

Batch Data-Fetching for GraphQL and SQL.
What is Join Monster?
A JavaScript execution layer from graphql-js to SQL for batch data-fetching between the API and the database by dynamically translating GraphQL to SQL for efficient data retrieval, all in a single batch before resolution. Simply declare the data requirements of each field in you schema. Then, for each query, Join Monster will look at what was requested, find the data requirements, fetch, and shape your data.
It is NOT a tool for automatically creating a schema for you GraphQL from your database or vice versa. You retain the freedom and power to define your schemas how you want. Join Monster simply "compiles" a GraphQL query to a SQL query based on the existing schemas. It fits into existing applications and can be seamlessly removed later or used to varying degree.
{ SELECT {
user(id: 1) { "user"."id", user: {
idEncoded "user"."first_name", idEncoded: 'MQ==',
fullName ==> "user"."last_name", ==> fullName: 'andrew carlson',
email "user"."email_address" email: 'andrew@stem.is'
} FROM "accounts" AS "user" }
} WHERE "user".id = 1 }
Why?
- Batching - Fetch all the data in a single database query. No back-and-forth round trips.
- Efficient - No over-fetching get no more than what you need.
- Maintainability - SQL is automatically generated and adaptive. No need to manually write queries or update them when the schema changes.
- Declarative - Simply define the data requirements of the GraphQL fields on the SQL columns.
- Unobtrusive - Coexists with your custom resolve functions and existing schemas. Use it on the whole tree or only in parts. Retain the power and expressiveness in defining your schema.
- GraphQL becomes the ORM - Mixing and matching sucks. With only a few additions of metadata, the GraphQL schema becomes the mapping relation.
Join Monster is a means of batch-fetching data from your SQL database. It will not prevent you from writing custom resolvers or hinder your ability to define either of your schemas.
More details on this problem are here.
Works with the Relay Spec
Great helpers for the Node Interface and automatic pagination for Connection Types. See docs.
You don't have to use Relay to paginate your API with Join Monster!
Running the Demo
$ git clone https://github.com/stems/join-monster-demo.git
$ cd join-monster-demo
$ npm install
$ npm start
# go to http://localhost:3000/graphqlExplore the schema, try out some queries, and see what the resulting SQL queries and responses look like in our custom version of GraphiQL!
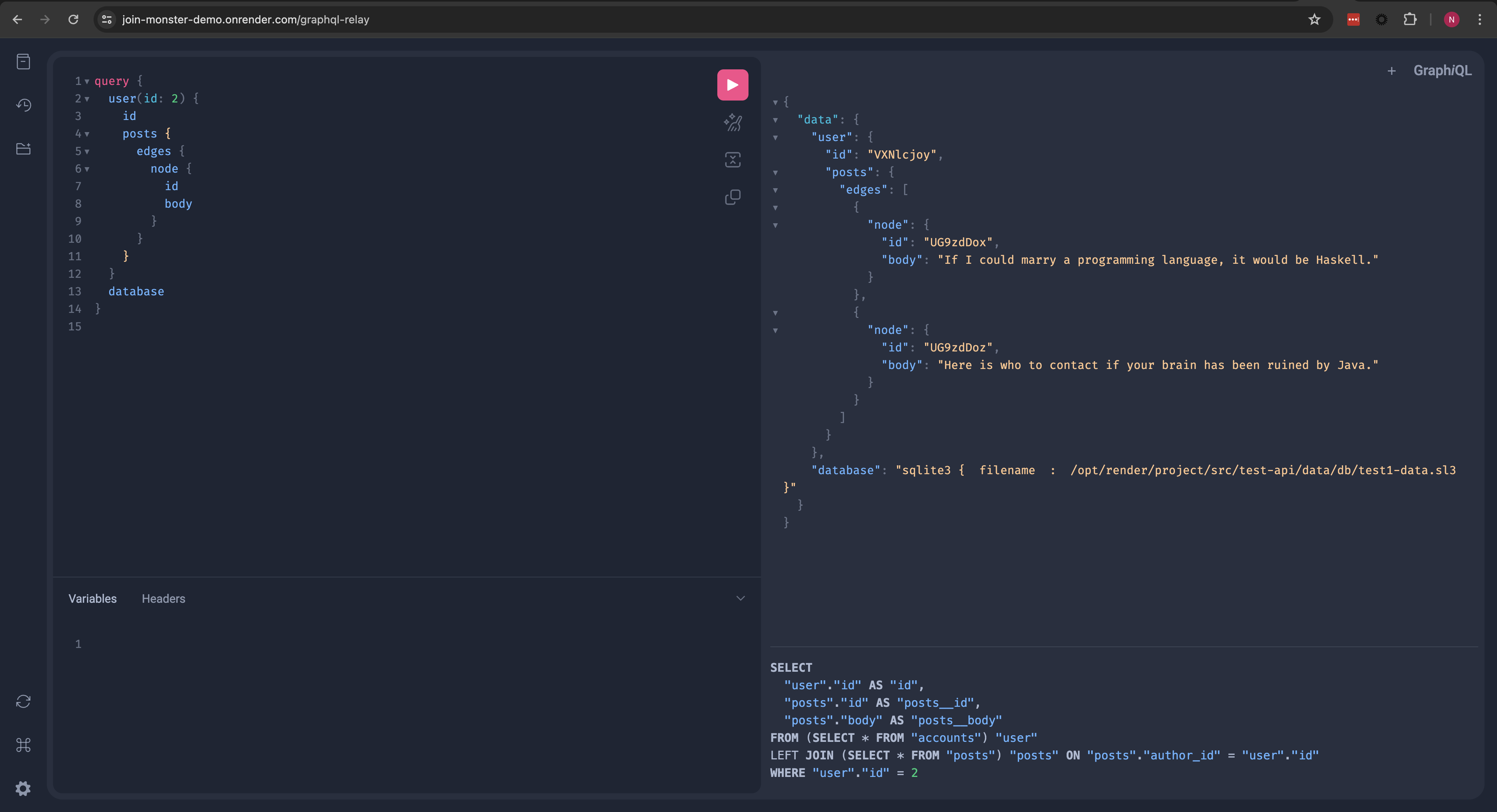
Usage
- Assign your SQL tables to their corresponding
GraphQLObjectTypes. - Add some properties to the object type, like
sqlTable,uniqueKey,sqlColumn, and more. - Link your tables in your GraphQL fields by writing some
JOINs. - Resolve any type (and all its descendants) by calling
joinMonsterin its resolver. All it needs is theresolveInfoand a callback to send the (one) SQL query to the database. Voila! All your data is returned to the resolver.
const User = new GraphQLObjectType({
name: 'User',
sqlTable: 'accounts', // the SQL table for this object type is called "accounts"
uniqueKey: 'id', // the id in each row is unique for this table
fields: () => ({
id: {
// the column name is assumed to be the same as the field name
type: GraphQLInt
},
email: {
type: GraphQLString,
// if the column name is different, it must be specified specified
sqlColumn: 'email_address'
},
idEncoded: {
description: 'The ID base-64 encoded',
type: GraphQLString,
sqlColumn: 'id',
// this field uses a sqlColumn and applies a resolver function on the value
// if a resolver is present, the `sqlColumn` MUST be specified even if it is the same name as the field
resolve: user => toBase64(user.idEncoded)
},
fullName: {
description: 'A user\'s first and last name',
type: GraphQLString,
// perhaps there is no 1-to-1 mapping of field to column
// this field depends on multiple columns
sqlDeps: [ 'first_name', 'last_name' ],
resolve: user => `${user.first_name} ${user.last_name}`
},
// got tables inside tables??
// get it with a JOIN!
comments: {
type: new GraphQLList(Comment),
// a function to generate the join condition from the table aliases
sqlJoin(userTable, commentTable) {
return `${userTable}.id = ${commentTable}.author_id`
}
}
})
})
const Comment = new GraphQLObjectType({
name: 'Comment',
sqlTable: 'comments',
uniqueKey: 'id',
fields: () => ({
// id and body column names are the same
id: {
type: GraphQLInt
},
body: {
type: GraphQLString
}
})
})
const QueryRoot = new GraphQLObjectType({
name: 'Query',
fields: () => ({
// place this user type in the schema
user: {
type: User,
// let client search for users by `id`
args: {
id: { type: GraphQLInt }
},
// how to write the where condition
where: (usersTable, args, context) => {
if (args.id) return `${usersTable}.id = ${args.id}`
},
resolve: (parent, args, context, resolveInfo) => {
// resolve the user and the comments and any other descendants in a single request and return the data!
// all you need to pass is the `resolveInfo` and a callback for querying the database
return joinMonster(resolveInfo, {}, sql => {
// knex is a query library for SQL databases
return knex.raw(sql)
})
}
}
})
})There's still a lot of work to do. Please feel free to fork and submit a Pull Request!
TODO
- Port to other JavaScript implementations of GraphQL (only the reference implementation currently supported)
- Add other SQL dialects (Microsoft SQL server, for example, uses
CROSS APPLYinstead ofLATERAL) - Much better error messages in cases of mistakes (like missing sql properties)
- Figure out a way to handle Interface and Union types
- Figure out a way to support the schema language
- Aggregate functions
NON-GOALS
- Caching: application specific cache invalidation makes this a problem we don't want to solve
- Support EVERY SQL Feature (only the most powerful subset of the most popular databases will be supported)