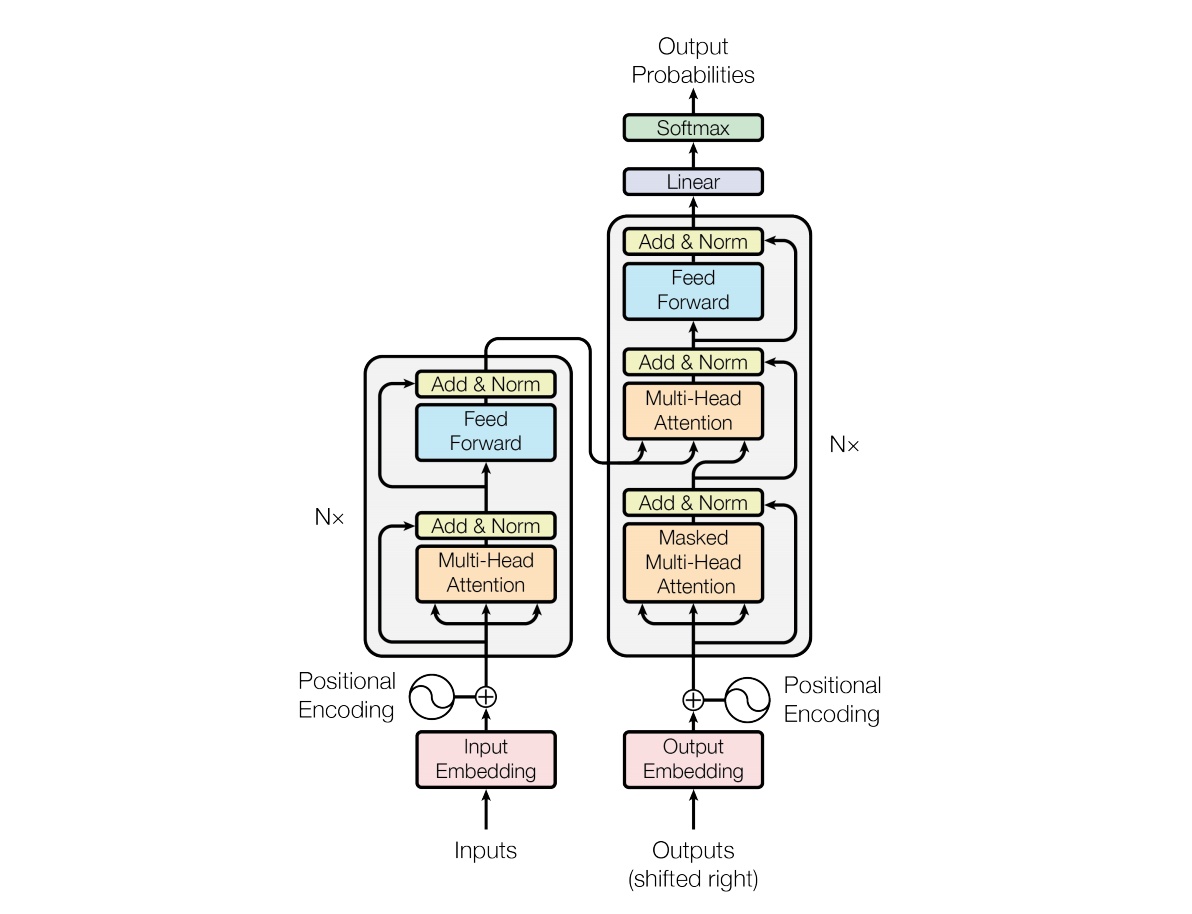
- The Transformer - model architecture
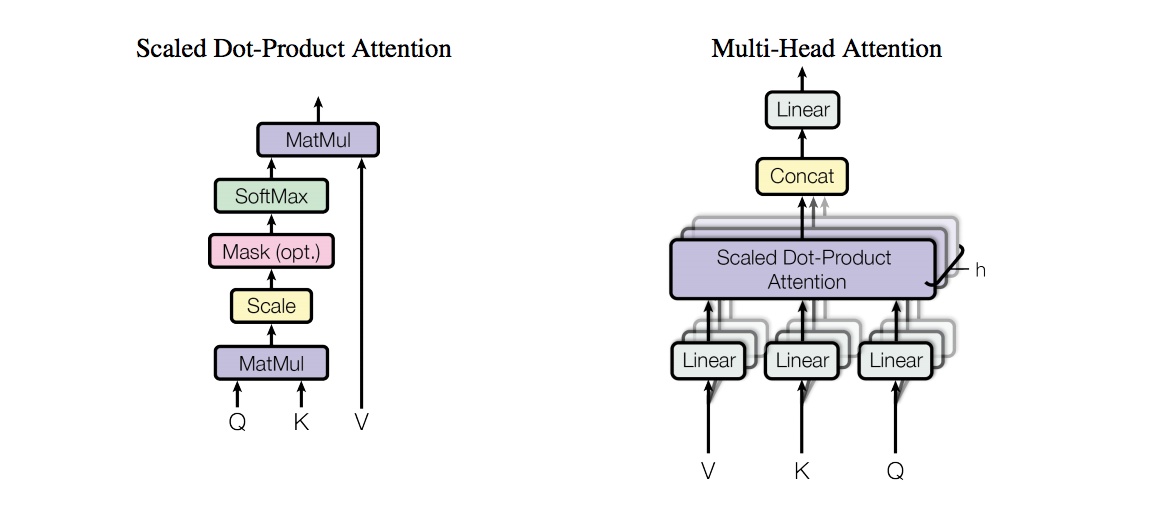
- (left) Scaled Dot-Product Attention. (right) Multi-Head Attention consists of several attention layers running in parallel


- 数据预处理
- 模型搭建
- 模型训练
- 模型保存