Simple Youtube summarizer
What youtube talking about
A few years ago, ML algorithms looked strange and difficult for an average software engineer. ML is growing really fast. Nowadays it is easy to improve production solution by some Artificial Intelligence. You don’t need to have twenty people in your Data Scientist department if you want to extend you service with smart analytics or Artificial Intelligence. I will show you how to apply smart search in your service. Currently, our service is a place, where each user can share their articles, documents, videos, calendar events, tasks and etc. So we have a huge database with users’ content. Now it is a problem for a user to search a certain document or event. All items have tags and full text search. But what about video and audio files?
Usual creating usecase is:
- A user adds youtube link or uploads a file.
- A user names the new item: ‘New movie 01’.
And that is all. No one wants to spend time improving their own content. In real world we can help our customers. At first we can try to ask Youtube about details of a particular video for future search improvement. But unfortunately, as usual it is the same lazy user or it could be a video file from PC. So let’s make the AI search for tags and full text in users’ content! What do we need? As I told earlier nowadays it is much easier. Read more
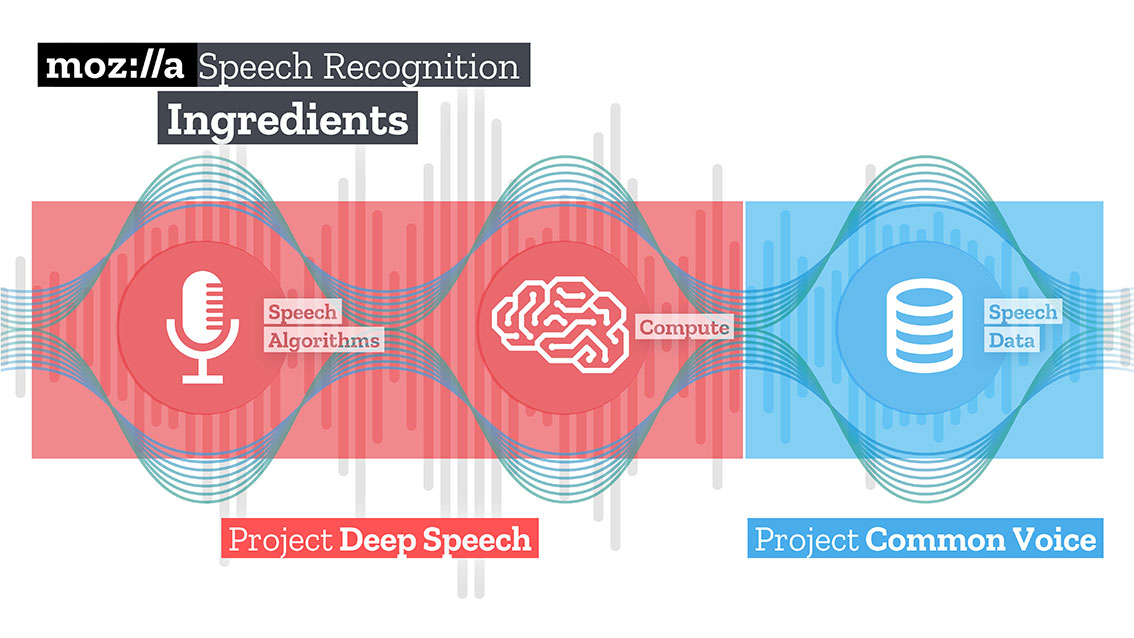
Environment
pip3 install wave numpy tensorflow youtube_dl ffmpeg-python deepspeech nltk networkx
brew install ffmpeg wget
Download Mozzila deepspeech model
mkdir /Users/Volodymyr/Projects/deepspeech/
cd /Users/Volodymyr/Projects/deepspeech/
wget https://github.com/mozilla/DeepSpeech/releases/download/v0.3.0/deepspeech-0.3.0-models.tar.gz
tar zxvf deepspeech-0.3.0-models.tar.gz
Launch
python3 summarizer.py --youtube-id %VideoID% --model %deepspeech%/models/output_graph.pb --alphabet %deepspeech%/models/alphabet.txt --lm %deepspeech%/models/lm.binary --trie %deepspeech%/models/trie --crop-time 900
Output:
Volodymyrs-MacBook-Pro:YoutubeSummarizer roaming$ cd /Users/Volodymyr/Projects/YoutubeSummarizer ; env "PYTHONIOENCODING=UTF-8" "PYTHONUNBUFFERED=1" /usr/local/bin/python3 /Users/Volodymyr/.vscode/extensions/ms-python.python-2018.11.0/pythonFiles/experimental/ptvsd_launcher.py --default --client --host localhost --port 53730 /Users/Volodymyr/Projects/YoutubeSummarizer/summarizer.py --youtube-id yA-FCxFQNHg --model /Users/Volodymyr/Projects/deepspeech/models/output_graph.pb --alphabet /Users/Volodymyr/Projects/deepspeech/models/alphabet.txt --lm /Users/Volodymyr/Projects/deepspeech/models/lm.binary --trie /Users/Volodymyr/Projects/deepspeech/models/trie --crop-time 900
Done downloading, now converting ...
ffmpeg version 4.1 Copyright (c) 2000-2018 the FFmpeg developers
built with Apple LLVM version 10.0.0 (clang-1000.11.45.5)
configuration: --prefix=/usr/local/Cellar/ffmpeg/4.1 --enable-shared --enable-pthreads --enable-version3 --enable-hardcoded-tables --enable-avresample --cc=clang --host-cflags= --host-ldflags= --enable-ffplay --enable-gpl --enable-libmp3lame --enable-libopus --enable-libsnappy --enable-libtheora --enable-libvorbis --enable-libvpx --enable-libx264 --enable-libx265 --enable-libxvid --enable-lzma --enable-opencl --enable-videotoolbox
libavutil 56. 22.100 / 56. 22.100
libavcodec 58. 35.100 / 58. 35.100
libavformat 58. 20.100 / 58. 20.100
libavdevice 58. 5.100 / 58. 5.100
libavfilter 7. 40.101 / 7. 40.101
libavresample 4. 0. 0 / 4. 0. 0
libswscale 5. 3.100 / 5. 3.100
libswresample 3. 3.100 / 3. 3.100
libpostproc 55. 3.100 / 55. 3.100
Guessed Channel Layout for Input Stream #0.0 : stereo
Input #0, wav, from 'yA-FCxFQNHg.wav':
Metadata:
encoder : Lavf58.20.100
Duration: 00:17:27.06, bitrate: 1536 kb/s
Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 48000 Hz, stereo, s16, 1536 kb/s
Stream mapping:
Stream #0:0 -> #0:0 (pcm_s16le (native) -> pcm_s16le (native))
Press [q] to stop, [?] for help
Output #0, wav, to 'result-yA-FCxFQNHg.wav':
Metadata:
ISFT : Lavf58.20.100
Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 16000 Hz, mono, s16, 256 kb/s
Metadata:
encoder : Lavc58.35.100 pcm_s16le
size= 28125kB time=00:15:00.00 bitrate= 256.0kbits/s speed=1.02e+03x
video:0kB audio:28125kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.000271%
Loading model from file /Users/Volodymyr/Projects/deepspeech/models/output_graph.pb
TensorFlow: v1.11.0-9-g97d851f04e
DeepSpeech: unknown
Warning: reading entire model file into memory. Transform model file into an mmapped graph to reduce heap usage.
2018-12-14 17:42:03.121170: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Loaded model in 0.5s.
Loading language model from files /Users/Volodymyr/Projects/deepspeech/models/lm.binary /Users/Volodymyr/Projects/deepspeech/models/trie
Loaded language model in 3.17s.
Running inference.
Building top 20 keywords...
{'communicate', 'government', 'repetition', 'terrorism', 'technology', 'thinteeneighty', 'incentive', 'ponsibility', 'experience', 'upsetting', 'democracy', 'infection', 'difference', 'evidesrisia', 'legislature', 'metriamatrei', 'believing', 'administration', 'antagethetruth', 'information', 'conspiracy'}
Building summary sentence...
intellectually antagethetruth administration thinteeneighty understanding metriamatrei shareholders evidesrisia recognizing ponsibility communicate information legislature abaddoryis technology difference conspiracy repetition experience government protecting categories mankyuses democracy campaigns primarily attackers terrorism believing happening infection seriously incentive upsetting testified fortunate questions president companies prominent actually platform massacre powerful building poblanas thinking supposed accounts murdered function unsolved perverse recently fighting opposite motional election children watching traction speaking measured nineteen repeated coverage imagined positive designed together countess greatest fourteen attacks publish brought through explain russian opinion winking somehow welcome trithis problem looking college gaining feoryhe talking ighting believe happens connect further working ational mistake diverse between ferring
Inference took 726.729s for 900.000s audio file.