Design a Tensor Processing Unit(TPU) which has 4x4 Processing elements(PEs) that is capable to calculate (4*K)*(K*4) 8-bit integer matrix muplication. (Where is K is limited by the size of input global buffer)
Project Constraints
- Your designs should be written in verilog language.
- Your PEs shouldn't more than 4x4, where a 2D systolic array architecture is recommended.
- An 8-bit data length design.
- 3KiBytes in total of global buffer size.
Project Deadline
- Apr 30, 2021, 23:00

- You should know that in real world, TPU is a Deep Learning Processor(DLP) on the common bus, data is prepared continously by CPU or DMA from DRAM.
- In this project, you should focus only on the design and dataflow inisde the TPU, instead of full system simulation including CPU, DMA, and DRAM (Make it simple 😄 unless you need more challange).
AIC2021_TPU/
+-- tb/
| +-- matmul.py
| +-- top_tb.v
+-- src/
| +-- define.v
| +-- global_buffer.v
| +-- top.v
|
Makefile

- Your TPU design should be under the top module which provided by TA.
- TOP module includes three global buffers prepared for your TPU. Each of the global buffers has its own read write port,
256x32bit=1KiBytessize and result in total3KiBytesof global buffer. - Although the global buffer is provided by TA, you are free to design your own global buffer's behavior, except the name of the global buffers which already defined in testbench in order to load the data & check the correctness of the output.

- At the start of the simulation, tb will load the global buffer A & B, which assume that CPU or DMA has already prepared the data for TPU in global buffer. When signal
start==1, the size of the two matrices will be available for TPU (m,n,k).A(M*K)*B(K*N)
- You should implement your own data loader, process elements(PEs), and controller which schedules the data in global buffer A & B to be calculated in the systolic array.
- Testbench will compare your output global buffer with golden, when you finish the calculation(
done==1).
Prerequisite
- python3 with numpy library installed
- iverilog, ncverilog (or any other verilog compiler)
Makefile
make test1A(2*2)*B(2*2)
make test2A(4*4)*B(4*4)
make test3A(4*K)*B(K*4), whereK=9
make monster(extra)A(M*K)*B(K*N), whereK<10,M<10,N<10- Although our target is
(4*K)*(K*4)matrix multiplication, whenM&Nis small enough to fit in the input global buffers, give a solution for that size of input matrices. 😄
make clean- This will remove the
build/folder
- This will remove the
Global buffer mapping
build/
+-- matrix_a.bin
+-- matrix_b.bin
+-- golden.bin
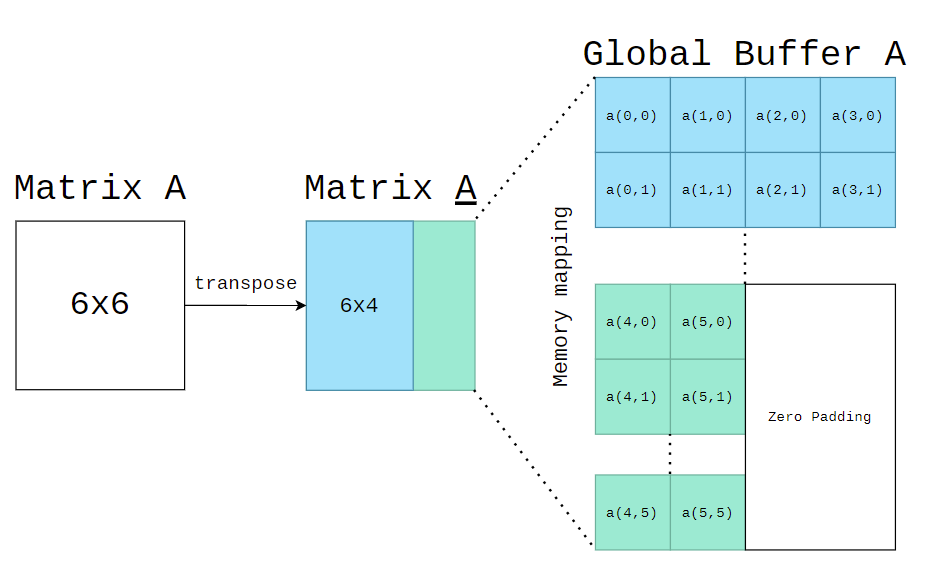
- Memory Mapping - Type A (with transpose)
- Memory Mapping - Type B (Without transpose)
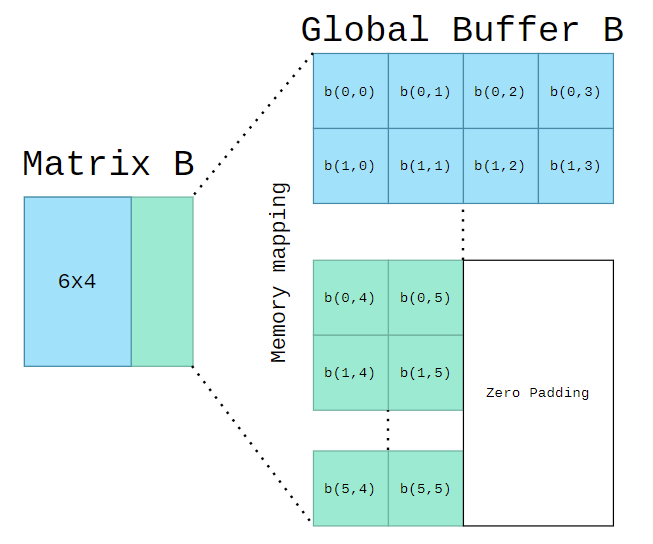
- As shown in the figure above, two figures give an example of
A(6*6)*B(6*6), how is the memory mapping of 8-bit matrix data into 32-bit global buffer. Your output global buffer should follow the memory mapping - type B.


- Testbench1~3 (70%)
- Designs of dataflow in TPU
- Execution time ranking in class
- Data reuse method
- Pass atleast test1~3
- Readme (20%)
- Members' Student ID
- TPU achitecture graph
- Explain your dataflow in TPU
- Pls descript as much as you can
- ...
- Extra (10%)
- Support
(M*K)*(K*N) - or other features
- please provided you own testbench for the extra features
- Good coding style
- Plagiarizing(copy-&-paste) others code is probihited
- Dont try to do that 😄, warning from TAs -100%
- Support