Wearing a mask and social distancing were the only measure to deal with COVID-19 before the presence of vaccines. Not to mention, the upcoming COVID variant leads to many breakthorugh cases around the world. Wearing a mask seems to be an effective measure against COVID infection. Despite the effectiveness of wearing a mask, enforcing such public health measure on customers is timing consuming for small businesses. Therefore, we promote a solution based on a ASIC CNN accelerator that is capable of monitoring the mask wearing restriction automatically.
More details can be found in our presentation slides. Also, the presentation is prettier on ppt than this markdown page.
Our mask detection CNN accelerator has the following HW architecture:

- 5-stage pipeline (textbook style)
- Implement 45 RV32I instructions
- Direct mapped L1-I$ and L1-D$
- Partially implement CSR instructions (M-mode only)
- Connects 3 master and 7 slaves
- AXI bridge verified by Cadence Assertion-Based Verification IP (ABVIP)
- 180 KiB weight buffer
- 2 KiB bias buffer
- 384 KiB output buffer
- 384 KiB input buffer
- 3x3/1x1 convolution, max-pooling units
- 64KB instruction memory (IM)
- 64KB data memory (DM)
- Off-chip memory simulated by testbench
- tPR (Precharge time) = 5
- tRCD (Row Address to Column Address Delay) = 5
- CL (CAS latency) = 5
- 16 KB off-chip memory
| Single clock domain, Speed = 100 MHz, UMC 180 um process | ||
|---|---|---|
| CPU | CPU+I$+D$ | ~1mm^2 |
| RAM | IM (32KB) | ~2.6 mm^2 |
| DM (32KB) | ~2.6 mm^2 | |
| EPU Buffers | Bias buffer | ~0.3 mm^2 |
| Weight Buffer | ~7.8 mm^2 | |
| Input Buffer | ~16 mm^2 | |
| Output Buffer | ~16 mm^2 | |
| EPU | ~0.6 mm^2 | |
| Total area (SYN) 47.6 mm^2 | ||
| Total area (APR) 67.9 mm^2 |
 ** The layout of this chip is partially done. IR drop has not been considered during APR.
** The layout of this chip is partially done. IR drop has not been considered during APR.
-
We use a NIN (Network In Network) model [1] and apply CLIP-Q [2] algorithm to quantize and compress the network.
-
NIN architecture in brief:
- NIN architecture from the original paper includes the stacking of three conv layers and one global average pooling layer.
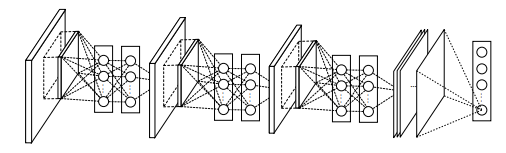
-
The CLIP-Q algorithm in brief:
- CLIP-Q combines weight pruning and quantization in a single learning framework, and performs pruning and quantization in parallel with fine-tuning. The joint runing-quantization adapts over time with the changing network.
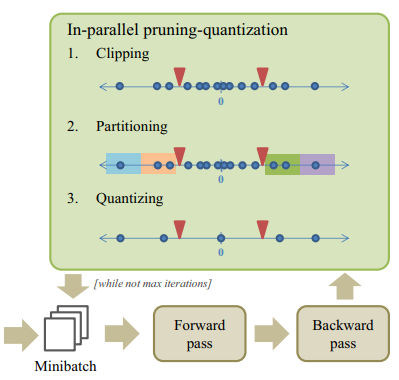
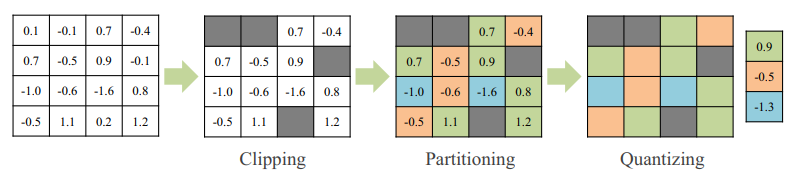
- The following example illustrates three steps of the pruning and quantization operations for a layer with 16 weights, p = 0.25 and b = 2. 75% of full precision weights that are close to zero will pruned as p = 0.25 (clipping), and weights are paartitioned into
$2^b=4$ partitions (partitioning). Weights fall into the same partition will be averaged out, and the averaged results will be the quantization levels. Therefore, only 4 weights (assume b = 2) need to be stored for each layer, and each weight in could be represented by merely 2 bits.



We modified the NIN model by replacing average pooling layer with max pooling and removing batch normalization layer to simplify the design of hardware. The modified version of NIN consists of the following layers:

We are able to obtain ~82% accuracy with this model on CIFAR-10 dataset while the original NIN model (full precision without quantization and pruning) is capable of reaching 90% accuracy. The possible cause might be the removal of batch normalization layers and the replacement of average pooling layers.
- We further shrink the modified model for mask detection based on the NIN structure, and eventually came up with the following model setup:

We then apply CLIP-Q quantization and pruning algorithm to further compress this model so that it fits in our NN accelerator. Eventually we are able to obtain a ~82% accuracy on our custom mask wearing dataset.
Special thanks to @Wder4 @NCKUMaxSnake @sam2468sam @alan-chen1412 @hsiehong @GuFangYi @WeiCheng14159 for their contribution.
- [1] Lin, M., Chen, Q., & Yan, S. (2013). Network in network. arXiv preprint arXiv:1312.4400.
- [2] Tung, F., & Mori, G. (2018). Clip-q: Deep network compression learning by in-parallel pruning-quantization. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7873-7882).