Note: This repository is now mantained by QAnswer, it can be found here.
The SummaServer provides a service for entity summarizatioimg over RDF graphs. For example for the entity "Die Zeit", a German weekly newspaper, the summary over Wikidata is:
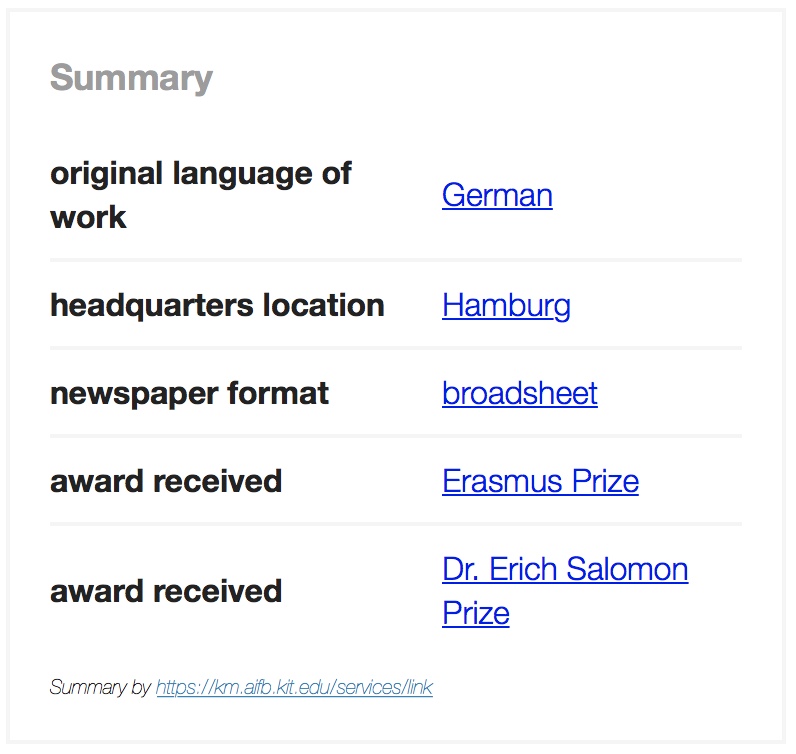
The following KB are currently supported: Wikidata, DBpedia, MusicBrainz, Dblp, Scigraph and Freebase.
Running the service is simple. Compile it using:
mvn clean package
Run it using:
java -jar target/summaServer-0.1.0.jar
This will start the server at port 3031 and expose the summarization service at:
localhost:3031/
To change the port or the name of the host change the following file.
The service is accessible both using GET and POST requests. For "Die Zeit" the requests are:
GET
curl "localhost:3031/wikidata/sum?entity=http://www.wikidata.org/entity/Q157142&maxHops=1&language=en"
POST
curl -d "[ a <http://purl.org/voc/summa/Summary> ; \
<http://purl.org/voc/summa/entity> \
<http://www.wikidata.org/entity/Q157142> ; \
<http://purl.org/voc/summa/topK> '5' ] ." -H "content-type: text/turtle" -H "accept: application/ld+json" localhost:3031/wikidata/sum
The response is encoded using the SUMMA (http://purl.org/voc/summa) and vRank (http://purl.org/voc/vrank) vocabularies.
A running demo can be found under:
https://wdaqua-summa-server.univ-st-etienne.fr
Moreover the summa server is used by the question answering system WDAqua-core0. A demo can be found at:
In the following we want to explain how to extend the service to new Knowledge Bases. As a running example we use the conrete case of the Wikidata KB.
-
You need to set up a triplestore containing the KB together with the PageRank scores expressed in the vRank vocabulary. The PageRank scores can be computed using the command line tool [PageRankRDF]{https://github.com/WDAqua/PageRankRDF}. We generally relay on SPARQL endpoints over HDT files like describe here.
-
Next you have to implement the following abstract class. This basically reduces to the following:
-
implements getName() indicating the name of the service, for example { return "wikidata"} will create a service under localhost:3031/wikidata/sum.
-
implement getRepository() indicating the address of the SPARQL endpoint with the RDF KB and the corresponding PageRank scores
-
implement getQuery0(), this method returns a query. It retrives for an ENTITY the corresponding label in the language LANG. For Wikidata the query is.
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> SELECT DISTINCT ?l WHERE { <ENTITY> rdfs:label ?l . FILTER regex(lang(?l), "LANG", "i") . } -
implement getQuery1(), this method returns a query. It returns the resources connected to the resource ENTITY, order them according to the PageRank score and take the first TOPK. Moreover it retrieves the labels of the founded resources in the language LANG. For Wikidata the query is.
PREFIX rdf: <http://www.w3.org/2000/01/rdf-schema#> PREFIX vrank: <http://purl.org/voc/vrank#> PREFIX wdd: <http://www.wikidata.org/prop/direct/> SELECT DISTINCT ?o ?l ?pageRank WHERE { <ENTITY> ?p ?o . FILTER (?p != rdf:type && ?p != wdd:P31 && ?p != wdd:P735 && wdd:P21> && ?p != wdd:P972 && wdd:P421> && ?p != wdd:P1343 ) ?o rdfs:label ?l . FILTER STRENDS(lang(?l), "LANG") . graph <http://wikidata.com/pageRank> { ?o vrank:pagerank ?pageRank . } } ORDER BY DESC (?pageRank) LIMIT TOPK -
implement getQuery2(), this method returns a query. It returns, given two resource ENTITY and OBJECT, the label of the property between them in the language LANG. For Wikidata we use the following query:
PREFIX rdf: <http://www.w3.org/2000/01/rdf-schema#> PREFIX vrank:<http://purl.org/voc/vrank#> SELECT ?p ?l WHERE { <ENTITY> ?p <OBJECT> . OPTIONAL { ?o <http://wikiba.se/ontology-beta#directClaim> ?p . ?o rdfs:label ?l . FILTER regex(lang(?l), "LANG", "i") }} ORDER BY asc(?p) LIMIT 1
-
Example of implementations can be found under:
https://github.com/WDAqua/SummaServer/tree/master/src/main/java/edu/kit/aifb/summarizer/implemented
Note: This repository is now mantained by QAnswer, it can be found here.
Copyright © 2014-2017 UJMS. This source code is licensed under the MIT license found in the LICENSE.txt file.
Made by Andreas Thalhammer & Dennis Diefenbach